win11旗舰版安装WSL子系统和环境-11搭建单机Hadoop和Spark集群环境
https://blog.csdn.net/qq_40907977/article/details/108866846

mkdir /opt/java
mkdir /opt/hadoop
mkdir /opt/scala
mkdir /opt/spark
sudo tar -zxf jdk-8u281-linux-x64.tar.gz –C /opt/java


sudo nano /etc/profile
export JAVA_HOME=/opt/java/jdk1.8.0_281
export JRE_HOME=/opt/java/jdk1.8.0_281/jre
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
# 修改PATH变量,添加hadoop的bin目录进去
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
export SCALA_HOME=/opt/scala/scala-2.11.8
# export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SPARK_HOME}/bin:$PATH
export SPARK_HOME=/opt/spark/spark-3.1.1-bin-hadoop2.7
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SPARK_HOME}/bin:$PATH
export SPARK_HOME=/opt/spark/spark-3.1.1-bin-hadoop2.7
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SPARK_HOME}/bin:$PATH

hadoop需要ssh免密登陆等功能,因此先安装ssh。
sudo apt-get install ssh
sudo apt-get install rsync

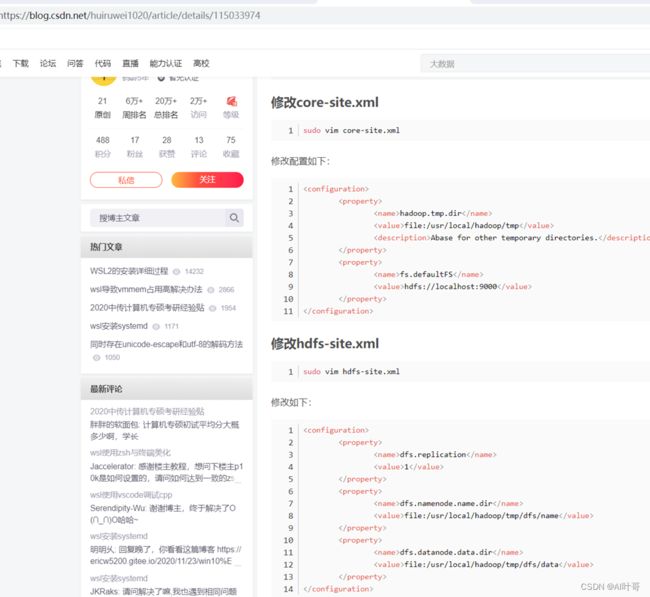
修改解压后的目录下的子目录文件 etc/hadoop/core-site.xml
linuxidc@linuxidc:/opt/hadoop/hadoop-2.7.7/etc/hadoop$ sudo nano core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>

![]()
设置免密登陆
linuxidc@linuxidc:~/www.linuxidc.com$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
Generating public/private rsa key pair.Your identification has been saved in /home/linuxidc/.ssh/id_rsa.Your public key has been saved in /home/linuxidc/.ssh/id_rsa.pub.The key fingerprint is:SHA256:zY+ELQc3sPXwTBRfKlTwntek6TWVsuQziHtu3N/6L5w linuxidc@linuxidcThe key's randomart image is:+---[RSA 2048]----+| . o.*+. .|| + B o o.|| o o =o+.o|| B..+oo=o|| S.*. ==.+|| +.o .oo.|| .o.o... || oo .E .|| .. o==|+----[SHA256]-----+
linuxidc@linuxidc:~/www.linuxidc.com$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
linuxidc@linuxidc:~/www.linuxidc.com$ chmod 0600 ~/.ssh/authorized_keys
使用命令:ssh localhost 验证是否成功,如果不需要输入密码即可登陆说明成功了。
linuxidc@linuxidc:~/www.linuxidc.com$ ssh localhost
Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 5.4.0-999-generic x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage * Canonical Livepatch is available for installation. - Reduce system reboots and improve kernel security. Activate at: https://ubuntu.com/livepatch188 个可升级软件包。0 个安全更新。Your Hardware Enablement Stack (HWE) is supported until April 2023.Last login: Sat Nov 30 23:25:35 2019 from 127.0.0.1
![]()
接下来需要验证Hadoop的安装a、格式化文件系统
linuxidc@linuxidc:/opt/hadoop/hadoop-2.7.7$ bin/hdfs namenode –format
19/11/30 23:29:06 INFO namenode.NameNode: STARTUP_MSG:/************************************************************STARTUP_MSG: Starting NameNodeSTARTUP_MSG: host = linuxidc/127.0.1.1STARTUP_MSG: args = [-format]STARTUP_MSG: version = 2.7.7…
b、启动Namenode和Datanode
linuxidc@linuxidc:/opt/hadoop/hadoop-2.7.7$ sbin/start-dfs.sh
Starting namenodes on [localhost]localhost: starting namenode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-linuxidc-namenode-linuxidc.outlocalhost: starting datanode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-linuxidc-datanode-linuxidc.outStarting secondary namenodes [0.0.0.0]The authenticity of host ‘0.0.0.0 (0.0.0.0)’ can’t be established.ECDSA key fingerprint is SHA256:OSXsQK3E9ReBQ8c5to2wvpcS6UGrP8tQki0IInUXcG0.Are you sure you want to continue connecting (yes/no)? yes0.0.0.0: Warning: Permanently added ‘0.0.0.0’ (ECDSA) to the list of known hosts.0.0.0.0: starting secondarynamenode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-linuxidc-secondarynamenode-linuxidc.out
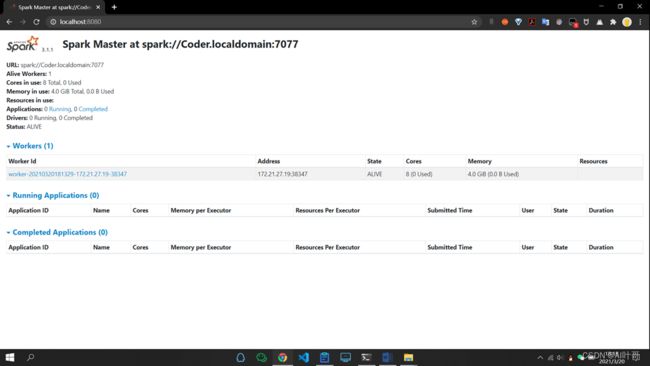
c、浏览器访问http://localhost:50070


![]()
3、Scala安装:
sudo tar zxf scala-2.11.8.tgz -C /opt/scala
4、安装spark
将spark放到某个目录下,此处放在/opt/spark使用命令:tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz 解压缩即可
sudo tar -zxf spark-2.4.4-bin-hadoop2.7.tgz -C /opt/spark
配置配置spark-env.sh
进入到spark/conf/
linuxidc@linuxidc:/opt/spark/spark-2.4.4-bin-hadoop2.7/conf$ sudo nano spark-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_231export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.7.7/etc/hadoopexport SPARK_HOME=/opt/spark/spark-2.4.4-bin-hadoop2.7export SCALA_HOME=/opt/scala/scala-2.11.8export SPARK_MASTER_IP=127.0.0.1export SPARK_MASTER_PORT=7077export SPARK_MASTER_WEBUI_PORT=8099export SPARK_WORKER_CORES=3export SPARK_WORKER_INSTANCES=1export SPARK_WORKER_MEMORY=5Gexport SPARK_WORKER_WEBUI_PORT=8081export SPARK_EXECUTOR_CORES=1export SPARK_EXECUTOR_MEMORY=1Gexport LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native

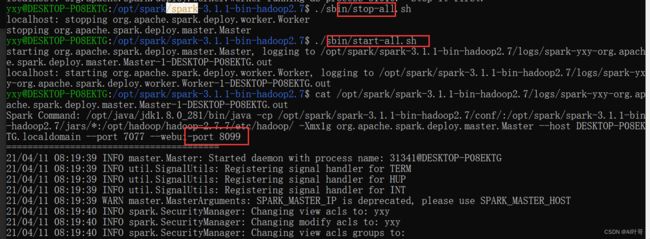


Java,Hadoop等具体路径根据自己实际环境设置。启动bin目录下的spark-shell
可以看到已经进入到scala环境,此时就可以编写代码啦。spark-shell的web界面



https://blog.csdn.net/huiruwei1020/article/details/115033974

WSL搭建Hadoop与Spark环境

查看hadoop页面

浏览器访问http://localhost:50070


YARN单机配置试过没必要



8099