集合、numpy中array数组、dataframe和list的交并补差操作
文章目录
- 集合交并补
- numpy数组array交并补
- dataframe交并补
-
- 取交集
- 并集
- 差集
- list交并补
集合交并补
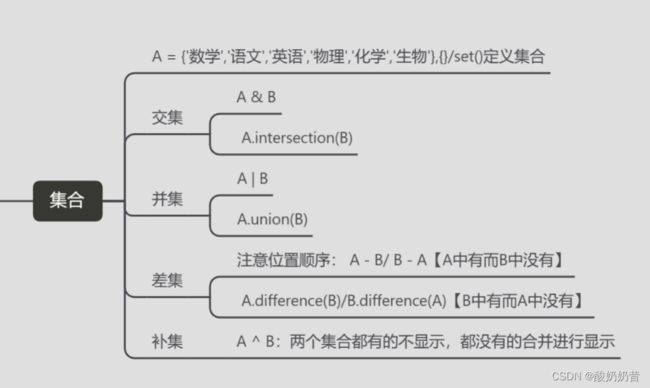
python集合的运算(交集、并集、差集、补集)
numpy数组array交并补
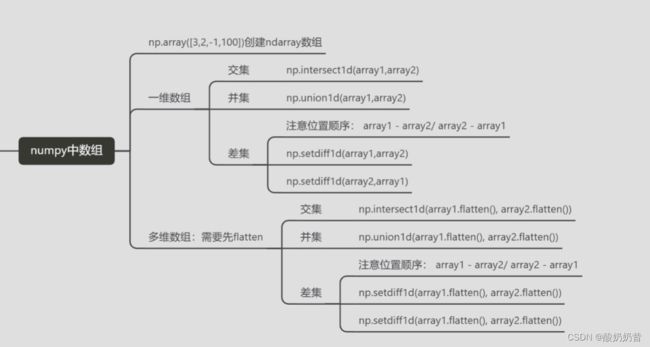
python使用numpy求两个数组的并集交集差集(图像)
dataframe交并补
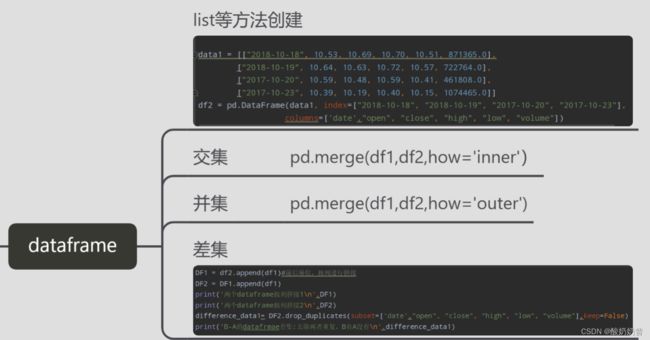
Pandas:DataFrame的交集并集补集(列标签是相同的)
取交集
import numpy as np
import pandas as pd
data = [["2017-10-18", 10.53, 10.69, 10.70, 10.51, 871365.0],
["2017-10-19", 10.64, 10.63, 10.72, 10.57, 722764.0],
["2017-10-20", 10.59, 10.48, 10.59, 10.41, 461808.0],
["2017-10-23", 10.39, 10.19, 10.40, 10.15, 1074465.0]]#ndarray
df1 = pd.DataFrame(data, index=["2017-10-18", "2017-10-19", "2017-10-20", "2017-10-23"],
columns=['date',"open", "close", "high", "low", "volume"])
data1 = [["2018-10-18", 10.53, 10.69, 10.70, 10.51, 871365.0],
["2018-10-19", 10.64, 10.63, 10.72, 10.57, 722764.0],
["2017-10-20", 10.59, 10.48, 10.59, 10.41, 461808.0],
["2017-10-23", 10.39, 10.19, 10.40, 10.15, 1074465.0]]
print(type(data1))
df2 = pd.DataFrame(data1, index=["2018-10-18", "2018-10-19", "2017-10-20", "2017-10-23"],
columns=['date',"open", "close", "high", "low", "volume"])
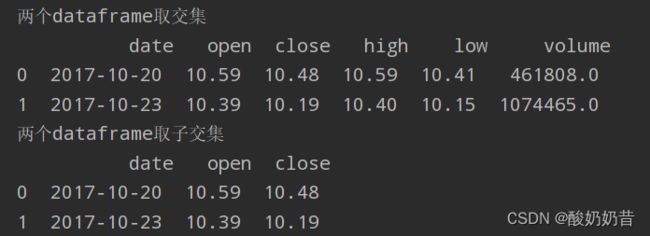
# 取交集
interaction_data = pd.merge(df1,df2,how='inner')#默认列名
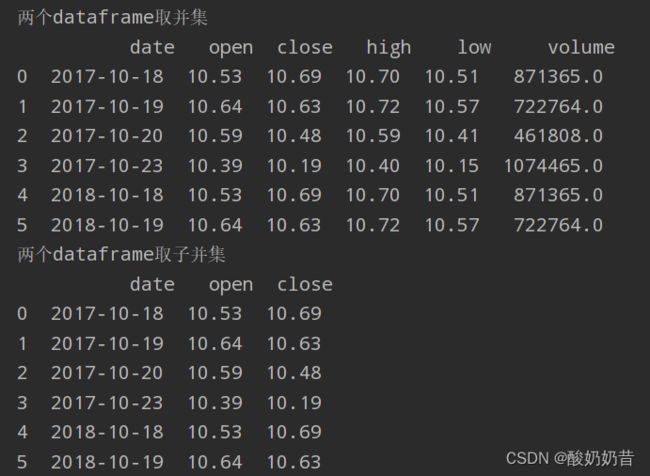
print('两个dataframe取交集\n',interaction_data)
# 取子集交集,但是其余部分也会显示成为high_x和high_y的形式,可以通过截取只取前面的一部分
interaction_data1 = pd.merge(df1,df2,on=['date',"open", "close"],how='inner')#默认列名
interaction_data1 = interaction_data1.iloc[:,0:3]#0<=x<3的列,使用loc会出错
print('两个dataframe取子交集\n',interaction_data1)
- 结果
并集
import numpy as np
import pandas as pd
data = [["2017-10-18", 10.53, 10.69, 10.70, 10.51, 871365.0],
["2017-10-19", 10.64, 10.63, 10.72, 10.57, 722764.0],
["2017-10-20", 10.59, 10.48, 10.59, 10.41, 461808.0],
["2017-10-23", 10.39, 10.19, 10.40, 10.15, 1074465.0]]#ndarray
df1 = pd.DataFrame(data, index=["2017-10-18", "2017-10-19", "2017-10-20", "2017-10-23"],
columns=['date',"open", "close", "high", "low", "volume"])
data1 = [["2018-10-18", 10.53, 10.69, 10.70, 10.51, 871365.0],
["2018-10-19", 10.64, 10.63, 10.72, 10.57, 722764.0],
["2017-10-20", 10.59, 10.48, 10.59, 10.41, 461808.0],
["2017-10-23", 10.39, 10.19, 10.40, 10.15, 1074465.0]]
print(type(data1))
df2 = pd.DataFrame(data1, index=["2018-10-18", "2018-10-19", "2017-10-20", "2017-10-23"],
columns=['date',"open", "close", "high", "low", "volume"])
#取并集
union_data = pd.merge(df1,df2,how='outer')
print('两个dataframe取并集\n',union_data)
union_data1= pd.merge(df1,df2,on=['date',"open", "close"],how='outer')#默认列名
#取并子集
union_data1 = union_data1.iloc[:,0:3]#0<=x<3的列,使用loc会出错
print('两个dataframe取子并集\n',union_data1)
差集
- 差集思想:dataframe2复制两次,新的dataframe=dataframe1+dataframe2+dataframe2,然后去重则dataframe2可以去除,dataframe1中与dataframe2重复的可以去除
import numpy as np
import pandas as pd
data = [["2017-10-18", 10.53, 10.69, 10.70, 10.51, 871365.0],
["2017-10-19", 10.64, 10.63, 10.72, 10.57, 722764.0],
["2017-10-20", 10.59, 10.48, 10.59, 10.41, 461808.0],
["2017-10-23", 10.39, 10.19, 10.40, 10.15, 1074465.0]]#ndarray
df1 = pd.DataFrame(data, index=["2017-10-18", "2017-10-19", "2017-10-20", "2017-10-23"],
columns=['date',"open", "close", "high", "low", "volume"])
data1 = [["2018-10-18", 10.53, 10.69, 10.70, 10.51, 871365.0],
["2018-10-19", 10.64, 10.63, 10.72, 10.57, 722764.0],
["2017-10-20", 10.59, 10.48, 10.59, 10.41, 461808.0],
["2017-10-23", 10.39, 10.19, 10.40, 10.15, 1074465.0]]
print(type(data1))
df2 = pd.DataFrame(data1, index=["2018-10-18", "2018-10-19", "2017-10-20", "2017-10-23"],
columns=['date',"open", "close", "high", "low", "volume"])
#取差集(从df1中过滤df2中存在的数据)
Df1 = df1.append(df2)
Df2 = Df1.append(df2)
difference_data= Df2.drop_duplicates(subset=['date',"open", "close", "high", "low", "volume"],keep=False)
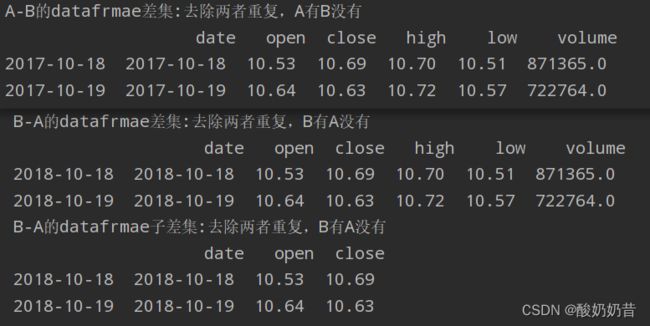
print('A-B的datafrmae差集:去除两者重复,A有B没有\n',difference_data)
DF1 = df2.append(df1)#按列进行拼接
DF2 = DF1.append(df1)
difference_data1= DF2.drop_duplicates(subset=['date',"open", "close", "high", "low", "volume"],keep=False)
print('B-A的datafrmae差集:去除两者重复,B有A没有\n',difference_data1)
difference_data2 = DF2.drop_duplicates(subset=['date',"open", "close"],keep=False)
difference_data2 = difference_data2.iloc[:,0:3]#0<=x<3的列,使用loc会出错
print('B-A的datafrmae子差集:去除两者重复,B有A没有\n',difference_data2)
- 结果
- 全部代码
import numpy as np
import pandas as pd
data = [["2017-10-18", 10.53, 10.69, 10.70, 10.51, 871365.0],
["2017-10-19", 10.64, 10.63, 10.72, 10.57, 722764.0],
["2017-10-20", 10.59, 10.48, 10.59, 10.41, 461808.0],
["2017-10-23", 10.39, 10.19, 10.40, 10.15, 1074465.0]]#ndarray
df1 = pd.DataFrame(data, index=["2017-10-18", "2017-10-19", "2017-10-20", "2017-10-23"],
columns=['date',"open", "close", "high", "low", "volume"])
data1 = [["2018-10-18", 10.53, 10.69, 10.70, 10.51, 871365.0],
["2018-10-19", 10.64, 10.63, 10.72, 10.57, 722764.0],
["2017-10-20", 10.59, 10.48, 10.59, 10.41, 461808.0],
["2017-10-23", 10.39, 10.19, 10.40, 10.15, 1074465.0]]
print(type(data1))
df2 = pd.DataFrame(data1, index=["2018-10-18", "2018-10-19", "2017-10-20", "2017-10-23"],
columns=['date',"open", "close", "high", "low", "volume"])
# 取交集
interaction_data = pd.merge(df1,df2,how='inner')#默认列名
print('两个dataframe取交集\n',interaction_data)
## 取子集交集,但是其余部分也会显示成为high_x和high_y的形式【可以通过截取只取前面的一部分】
interaction_data1 = pd.merge(df1,df2,on=['date',"open", "close"],how='inner')#默认列名
interaction_data1 = interaction_data1.iloc[:,0:3]#0<=x<3的列,但是使用loc会出错
print('两个dataframe取子交集\n',interaction_data1)
#取并集
union_data = pd.merge(df1,df2,how='outer')
print('两个dataframe取并集\n',union_data)
## 取子集并集,但是其余部分也会显示成为high_x和high_y的形式【可以通过截取只取前面的一部分】
union_data1= pd.merge(df1,df2,on=['date',"open", "close"],how='outer')#默认列名
union_data1 = union_data1.iloc[:,0:3]#0<=x<3的列,但是使用loc会出错
print('两个dataframe取子并集\n',union_data1)
#取差集(从df1中过滤df2中存在的数据)
# 思想:dataframe2复制两次,新的dataframe=dataframe1+dataframe2+dataframe2,然后去重则dataframe2可以去除,dataframe1中昱dataframe2重复的可以去除
Df1 = df1.append(df2)
Df2 = Df1.append(df2)
difference_data= Df2.drop_duplicates(subset=['date',"open", "close", "high", "low", "volume"],keep=False)
print('A-B的datafrmae差集:去除两者重复,A有B没有\n',difference_data)
DF1 = df2.append(df1)#前后座位,按列进行拼接
DF2 = DF1.append(df1)
print('两个dataframe按列拼接1\n',DF1)
print('两个dataframe按列拼接2\n',DF2)
difference_data1= DF2.drop_duplicates(subset=['date',"open", "close", "high", "low", "volume"],keep=False)
print('B-A的datafrmae差集:去除两者重复,B有A没有\n',difference_data1)
difference_data2 = DF2.drop_duplicates(subset=['date',"open", "close"],keep=False)
difference_data2 = difference_data2.iloc[:,0:3]#0<=x<3的列,但是使用loc会出错
print('B-A的datafrmae子差集:去除两者重复,B有A没有\n',difference_data2)
list交并补
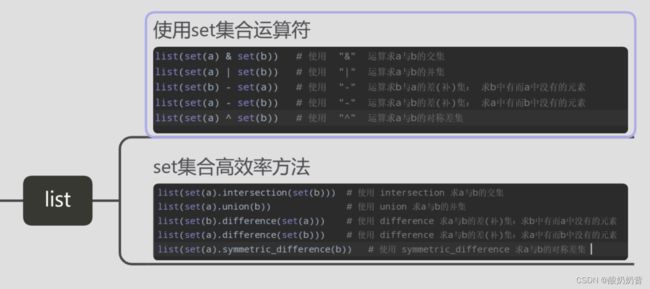
Python求两个list的交集、并集、差(补)集、对称差集的方法