爬虫翻页技巧的四种方法
我先说说我接触过的四种
第一种
第一种也是最简单的一种,就是在url里。只要找到规律循环就行

for page in range(1,6):
print('************************************正在爬取第{}*********************************'.format(page))
url = 'https://www.ku6.com/video/feed?pageNo={}&pageSize=40&subjectId=76'.format(page)
第二种
这种也比较简单
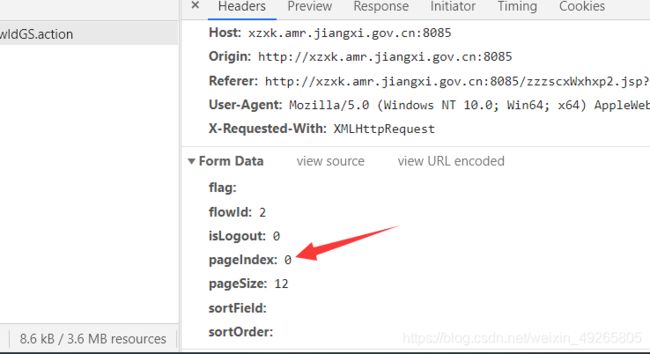
他就是翻页参数在变,其他的不变。
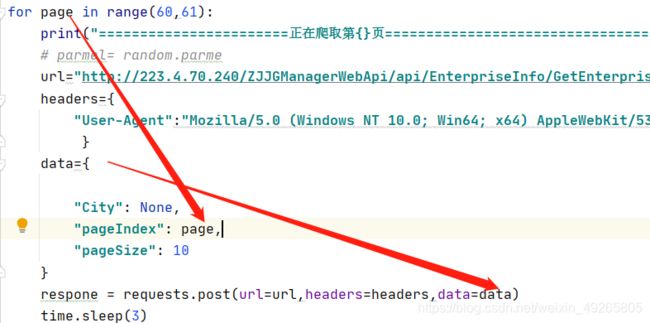
直接带进去请求就行,就可以实现翻页。
第三种
这种还是比较恶心的
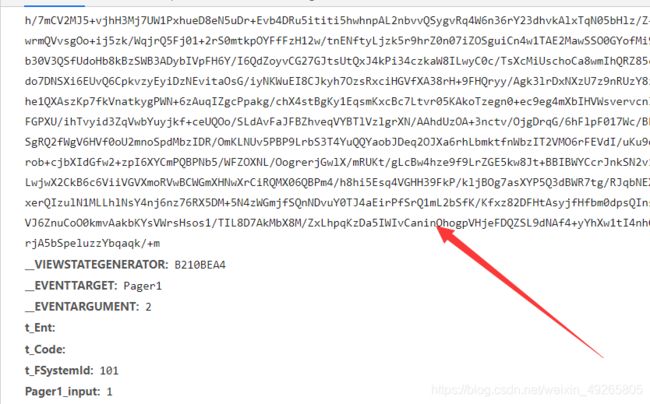
这一大堆都是变动的,一般你要翻页的话,他这参数都在源码里

首先获取这些参数,然后再带进代码中,就可以实现翻页了。
2021-08-16补
毕业满一年了,一年内换了三家公司,唉,人生,

这种没有给出总页数,你点击到第四页,又加载几页。
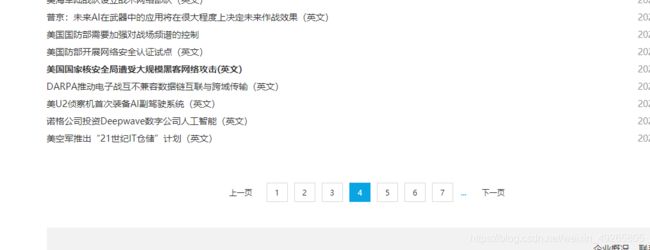
处理方法时。在提取数据时,顺带把每页页数的url提取。然后进行循环,在scrapy中是这样的用法,你可以自己修改一下,

最下面三行,可自己修改
今天就说这么多,记得关好啊。

关注公众号获取更多信息,以及代码。