个人学习日志——树莓派实时人脸识别项目
这是我运行的第一个项目,源代码来自于GitHub。第一次接触树莓派,python编程
学习目标:
1、了解树莓派的python基础知识
2、了解程序如何运行
3、了解程序的框架
4、如何调用接口
硬件:树莓派4B csi500W摄像头

环境:树莓派官方系统 python3 opencv
参考链接:
1、【创客实战训练营】树莓派使用OpenCV实现简单人脸识别_哔哩哔哩_bilibili
2、实时人脸识别:一个端到端项目 - Hackster.io(主要参考)
3、【opencv】树莓派上OpenCV-Face-Recognition人脸识别配置_BHY_的博客-CSDN博客
4、GitHub - Mjrovai/OpenCV-Face-Recognition:使用OpenCV和Python的实时人脸识别项目
5、用树莓派实现实时的人脸检测 | 树莓派实验室 (nxez.com)
环境已按照哔哩哔哩中教程配置完毕
捕获将由PiCam生成的视频流,并以BGR颜色和灰色模式显示两者
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
cap.set(3,640) #设置宽
cap.set(4,480) #设置高
while(True):
ret, frame = cap.read()
frame = cv2.flip(frame, 1) #反转摄像头
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', frame)#BGR模式
cv2.imshow('gray', gray)#灰色窗口
k = cv2.waitKey(30) & 0xff
if k == 27: # 摁下ESC关闭窗口(ESC的ascll码为27)
break
cap.release()
cv2.destroyAllWindows()原作者摄像头是反的,将frame=cv2.flip(frame,-1)中的-1改为1
我尝试将灰色窗口改为其他颜色,都报错
这个段代码运行很顺利,没有报错

人脸检测
import numpy as np
import cv2
faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')#加载分类器路径和文件
cap = cv2.VideoCapture(0)
cap.set(3,640) # set Width
cap.set(4,480) # set Height
while True:
ret, img = cap.read()
img = cv2.flip(img, 1)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.2,#表示每次图像尺寸减小的比例
minNeighbors=5, #表示一个目标至少要被检测5次才会被认定为人脸
minSize=(20, 20), #目标最小尺寸
)
for (x,y,w,h) in faces:#如果检测到人脸返回方框
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)#更改此函数数据可改变方框的大小其实位置颜色
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
cv2.imshow('video',img)
k = cv2.waitKey(30) & 0xff
if k == 27: # press 'ESC' to quit
break
cap.release()
cv2.destroyAllWindows()此处要注意调用了 Cascades/haarcascade_frontalface_default.xml文件,需要把该文件与源程序放在一个文件夹中(指定路径也可以)。该文件得到作者的GitHub中下载。
opencv的分类器GitHub地址:
opencv/data/haarcascades at master · opencv/opencv · GitHub https://github.com/opencv/opencv/tree/master/data/haarcascades
https://github.com/opencv/opencv/tree/master/data/haarcascades

cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)更改此函数数据可改变方框的大小其实位置颜色
可以顺利运行,但我发现个有意思的事情--------------------------这个识别会将我的耳朵也识别成人脸
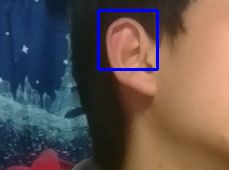 哈哈哈啊哈
哈哈哈啊哈
发现运行人脸眼睛和嘴巴时,特别的慢,第一次得加载个两分钟的样子。
人脸识别
1、人脸采集
将GitHub中的haarcascade_frontalface_default.xml放在程序所在的文件夹
在本程序文件夹创建一个dataset文件夹,如果要创建其他名的文件夹,则需将文件中相应的文件名做出更改
import cv2
import os
cam = cv2.VideoCapture(0)
cam.set(3, 640) # set video width
cam.set(4, 480) # set video height
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 对于每个人,输入一个数字人脸 ID
face_id = input('\n enter user id end press ==> ')
print("\n [INFO] Initializing face capture. Look the camera and wait ...")
# 初始化单个采样面计数
count = 0
while(True):
ret, img = cam.read()
img = cv2.flip(img, 1) # flip video image vertically
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img, (x,y), (x+w,y+h), (255,0,0), 2)
count += 1
# 将捕获的图像保存到数据集文件夹中
cv2.imwrite("dataset/User." + str(face_id) + '.' + str(count) + ".jpg", gray[y:y+h,x:x+w])#文件夹名在此处
cv2.imshow('image', img)
k = cv2.waitKey(100) & 0xff # 摁esc退出
if k == 27:
break
elif count >= 30: # 取30张人脸样本并停止视频
break
# 做一些清理
print("\n [INFO] Exiting Program and cleanup stuff")
cam.release()
cv2.destroyAllWindows() 输入只能为0,1,2,3,4,5分别对应5个人脸
运行后输入数字就可以看到dataset中有30张黑白人脸照片
2、训练opencv识别器
得安装确认 Rpi 上是否安装了 PIL 库。如果没有,请在终端中运行以下命令
pip install pillow建立名为 trainer文件夹用来存放训练结果
import cv2
import numpy as np
from PIL import Image
import os
# 人脸图像数据库的路径
path = 'dataset'
recognizer = cv2.face.LBPHFaceRecognizer_create()
detector = cv2.CascadeClassifier("haarcascade_frontalface_default.xml");
# 用于获取图像和标签数据的函数
def getImagesAndLabels(path):
imagePaths = [os.path.join(path,f) for f in os.listdir(path)]
faceSamples=[]
ids = []
for imagePath in imagePaths:
PIL_img = Image.open(imagePath).convert('L') # 将其转换为灰度
img_numpy = np.array(PIL_img,'uint8')
id = int(os.path.split(imagePath)[-1].split(".")[1])
faces = detector.detectMultiScale(img_numpy)
for (x,y,w,h) in faces:
faceSamples.append(img_numpy[y:y+h,x:x+w])
ids.append(id)
return faceSamples,ids
print ("\n [INFO] Training faces. It will take a few seconds. Wait ...")
faces,ids = getImagesAndLabels(path)
recognizer.train(faces, np.array(ids))
# 将模型保存到 trainer/trainer.yml 中
recognizer.write('trainer/trainer.yml') # recognizer.save函数在 Mac 上工作,但在 Pi 上不起作用
# 打印经过训练的面孔数量并结束程序
print("\n [INFO] {0} faces trained. Exiting Program".format(len(np.unique(ids))))执行完人脸采样必须执行训练opencv识别器。
3、识别器
import cv2
import numpy as np
import os
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('trainer/trainer.yml')
cascadePath = "haarcascade_frontalface_default.xml"
faceCascade = cv2.CascadeClassifier(cascadePath);
font = cv2.FONT_HERSHEY_SIMPLEX
#启动式 ID 计数器
id = 0
# id名称
names = ['None', 'Marcelo', 'Paula', 'Ilza', 'Z', 'W']
# 初始化并开始实时视频捕获
cam = cv2.VideoCapture(0)
cam.set(3, 640) # set video widht
cam.set(4, 480) # set video height
# 定义要识别为人脸的最小窗口大小
minW = 0.1*cam.get(3)
minH = 0.1*cam.get(4)
while True:
ret, img =cam.read()
img = cv2.flip(img, 1)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale( #faces的值为人脸的坐标
gray,
scaleFactor = 1.2,
minNeighbors = 5,
minSize = (int(minW), int(minH)),
)
for(x,y,w,h) in faces:
cv2.rectangle(img, (x,y), (x+w,y+h), (0,255,0), 2)#显示方框
id, confidence = recognizer.predict(gray[y:y+h,x:x+w])#捕获人脸返回所在位置
# 检查匹配度是否小于它们 ,100 ==>“0”的匹配度
if (confidence < 100):
id = names[id]
confidence = " {0}%".format(round(100 - confidence))#显示百分比匹配度
else:
id = "unknown"#否则输出不认识
confidence = " {0}%".format(round(100 - confidence))#显示百分比匹配度
cv2.putText(img, str(id), (x+5,y-5), font, 1, (255,255,255), 2)#显示id名
cv2.putText(img, str(confidence), (x+5,y+h-5), font, 1, (255,255,0), 1) #显示匹配度
cv2.imshow('camera',img)
k = cv2.waitKey(10) & 0xff # Press 'ESC' for exiting video
if k == 27:
break
# 做一些清理
print("\n [INFO] Exiting Program and cleanup stuff")
cam.release()
cv2.destroyAllWindows()id0对应的是None,id1对应的是marcelo以此内推,可以改变。


识别度小于百分之0则会输出unknown。
修改为程序添加功能
将陌生人框为红色
程序稍微修改下,将不认识的人用红色方框框出。
for(x,y,w,h) in faces:
id, confidence = recognizer.predict(gray[y:y+h,x:x+w])
# 检查匹配度是否小于它们 ,100 ==>“0”的匹配度
if (confidence < 100):
id = names[id]
confidence = " {0}%".format(round(100 - confidence))#显示百分比匹配度
cv2.rectangle(img, (x,y), (x+w,y+h), (0,255,0), 2)#显示绿色方框
else:
id = "unknown"#否则输出不认识
confidence = " {0}%".format(round(100 - confidence))#显示百分比匹配度
cv2.rectangle(img, (x,y), (x+w,y+h), (0,0,255), 2)#显示红色方框
实现终端输出人脸数量
思路:在循环开始时定义一个整型变量dex初值为0,只要检测到人dex就加1,一次循环一次就输出一次。

import cv2
import numpy as np
import os
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('trainer/trainer.yml')
cascadePath = "haarcascade_frontalface_default.xml"
faceCascade = cv2.CascadeClassifier(cascadePath);
font = cv2.FONT_HERSHEY_SIMPLEX
# 启动式 ID 计数器
id = 0
# id名称
names = ['None', 'LFM', 'LJ', 'Ilza', 'Z', 'W']
# 初始化并开始实时视频捕获
cam = cv2.VideoCapture(0)
cam.set(3, 640) # set video widht
cam.set(4, 480) # set video height
# 定义要识别为人脸的最小窗口大小
minW = 0.1 * cam.get(3)
minH = 0.1 * cam.get(4)
while True:
dex1 = 0#定义熟人计数变量
dex2 = 0#定义陌生人计数变量
ret, img = cam.read()
img = cv2.flip(img, 1)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale( # faces的值为人脸的坐标
gray,
scaleFactor=1.2,
minNeighbors=5,
minSize=(int(minW), int(minH)),
)
for (x, y, w, h) in faces:
id, confidence = recognizer.predict(gray[y:y + h, x:x + w]) # 捕获人脸返回所在位置
# 检查匹配度是否小于它们 ,100 ==>“0”的匹配度
if (confidence < 100):
id = names[id]
confidence = " {0}%".format(round(100 - confidence)) # 显示百分比匹配度
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2) # 显示方框
dex1 += 1#熟人加一
else:
dex2 += 1#陌生人加一
id = "unknown" # 否则输出不认识
confidence = " {0}%".format(round(100 - confidence)) # 显示百分比匹配度
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2) # 显示方框
cv2.putText(img, str(id), (x + 5, y - 5), font, 1, (255, 255, 255), 2) # 显示id名
cv2.putText(img, str(confidence), (x + 5, y + h - 5), font, 1, (255, 255, 0), 1) # 显示匹配度
cv2.imshow('camera', img)
print("'熟人'{}个,'陌生人'{}个",format(dex1), format(dex2))#输出检测检测到的人脸个数
k = cv2.waitKey(10) & 0xff # Press 'ESC' for exiting video
if k == 27:
break
# 做一些清理
print("\n [INFO] Exiting Program and cleanup stuff")
cam.release()
cv2.destroyAllWindows()运行了一下都正常,就是树莓派的那个软件里显示不了中文
没毛病,也可以吧输出换成别的
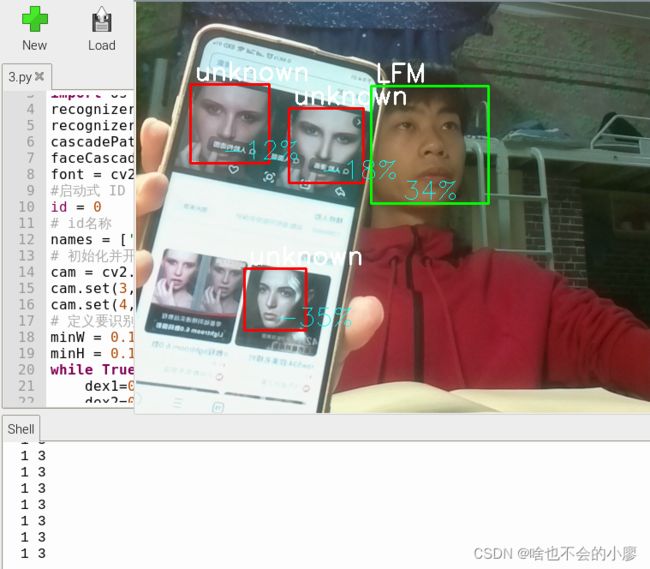
将我的两个室友都会识别成我,不会显示unknown,准确度太低了,采集照片的多少也与人脸识别没啥太多关系,但可以通过调匹配度来控制人物的识别,但也没有太大的提升。
学习总结
树莓派的基本配置,了解了python程序的内部结构,函数库的安装,函数库的使用。在此次项目中遇到了各种大大小小的问题,还好网上都能找到解决方案。