论文解读:知识增强的预训练模型简介
©NLP论文解读 原创•作者 | 杨健

专栏系列概览
该专栏主要介绍自然语言处理领域目前比较前沿的领域—知识增强的预训练语言模型。通过解读该主题具备代表性的论文以及对应的代码,为大家揭示当前最新的发展状况。为了能够和大家更好的分享自己的收获,笔者将遵循下面几个原则。
1、理论讲解尽量深入浅出,通过举例子或者大白话讲解论文,而非仅针对原文翻译。
2、针对论文中一些重要的术语,适时的做出解释。
3、理论和实践相结合,除了理论讲解,还会加入部分重要代码讲解。并且分享个人认为重要的一些工程技巧。

知识增强的预训练模型
工欲善其事必先利其器。今天的文章主要介绍 是什么、它的背景知识以及分类。后续的文章将进一步深入,详细介绍每一类知识增强的预训练模型。
从哪里来
自从神经网络成为主流以来,自然语言理解等任务大多基于神经网络为各个下游场景单独设计模型。然而这类模型仅能够适用于单一下游任务,通用性不足。
相比自然语言理解领域,由于图像处理领域拥有大量的有标签数据,研究人员利用迁移学习的思想,在数年前就已经能训练出具备一般性图像特征的大规模预训练模型。
然而,一方面自然语言处理领域缺少足够的标注数据,另一方面循环神经网络架构也遭受梯度爆炸的困扰,使得该领域的大规模预训练模型迟迟未能出现。
Transformer的出现为解决这一问题带来了希望,一方面模型通过自注意力结构和残差链接解决了循环神经网络架构梯度爆炸的问题,从而使模型得以堆叠多层神经网络,另一方面通过引入自监督的预训练任务,也解决了标注数据不足的问题。
基于Transformer的BERT和GPT模型更是在当时横扫了各大榜单,在各个下游任务的表现远超为特定任务而设计的模型,其中BERT模型更是成为了自然语言理解发展过程中的里程碑。
在这一背景下,国内外提出了各种预训练语言模型,比如国外的RoBERTa、XLNet、T5、BART,国内智源提出的CPM、华为的盘古模型、阿里的M6以及百度的ERNIE等等。
笔者在下文也会介绍预训练语言模型的分类以及各自的特点。
到哪里去
深度学习技术凭借神经网络的分布式表示能力和层次结构泛化能力,实现了对大规模数据的学习和利用。
基于深度学习的预训练模型能够从大规模无监督数据中学习蕴含在文本中词法、语法、语义等信息,在自然语言领域中的下游任务中取得了重大突破。
然而预训练模型也面临着以下的问题,一是预训练模型基于统计的方法建模,根据共现信息学习文本中实体的隐式关联,这造成了预训练模型不具备深度理解和逻辑推理的能力。
其次,受到训练数据长尾分布的影响,预训练模型鲁棒性差,容易受到攻击,并被别有用心的人恶意使用。此外,预训练模型缺乏常识知识,阻碍了预训练模型在实际应用场景的大规模推广。
知识能为预训练模型提供更全面丰富的实体语义和实体关联信息,通过提供常识和领域知识,克服训练数据长尾分布的限制,增强预训练模型的鲁棒性。
不仅如此,符号知识如知识图谱,以三元组的形式表示,具有明确的语义,为知识如何在使用场景中发挥作用引入了可解释性。
在这个背景下,自然语言处理领域涌现出了许多知识与预训练模型想结合的研究工作,尝试为预训练模型注入知识,从而更好将预训练模型应用于知识驱动和语义理解任务,这类模型也被称之为知识增强的预训练模型。
前行的途径
什么才算是知识,如何定义知识呢?给定知识,又应该如何注入到预训练模型之中实现性能的提高呢?
维基百科将知识定义为对某个主题确信的认识,并且这些认识拥有潜在的能力为特定目的而使用。Bloom等人[1]将知识分为四大类,分别是事实性知识、概念性知识、程序性知识和元认知知识。
其中事实性知识指描述客观事物的术语知识和具体细节及要素的知识,如事件、地点、人物、日期等;
概念性知识指一个整体结构基本要素间的关系,包括类别与分类的知识,原理与概括的知识,理论、模式和结构的知识;
程序性知识是指导行动的知识,一般与具体学科相关联,包括学科技能和算法知识、学科技术与方法知识、何时适当使用程序的知识;
元认知知识强调自我的主动性,是对自我认知和认知任务的知识。
从表现形式上分,则可以分为显性的符号知识和隐性的模型和向量知识。比如知识图谱、语言知识这一类通过三元组和语法树等方式表现的知识,就是显性的符号知识。
我们知道,针对对文本进行预训练获得的模型如BERT、通过对三元组使用Trans系列的模型(TransE、TransR等)生成的向量,都携带着语义信息,然而这类知识不如符号知识的直观性强,我们将其归类为隐性知识。这一系列主要介绍基于显性知识增强的模型。
考虑到符号知识主要以字符串的形式存在,而预训练模型则基于神经网络。对符号知识的表示学习就成为了架接两者的桥梁。
为此,大多数知识增强的预训练模型往往使用图神经网络、知识图谱的表示学习方法,如基于张量或者平移的模型、又或者Transformer对符号知识编码,将其转换为表示向量(embedding)。
其次,知识的注入需要考虑预训练的特性,注入的方法大多从预训练的语料、模型采用的预训练任务、模型结构、擅长的场景等角度综合考虑。
以清华提出的ERNIE和KnowBERT为例,两者都事先针对知识图谱进行表示学习。由于两者都采用BERT作为基础模型,就仍然使用Transformer的架构作为编码器编码知识向量,并且为了能够和BERT在预训练期间所使用的预训练任务保持一致,这两个模型都使用预测经过掩码的实体词作为预训练任务,以最大限度的利用模型已习得的能力。
再比如,BERT模型更擅长于语言理解任务,而GPT系列更擅长于生成任务,那么对于生成场景,为了让模型生成具备常识的内容,就需要选择使用自回归方式进行预训练,也就是GPT这类模型作为基础模型注入知识。
而对于实体分类、关系分类这类侧重于理解能力的任务而言,选择BERT、RoBERTa则更加合适。具体的注入方式笔者将会在后续的文章中逐步介绍。

预训练语言模型的分类
对于知识增强的预训练模型而言,知识的注入和预训练模型密切相关。因此,笔者先在这部分对各类预训练模型做一个简单的介绍。
预训练模型的分类方式有多种,推荐阅读综述论文[2-3]。笔者更倾向于从模型使用的架构来分类,因为采用不同的架构会影响模型能够适用的场景,这种分类方式更具有实践意义。
从这一个角度,可以将其分为三类,分别是采用Transformer的encoder架构、采用decoder架构、以及encoder-decoder架构的预训练模型。第一类的代表模型有BERT、RoBERTa,第二类代表模型则是GPT系列,最后一类的代表模型则有T5、BART等。
事实上,encoder和decoder架构之间的差异仅仅在于是否适用了掩码矩阵,decoder架构适用掩码矩阵实现了下文的遮挡。
采用encoder架构的预训练模型由于在预训练阶段就看到了上下文信息,更擅长于理解型的任务,然而对于无法看到下文信息的应用场景而言,由于和预训练阶段的训练范式不一致,效果就会大打折扣。采用decoder架构仅仅利用上文预测,虽然能够利用的信息更少,但适用的场景更多。
而且,通过扩大参数量和训练语料,这类模型的理解能力也不弱于第一类模型。最近一篇基于Prompt的论文也证明了GPT模型具有很强的理解能力[4],笔者更倾向于这类模型。
最后一类模型则是采用挖取一小段文本(span),打乱文字顺序等方式来避免下文的泄露,如T5在encoder虽然能看到上下文,但是无法看到被挖取的部分文本,而这部分文本则需要decoder来预测。
这类模型能够同时胜任语言理解和生成任务,但不足之处就是由于需要编码器和解码器,参数是前两类模型的两倍。

知识增强的预训练模型分类
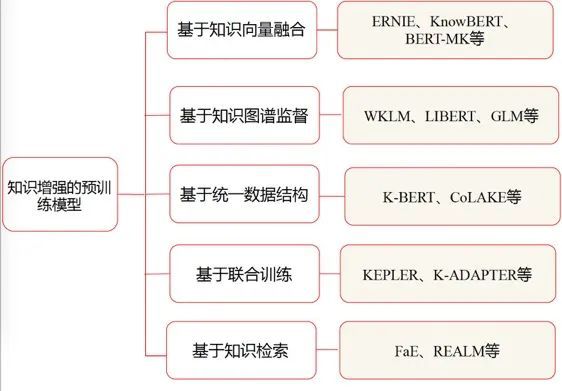
知识增强的预训练模型可以从注入的知识以及粒度、以及注入的方法、应用场景等角度分类。为了让大家更具启发,笔者在这里从知识的注入方法进行分类,将其分为基于知识向量融合的模型、基于知识图谱监督的模型、基于统一知识和文本结构的模型以及基于联合训练的模型。
基于知识向量融合的模型对符号知识预先表示学习,然后针对文本中的指称项(mention)对象的向量和实体向量加权求和、使用自注意机制等方式融合两者。所谓指称项可以理解为某一个实体非正式的别名。
基于图谱监督的模型则是通过从知识图谱中获取实体的语义、情感等作为模型的额外特征,又或者从中选择同义、反义词等作为监督语料,使预训练模型学习显式的实体关系。基于统一结构的模型则将符号知识和文本转换为统一的结构,使用同一个编码器,大多使用Transformer进行编码。
最后一类模型则通过为知识设计额外的预训练任务实现知识的注入。
最后附上一张模型的分类图。
参考文献:
[1]Taxonomy of educational objectives
http://nancybroz.com/nancybroz/Literacy_I_files/Bloom%20Intro.doc
[2]Pre-trained models for natural language processing: A survey
https://www.researchgate.net/profile/Xipeng-Qiu/publication/340021796_Pre-trained_Models_for_Natural_Language_Processing_A_Survey/links/5e7b1a05299bf1f3873fd11a/Pre-trained-Models-for-Natural-Language-Processing-A-Survey.pdf
[3]Pre-Trained Models: Past, Present and Future
https://arxiv.org/pdf/2106.07139.pdf
[4]GPT Understands, Too
https://arxiv.org/pdf/2103.10385.pdf