论文翻译(10)--CASME2: A Database for Spontaneous Macro-Expression and Micro-Expression Spotting and Rec
CAS(ME)2:自发宏表情和微表情识别数据库
CAS(ME)2: A Database for Spontaneous Macro-Expression and Micro-Expression Spotting and Recognition
论文地址
链接:https://pan.baidu.com/s/1nBoNxh3-Y_GlG93X6o-m3A 提取码:3qob
摘要
欺骗是一种非常常见的现象,对它的检测可以对我们的日常生活有益。与其他欺骗线索相比,微表情作为一种很有前途的欺骗检测线索显示出巨大的潜力。从长视频中发现和识别微表情可能对执法人员和研究人员都有很大帮助。然而,在长视频中既包含微表情又包含宏表情的数据库仍然没有公开。为了促进这一领域的发展,我们提出了一个新的数据库,中国科学院宏表情和微表情(CAS(ME)2),它提供宏表情和微表情两个部分(A和B)。A部分包含87个长视频,包含自发宏表情和微表情。B部分包括300个裁剪的自发宏表情样本和57个微表情样本。情感标签基于动作单位(AUs)、每个面部动作的自我报告情感以及引发情感的视频的情感类型的组合。局部二进制模式(LBP)用于宏表情和微表情的检测和识别,并将结果报告为基线评估。CAS(ME)2数据库提供了长视频和裁剪的表情样本,这可能有助于研究人员开发有效的算法来识别和识别宏表情和微表情。
关键词—宏表情和微表情检测、宏表情和微表情识别、微观表情数据库、面部动作编码系统
一、介绍
人际欺骗是人类社会交往的一个常见方面。尽管人们有欺骗和被他人欺骗的经历,但众所周知,谎言很难被发现,即使对执法领域的熟练专家来说也是如此。作为一种传统的测谎系统,测谎仪是一种广泛使用的方法,因为它可以监测受试者在说谎时的觉醒导致的心率和电生理反应的不受控制的变化。然而,测谎仪的记录过程是侵入性的,受试者可能会采取对策来隐藏他们的真实想法[1]。最近,另一个可能的说谎指标,微表情,其特点是持续时间短,强度低,典型的局部运动,引起了情感计算研究人员和心理学家的注意。微表情是当个人试图隐藏自己真实的情绪时出现的快速而简短的表情,尤其是在高风险的情况下[2]、[3]。埃克曼甚至声称,微表情可能是最有希望的测谎线索[3]。
与测谎仪不同,在互动或采访过程中,可以用不显眼的摄像头捕捉到微观表情,因此,受试者可能不会意识到自己受到了监控。因此,在审讯采访环境中从视频流中自动识别微表情可以极大地帮助执法人员检测嫌疑人的通常或欺骗线索。尽管从长视频中自动识别微表情的潜力很大,但在长视频中嵌入微表情的公开数据库仍然很少。
在这篇论文中,我们首先回顾了以往关于面部表情数据库(包括常规和微表情)的构建的研究和先前研究者对面部表情的自动检测识别方面做出的努力。然后,我们根据以前的研究揭示了有希望的改进,并介绍了我们的新数据库:中国科学院宏观和微观表达数据库。在本文的第三部分,我们进行了数据库基线评估,并给出了相关结果。
论文组织如下。在第二节中,我们回顾了关于面部表情数据库的构建、先前研究者在面部表情的自动检测和识别方面所做的努力、先前使用的情绪诱导方法的分析以及CAS(ME)2的特点。第三节介绍了该数据库的基本概况,包括(情绪)启发材料和程序、编码和标记过程以及用户指南。在第4节中,进行了数据库基线评估,并给出了相关结果,而论文在第5节以讨论和结论结束。
二、相关工作
2.1以前面部表情数据库的分析
至今,许多用于从人脸中自动检测和识别情绪的方法和算法已经被提出[4]、[5]、[6]。研究人员主要关注一般的面部表情,通常被称为宏表情,很容易被注意到,通常持续1/2秒以上,最长可达4秒[7]。而微表情是那些在短时间内发生的,通常不会被注意到的表情。具体来说,微表情是当个人试图隐藏自己真实的情绪时出现的快速而简短的表情,尤其是在高风险的情况下[9],[10]。与宏表情的研究相比,微表情的检测和识别算法受到了一定的限制,这是因为微表情数据库的数量有限,尤其是在可用于自动检测微表情的包含微表情的长视频的数据库。
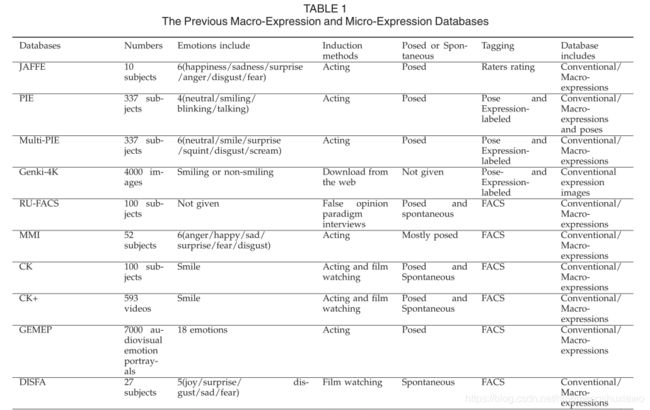
已经进行了大量关于宏观表达识别的研究。如果没有面部表情数据库的建设,这种进步是不可能的,面部表情数据库极大地促进了面部表情识别系统的发展。众多面部表情数据库,如日本女性面部表情数据库(JAFFE)[11];CMU姿势、照明和表情数据库[12]及其新版本多表情数据库[13];和根基-4K数据库[14],已经开发出来(见表1) [6],[15]。然而,这些数据库只包含代表不同情绪状态的静态面部表情图像。
静态面部表情图像比动态面部表情图像序列包含更少的面部运动信息,对表情识别更具鉴别性。因此,研究人员开始关注动态信息,并开发了几个包含动态面部表情图像序列的数据库而不是静态图像,如RU-FACS数据库[16],MMI面部表情数据库[17],Cohn-Kanade数据库(CK) [18]和GEMEP数据库[19]。
然而,这些数据库仅包括姿势表情(即,参与者被要求呈现或摆出某些面部表情,例如高兴和悲伤的表情),而不是自然表达或自发的面部表情。先前的研究表明,姿势表达可能在外观和时间上不同于自发出现的表达20。因此,包含自发面部表情的数据库将具有更大的生态有效性。
为了解决面部表情自发性的问题,Lucey等人[21]通过收集大量自发的面部表情,开发了扩展的Cohn-Kanade数据集(CK+)。然而,这个数据集只包括参与者面部表情姿势任务之间自发出现的快乐表情。Mavadati等人[22]通过收集参与者观看视频时的自发面部表情,构建了丹佛自发面部动作强度数据库,该视频旨在引发自发情绪表达和编码面部动作单位的存在、缺失和强度。最近,麦克达夫等人[23]展示了情感表情数据集(AM-FED),该数据集包含从网上招募的志愿者在线收集的自然和自发的面部表情,这些志愿者同意在观看有趣的超级碗广告时被录像。该数据库通过收集在自然环境中记录的自发表情样本来提高有效性。然而,只记录了被理解为与单一情绪状态(娱乐)相关的面部表情;没有获得关于参与者经历的自我报告。王等人[24]发表了一个新的表情数据库,自然可见和红外面部表情(NVIE),包括姿势和自发表情样本。他们还收集了自我报告的数据来分析情绪化视频的有效性,并通过分析他们的热差异来比较姿势表达和自发表达之间的差异。本研究为表情数据库的构建提供了一个很好的例子。张等人[25]最近发表了一个新的三维(3D)自发引发的面部表情的面部表情数据库,即宾汉姆顿匹兹堡四维自发表情数据库(BP4D-EARCH),该数据库是根据参与者的自我报告、天真观察者的主观评分和面部动作编码系统(FACS)进行编码的,这提高了表情编码和标记的有效性。然而,在每次任务后,只收集参与者的一般自我报告感觉,收集任务期间每个面部运动的自我报告,以排除任何可能污染数据库的非情绪运动,如擤鼻涕、吞咽唾液或转动眼睛。
2.2以前微表情数据库的分析
然而,与众多宏表情数据库相比,关注微表情的数据库很少。
 据我们所知,只发表了六个微表情数据集,每个都有不同的优缺点(见表1):USF-高清[8];波利科夫斯基的数据库[26];SMIC [27]及其继承者,SMIC [28]的扩展版本;以及CASME [29]及其继任者CASME II [30]。
据我们所知,只发表了六个微表情数据集,每个都有不同的优缺点(见表1):USF-高清[8];波利科夫斯基的数据库[26];SMIC [27]及其继承者,SMIC [28]的扩展版本;以及CASME [29]及其继任者CASME II [30]。
这些微数据库极大地促进了自动微表情识别的发展。然而,这些数据库只包括裁剪的微表情样本,不适合自动微表情点样。用于情绪标记的方法并不一致,情绪通常根据FACS、启发材料的情绪类型或两者来标记。这些方法提供了在数据库中包括一些无意义的面部运动(如擤鼻涕、吞咽唾液或转动眼睛)的可能性。
在CASME [29]和CASME II [30]中作者试图收集参与者在观看每个情感视频后的自我报告,以进行情感标注。在这个数据库中,连同FACS和情感类型的启发材料,我们收集了参与者的每个面部动作的自我报告,这在最好的程度上保证了微表情数据库的纯度。
基于微表情数据库,一些出版物试图促进微表情自动识别的发展。波利科夫斯基等人[26]采用3D梯度描述符进行微表情识别。王等[31]将灰度微表情视频片段作为三阶张量,应用判别张量子空间分析()和极限学习机方法识别微表情。然而,在DTSA的过程中,微表情所涉及的细微动作可能会丢失。Pfisteretal。[27]利用时间插值模型(TIM)和三个正交平面上的局部二进制模式(LBP-TOP) [32]提取微表情的动态纹理。王等人[33]使用独立的颜色空间来改进这项工作,他们[34]还应用鲁棒主成分分析[35]来提取关于微表情的细微运动信息。刘等[36]提出了一种简单有效的主方向平均光流特征用于微表情识别。徐等人[37]提出了面部动态图()来描述微表情实例的运动模式。王等[38]提出了用于微表情识别的稀疏张量典型相关分析。
与微表情识别的研究相比,微表情斑点的研究很少。Shreve等人[39]主要利用面部应变和密集光流来检测和区分宏观表情和微观表情。波利科夫斯基等人[26],[40]通过3D梯度描述符测量微表达的三个阶段的持续时间。Moilanen等人[41]主要使用LBP特征来获得微表达定位的时间和空间位置,但他们使用了SMIC数据库,该数据库包括裁剪的微表情样本,该样本包括从开始到偏移的微表情帧,或者CASME数据库,该数据库包括对微表情定位不太合理的视频-最短的视频仅持续0.2秒。
因此,微表情定位的研究主要受限于在长视频中包含微表情的微表情数据库的开发。据我们所知,没有公开的数据库包含长视频中的微面部表情,可用于微表情自动识别。关于从长视频中发现微表情的唯一相关研究是由Shreve [8],[39]进行的,他在一个数据库中应用了时空应变方法,该数据库包含从不同来源收集的表情样本。然而,该数据库不是公开可用的。
2.3对以往情绪诱导方法的分析
在以前构建面部表情数据库的研究中,不同类型的情感诱导方法,例如情绪表演,采用了其他操纵方法(嗅觉刺激、访谈和社会挑战)和电影观看(见表1);每种方法都有优点和缺点。
在第一种方法,情感表演(JAFFE、PIE、multiPIE和GEMEP)中,参与者或演员被要求表演某些类型的情感面部表情。这种方法总是被批评为姿势表情的启发,这种姿势表情不同于所使用的面部肌肉及其动力学的自发表情[42],[43]。例如,许多类型的自发微笑在幅度上较小,在总持续时间上较长,并且在开始和结束时间上慢于摆好姿势的微笑[43],[44]。
在第二种方法中,使用了一系列的任务(如BP4D),如引起厌恶的嗅觉刺激、访谈、引起疼痛的冷加压试验和引起愤怒的社会挑战,然后是赔偿[25]。虽然这些方法在引发自发表达方面具有相对较高的生态学有效性,但它们在引发某些情绪或表达的有效性方面存在局限性。用这些方法得出的表达式可能有不同的特征,如持续时间和强度,这使得它们之间的可比性较差。
最广泛使用的引发情绪或自发面部表情的方法是看电影(DISFA、AM-FED、SMIC、SMIC扩展版、CASME和CASMEII)。视频集具有相对较高的生态效度[45],就情感效价而言,通常优于图片。视频集是持久而动态的情感刺激,使得抑制更加困难。因此,在这个数据库的建设中采用了观看电影的方法。
2.4当前数据库的特征:CAS(ME)2
考虑到前面提到的问题,我们提出了CAS(ME)2)数据库,该数据库包括长视频中的自发宏表情和微表情(部分A)以及从开始到偏移的帧的裁剪表达式样本(部分B),用于自动宏表情和微表情定位和识别训练。该数据库的主要贡献总结如下:
该数据库是第一个在长视频中包含宏表情和微表情的公开数据库,它有助于开发从长视频流中识别微表情的算法。
所有宏表情和微表情样本都是在相同的实验条件下从相同的参与者那里收集的,这使得研究人员能够开发更有效的算法来提取能够更好地区分宏表情和微表情并比较它们的特征向量差异的特征。
宏表情和微表情之间的差异可以通过在该数据库上测试的算法来获得。
该数据库采用了FACS AUs、启发视频的情绪类型和参与者对每个表情样本的自我报告情绪的组合。在表情诱导阶段之后,参与者被要求观看记录他们面部表情的视频,并为每个表情提供一份自我报告。这个过程使我们能够排除几乎所有与情绪无关的面部运动,并获得相对纯净的表情样本。还提供了每个表情样本的自我报告情绪,它们可用于与参与者显示的情绪进行比较。
本文是我们在国际人机交互会议(2016年,HCII)上提交的论文的扩展版本[46]。不同之处在于,我们添加了嵌入在长视频中的微表情和宏表情,可用于自动微表情识别。我们还进行了自动微表情点样评估。在接下来的章节中,我们将首先描述数据库及其启发和编码过程。我们还将在此数据库上提供一些自动定位和识别的基本评估结果,作为基线性能测量。
3 CAS(ME)2数据库配置文件(profile)
CAS(ME)2数据库包含两部分:部分A和部分b。部分A由87个包含宏表情和微表情的长视频组成。使用基于外观的特征差异分析方法在该部件上测试自动宏表情和微表情检测;报告了结果。第二部分包括357个裁剪后的表情样本,包括300个宏表情和57个微表情。
这些表情是用照相机拍摄的。表情样本是从600多个引发面部运动的样本中选取的,用起始帧、顶点帧和偏移帧编码,同时标记了AUs和情感标记[30]。
为了提高情绪标签的可靠性,我们通过要求参与者回顾每个记录的面部运动并给出与每个面部运动相关的自我报告的情绪体验来获得额外的情绪标签。
选择持续时间超过500毫秒且小于4秒的宏表情包含在该数据库中[7]。还选择了最长持续时间为500毫秒的微表情。
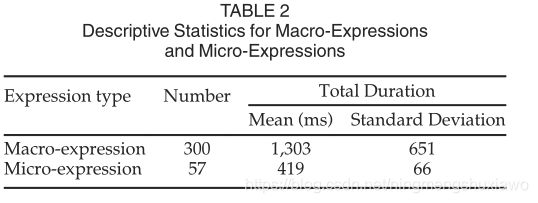
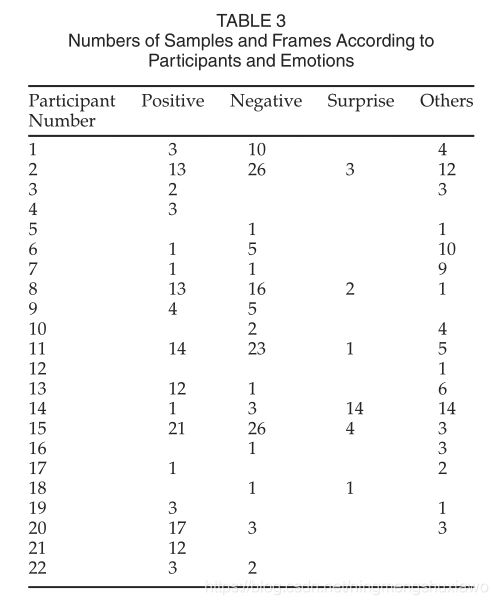
数据采集和编码过程的步骤将在以下章节中介绍。表2给出了具有不同持续时间的表情样本的描述性统计,包括300个宏表情和57个微表情,根据总持续时间来定义。图1示出了微表情(a)和宏表情(b)的例子。考虑到这些表情的强度相对较低,我们还提供了与这两种表情相对应的视频剪辑,作为补充材料来更好地说明它们的区别,可以在计算机学会数字图书馆上找到,网址为http://doi。当表情数据库存在时,根据参与者和情感类别分布表情样本也是必要的[21]、[47]、[48]。表3列出了CAS(ME)2中根据每个参与者和不同情绪类别的样本数量。
3.1参与者和启发材料
招募了22名参与者(13名女性和9名男性),平均年龄为22.59岁(标准差= 2.2),年龄范围为19-26岁。所有人都在知情的情况下同意将他们的视频图像用于科学研究。
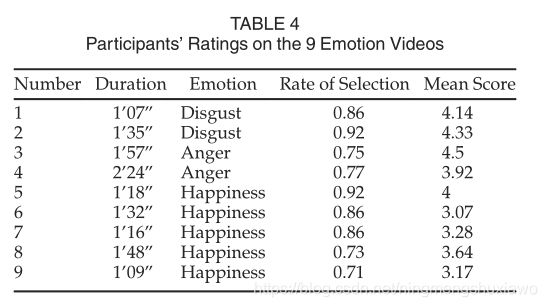
对于表情诱导材料,从20个视频中选出9个情感视频,由20个其他评分者对其诱导表情的能力进行评分。基于在以前的研究中观察到的诱导微表情的能力,在本研究中仅使用了三种类型的引发情感的情感视频(引发厌恶、愤怒和快乐的视频)。它们的长度从1分钟到大约2分30秒不等(见表4)。选择了两个引发厌恶情绪的视频、两个引发愤怒情绪的视频和五个引发快乐情绪的视频。每个情绪视频主要引发一种类型的情绪。
3.2启发程序
在启发过程中,每个参与者都坐在罗技专业C920摄像头前(每秒30帧,分辨率设置为640×480像素),它被放置在监视器后面的三脚架上,以记录参与者的正面。参与者坐在一个有两个发光二极管灯的房间里(见图2)。这九个视频集是由实验者以随机顺序呈现的。参与者被告知密切注视屏幕并保持中立的面孔。
因为微表情的启发需要强大的动机来隐藏真正经历过的情绪,所以需要动机操纵协议。在以前的研究[10]中使用的中和范式中,参与者被告知实验的目的是测试他们控制情绪表达的能力,这与他们的社会成功密切相关。参与者被告知,实验的目的是测试他们控制情绪表达的能力,这与他们的社交成功密切相关。参与者还被告知,他们的报酬将与他们的表现直接相关。为了在应用自动定位算法时减少噪音和检测损失,我们事先通知参与者避免做大的头部运动。为了确保参与者在屏幕上观看感人的电影,我们还要求参与者尽可能将眼睛盯着屏幕。
在观看了所有九个引发情绪的视频后,参与者被要求回顾他们面部的记录视频,以识别任何面部动作,并提供一份他们在每次面部动作中经历的内心感受的自我报告(当他们不确定与某个面部动作相关的情绪感受时可以回顾原始的引发情绪的视频)。这些与每个表情相关的自我感觉报告被收集起来,并作为一个单独的情绪标签系统使用,如下一节所述。只有那些被报道有情感意义的面部运动被包括在这个数据库中。
3.3编码过程
两名训练有素的FACS编码员对录像面部表情视频进行编码,逐帧显示上下面部区域情绪表达的存在和持续时间。这种编码需要对每帧中每个面部区域所表现的情感进行分类;记录每个表达的开始时间、顶点时间和偏移时间;并对编码员之间出现的任何分歧进行仲裁。编码者编码了28种不同的AU(最常见的AU是AU12,出现了129次),并将所有的情绪分为四种情绪标签:积极、消极、惊讶和其他。当编码者不能就表达式的起始、顶点或偏移量的精确框架达成一致时,使用两个编码者指定的值的平均值。两个编码器实现了0.82的编码可靠性(帧一致性)(从起始帧到偏移帧)。编码员还对每个表达样本的AUs进行编码。两个编码器之间的可靠性为0.8,计算如下
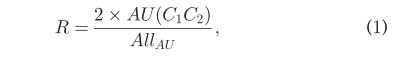
其中AU(C1C2)是编码1和编码2同意的AU数,Allau是两个编码者对面部表情评分的AU总数。编码员们讨论并仲裁了这些分歧。
3.4情感标签
在标记与面部表情相关的情绪时,以前的研究人员通常使用与相应的情绪唤起视频相关的情绪类型,并使用FACS AUs作为基线[28],[30]。然而,一个唤起情感的视频可能由多个唤起情感的事件组成。因此,根据FACS估计的情感类型和唤起视频的情感类型不具有代表性,并且许多面部动作,例如擤鼻涕、眨眼和吞咽唾液,也可以包括在表情样本中。
此外,微表情可能与宏表情不同,因为它们可能不自觉地、部分地和在短持续时间内出现;因此,仅基于面部表情和唤起视频的情感类型的微表情的情感标注是不完整的。在标记微表情时,我们还必须考虑参与者自我报告的情绪中反映的感受。
在这个数据库中,使用了一个AUs、表情启发视频的情感类型和每个面部动作的自我报告情感的组合来增强情感标签的有效性。表5列出了基于FACS编码结果的情感标记标准、引发情感的视频的情感类型和自我报告的情感。
 (其他包括无法归类为基本情绪的面部表情,如紧张与控制、伤害、同情、困惑与无助。与以前的研究一致,情感标签部分基于AUs,因为微表情通常是部分的和低强度的。此外,参与者对每个面部动作的自我报告和视频片段的内容也被考虑在内)
(其他包括无法归类为基本情绪的面部表情,如紧张与控制、伤害、同情、困惑与无助。与以前的研究一致,情感标签部分基于AUs,因为微表情通常是部分的和低强度的。此外,参与者对每个面部动作的自我报告和视频片段的内容也被考虑在内)
在以前的数据库中,面部表情样本通常被分为基本情绪,如快乐、悲伤、惊讶、厌恶和愤怒[10]或更一般的术语,如积极、消极和惊讶[28]。在这个数据库中,我们根据前面提到的标记方法将面部表情样本分为四类:阳性、阴性、惊讶和其他(见表5)。“积极”表示积极情绪的微观表达,如快乐、愉快和娱乐。“负面”是指与恐惧、厌恶和愤怒等负面情绪相关的微观表达。通常,“惊讶”这个表达很难分为积极的或消极的;因此,我们把惊讶的面部表情归为一个独立的类别。“其他”表示情感意义模糊的微表情或难以归类为六种原型面部表情的微表情。
3.5CAS(ME)2用户指南
中国科学院(ME)2数据库将可在线下载,用于研究目的。第一部分包括所有87个原始面部表情视频剪辑。avi格式)和图像序列(在rawpic.zip中带有。jpg格式),无需任何预处理。这些视频片段和图像序列可用于自动宏表情和微表情定位。宏表情和微表情的起始帧和偏移帧都显示在文件CAS(ME)2code_final.txt中。在该文件中,第二列表示表达式的编号和视频剪辑的名称。例如,在第一行中,“anger1_1”是anger1视频剪辑的第一个表达式,“anger1”是视频剪辑的名称。
B部分包括所有357个面部表情,300个宏表情和57个微表情(在selectedpic.zip中有。jpg格式)。当前的数据库还包括裁剪. zip文件中的裁剪人脸和活动形状模型中每个面部表情的68个特征点[49]。详情请参考第4.3节
文件CAS(ME)2code_final.txt包括三页。第一个,“CAS(ME)2code_final”包含9列。第一列包含参与者的数量。第二列包含表达式的编号和视频剪辑的名称。例如,在第一行,“anger1_1”是anger1视频剪辑的第一个表达式。第三列包含表达式的第一帧。第四列包含表达式的顶点框架。第五列包含表达式的最后一帧。第六列包含(AUs)(参见FACS)。第七列包含估计的情绪。第八列包含表达式类型(宏或微表达式)。第九列包含自报情绪。第二页介绍了三个文件中子文件的命名规则(“rawvideo”、“rawpic”和“selectedpic”)。例如,“s15”表示当前数据库中的第一个主题(第三列)。第三页包括每个文件的命名规则。例如,文件“15 _ 0101disgustingteeth”表示观看视频编号时主体1的面部记录(恶心1,第一次恶心视频)。
四、数据库基线评估
在本节中,LBP方法[41],[50]用于宏表情和微表情点样评价。在第4.3节中,LBP-TOP [32]直方图用于表情识别评估。
4.1 LBP and LBP-TOP
LBP[50]用于灰度图像提取纹理特征。给定灰度图像中的像素c,通过将它与它的P个邻居P进行比较来计算它的LBP码。邻居P位于一个圆心和半径等于toR的圆上,
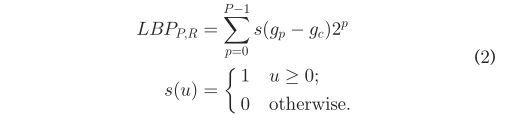
其中gcis是给定像素c的灰度值,gpis是其邻居p的值。ych,p的坐标为-xc \u rcos \u 2pp = Ph;yc?Rsinð 2pp = P或。不完全落在像素上的邻居的坐标通过双线性插值来近似。LBP编码过程如图3所示。
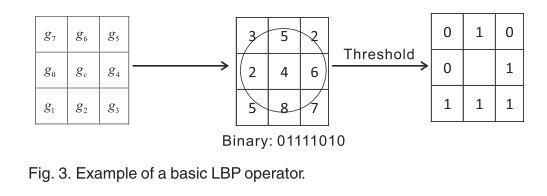
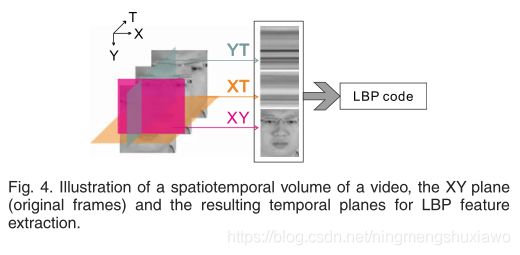
LBP只提取2D物体的特征。为了提取三维物体的特征,赵等人提出了动态LBP-TOP,这是一种从LBP [32]扩展而来的动态纹理算子。
图4示出了微表情视频剪辑,并示出了来自剪辑的单行和单列的三个正交平面(XY、XT和YT平面)。LBP-TOP代码是通过连接平面上的LBP代码来计算的。XT和YT平面分别编码垂直运动模式和水平运动模式。LBP-TOP将用于第4.3节中的表情识别评估。
4.2表情检测评估
已发表的LBP方法[41]用于计算可变间隔内视频帧的基于外观的特征的差异,并自动估计视频中的运动点,这可以获得空间和时间位置。由于头部运动相对较大,28个视频未用于自动定位评估(见表6)。以眼睛为跟踪点,进行非反射相似变换,完成人脸对齐。在基于方法[51]的面部裁剪之后,面部图像被分成6*6块结构(见图5)。计算每个块的LBP直方图。
平均特征帧(AFF)表示尾帧和头帧特征的平均值。高频表示当前分析帧之前的第kth帧,而TF表示当前分析帧之后的第kth帧计算每个块的每对LBP直方图的卡方距离;由于6*6块结构。除了视频的第一个和最后一个k帧之外,CF对视频的所有n帧进行了赋值。每帧的36对差值按降序排列。fix被定义为来自所有n个帧的第I个帧的M个最大差值的平均值,并且在该实验中M被设置为12。为了避免噪声干扰,我们采用对比差分向量Ci而不是Fito来表示差值
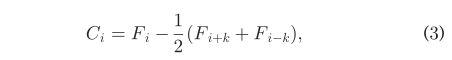
阈值用于获得代表视频中最大面部运动帧的峰值。阈值是图6a和6b中所示的虚线,其通过下式测量
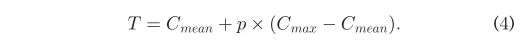
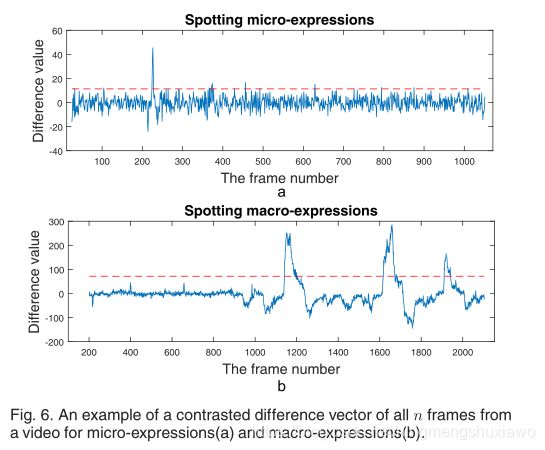
Cmeanand和Cmaxdemote分别为整个视频的平均差值和最大差值,p为0范围内的可变参数;1?。如果斑点峰值帧在所提供的真实帧的开始或偏移之前或之后落在k/2的范围内,我们认为它们是有效的。这种方法被用来识别宏表达式和微表达式。由于头部运动严重,淘汰了28个视频(即113个表情)。表6列出了28个视频。共有59个视频(即244个表情)用于自动定位测试。对于微表达点样,k设置为12,p设置为0.25。图6a示出了所有n帧的纵轴上的差值和横轴上的帧数。因此,在这个实验中,当眨眼和宏观表达也被视为真实结果时,69.8%的斑点峰值是有效的,47.3%的微观表达被斑点化。为了定位宏表达式,由于更长的表达式持续时间,k被设置为100,并且P值被设置为0.45,其以与图6b所示相同的方式呈现,其中三个正的宏表达式被定位。最终,在这个实验中,当眨眼也被视为真实结果时,70.1%的斑点峰值是有效的,75.7%的宏观表达被斑点化。
如果我们把T从0变化到Cmax,我们得到图7中的ROC曲线。当假阳性率较曲线很大。假阳性率大时,曲线与横坐标成45度角的直线平行。这一发现表明,当假阳性率较大时,腰痛的预测发生在随机水平。对于识别面部运动,预测的随机概率为0.5(运动或不运动)。
我们采用曲线下面积(AUC)来评估斑点表达的性能。AUC是二进制分类问题的一种常见评估指标。将真阳性率与假阳性率的关系图视为将项目分类为0或从0增加到1的阈值。如果分类器很好,真阳性率会迅速增加,AUC会接近1。如果分类器不比随机猜测好,那么真阳性率将随着假阳性率线性增加,并且AUC将大约为0.5。
方块的数目是5?5,6?6,7?7和8。k的值是6,12,18,24,48和96。进行了相同的实验,AUC列于表7。随着块和k值的增加,AUC增加。

4.3表情识别评估
为了评估数据库,我们使用LBP-TOP直方图[32]提取动态纹理,并使用支持向量机(SVM)方法对这些动态纹理进行分类。
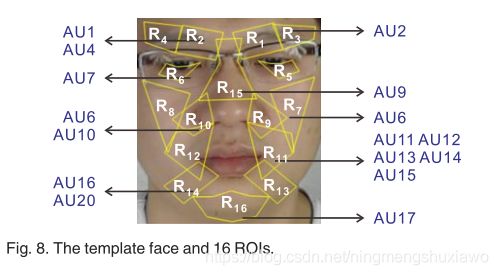
为了解决人脸在空间外观上的巨大差异,所有的人脸都被标准化为一个模板人脸,通过注册68个人脸标志点来检测。首先,我们选择一个中性表情的正面人脸图像M作为模板,模板人脸的68个标志点的坐标由ASM检测为cM。其次,对于一个样本微表情片段,我们在它的第一帧上检测到68个面部标志为cf1,并且估计模板面部和当前给定样本面部的2D几何变换为:cM Tcf1,w h e r e T是变换矩阵。第三,通过将变换T应用于微表情剪辑的所有帧,我们将样本面部注册到模板。因为视频剪辑中的头部移动不显著,所以变换T可以用于同一视频剪辑中的所有帧。每帧样本的大小被标准化为163*134像素。由于LBP-TOP是一种局部特征提取方法,因此需要将人脸图像分割成若干小块。我们选择正面中性人脸图像作为模板人脸,并将模板人脸划分为16个感兴趣区域。每个感兴趣区域对应一个或多个区域。图8显示了模板面,其中16个感兴趣区域和AUs对应于感兴趣区域[52]。
在第二部分中,我们使用了356个视频剪辑样本(一个视频剪辑中的人脸不能由ASM拟合;来自第三参与者的视频号码“恶心2_1”)。在22名受试者的356个样本中,最短样本包含4帧,最长样本包含117帧。通过线性插值将所有样本的帧数归一化为120。在这里,我们采用了留一个主题的交叉验证,即在每个文件夹中,一个参与者被用作测试集,其他参与者被用作训练集。在分析了22次折叠后,每个参与者都被用作测试集一次,最终的识别精度是基于所有结果计算的。
我们提取LBP-TOP来表示每个感兴趣区域的动态纹理特征,并构建直方图。然后,直方图连接一个向量作为分类器的输入。选择SVM分类器,以径向基函数核作为核函数。对于LBP-TOP,X轴和Y轴的半径(表示为Rxand Ry)在1到4的范围内,并且T轴的半径(表示为Rt)被分配了从2到4的各种值。XY、XT和YT平面中相邻点的数量(表示为P)设置为4和8。LBP编码采用统一模式和基本LBP。表8列出了结果。
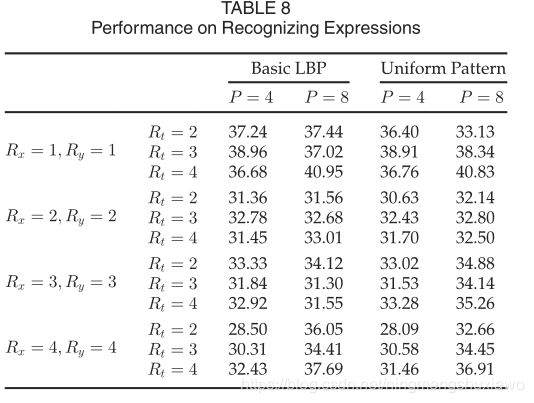
Rx 4时最低精度为28.09%;Ry 4和Rt 2。Rx 1时的最佳精度为40.95%;Ry 1,a n d Rt 4。识别性能对LBP的参数很敏感。在大多数情况下,P 8的性能要优于P 4。Rx 4时,P 8和P 4的性能约为8%;Ry 4,a n d Rt 2。相邻点数越大,LBP的性能越好。P 8条件比P 4条件有更多的点和更高的采样率,这在P 8条件下产生更高的性能。
五、讨论和结论
在本文中,我们描述了一个新的面部表情数据库,CAS(ME)2,它包含长视频流中的表情样本(A部分),可用于从长视频中进行宏观表情和微观表情识别,以及可用于自动表情识别训练的具有从开始到偏移的帧的裁剪表情样本(B部分,357个表情样本,包括300个宏观表情样本和57个微观表情样本)。这些表达样品是在相同的实验条件下从相同的个体中收集的。这个数据库可以使研究人员开发更有效的算法来提取能够从长视频中发现和区分宏观表表情和微观表情的特征。
考虑到微表情的独特特征,其发生迅速、部分(在上脸或下脸)并且强度低,这些面部表情的标记仅仅基于相应的表情,并且与引起它们的视频相关联的情感类型可能不够精确。为了提高情感标注的有效性,我们还收集了每个表情样本的参与者的情感自我报告。每个样本的情绪标签是基于FACS AUs、引发情绪的视频的情绪类型和自我报告的情绪的组合。这种标记方法应该大大提高情感类别分配的精度。此外,这三个标签是独立的,并且在数据库发布时可以访问,以使研究人员能够访问数据库中的特定表达式。
因为微表情的运动非常微妙,所以微表情的自动检测受到照明和头部运动等因素的显著影响,这些因素引起比微表情相关的面部变化更大的变化。这些因素使得微表情的自动检测具有挑战性。此外,微表情往往会随着眨眼而出现,这增加了正确检测微表情的难度。因此,微表达的识别率非常低(本次评估的最高结果约为40%)。
因为对微表情自动检测的研究正在发展,我们试图从一个数据库开始,在这个数据库中,数据是在相对严格和受控的实验环境(受控的照明和头部运动)中收集的。我们的检测方法实现了相当低的检测率。这一结果表明,未来的研究可能需要详细阐述和改进现有的方法,以更好地检测微表情。由于微表情固有的低强度和微妙的强度,未来的研究可能必须接近和开发新的方法来解决长视频中的微表情检测问题。
由于在微表情启发中遇到的困难和手工编码极其耗时的性质,当前版本的数据库中微表达样本池的大小可能并不完全足够。在以前的微表情数据库中,样本量通常很小(例如,USF-高清有100个样本,SMIC有77个样本)。在目前的数据库中,我们建立了更严格的样本选择标准。我们根据参与者自我报告的情绪,如擤鼻涕和眨眼,移除了没有情绪含义的面部动作。此操作减少了样本量,但创建了一个“更干净”的数据库。关于帧速率的问题,使用了30 fps的摄像机,与最近公布的数据库中使用的相比,这是相对较低的帧速率。我们打算通过获取额外的微表达样本来丰富样本库,为研究人员提供足够的测试和训练数据,并在未来使用更高帧率的相机。cas(me)2数据库现已在线公开测试(详见http://fu . psych . AC . cn/CASME/CAS(ME)2-en . PHP)。
生词短语
skilled expert in law enforcement field执法领域的熟练专家
polygraph 测谎器;[轻]复写器;[医]多种波动描记器 测谎仪
unobtrusive camera 不显眼的摄像头
being monitored被监控
interrogation inter-view contexts 审讯采访环境
conventional符合习俗的,传统的;常见的;惯例的
emotion induction methods 情绪诱导方法
profile 侧面;轮廓;外形;[建][地质]剖面
basic profile 基本概况
the elicitation materials启发材料
To date至今
primarily首先;主要地,根本上
commonly go unnoticed通常不会被注意到
Substantial research实质性研究
still facial expression images 静态面部表情图像
discriminant /n. 可资辨别的因素;(数)判别式
olfactory stimulation嗅觉刺激
FACS面部表情编码系统
arbitrated仲裁;[法]公断(arbitrate的过去式及过去分词)
参考文献
[12] T. Sim, S. Baker, and M. Bsat, “The CMU pose, illumination, and expression database,” IEEE Trans. Pattern Anal. Mach. Intell.,vol. 25, no. 12, pp. 1615–1618, Dec. 2003
[15] R. Cowie, E. Douglas-Cowie, and C. Cox, “Beyond emotion arche-types: Databases for emotion modelling using neural networks,”Neural Networks, vol. 18, no. 4, pp. 371–388, 2005.
[17] M. Pantic, M. Valstar, R. Rademaker, and L. Maat, “Web-based database for facial expression analysis,” in Proc. IEEE Int. Conf. Multimedia Expo, 2005, Art. no. 5
[18] T. Kanade, J. F. Cohn, and Y. Tian, “Comprehensive database forfacial expression analysis,” in Proc. 4th IEEE Int. Conf. Autom. Face Gesture Recognit., 2000, pp. 46–53.
[21] P. Lucey, J. F. Cohn, T. Kanade, J. Saragih, Z. Ambadar, and I. Matthews, “The extended Cohn-Kanade dataset (ck+): A com-plete dataset for action unit and emotion-specified expression,” inProc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. Work-shops, 2010, pp. 94–101.
[22] S. M. Mavadati, M. H. Mahoor, K. Bartlett, P. Trinh, and J. F. Cohn,“Disfa: A spontaneous facial action intensity database,” IEEE Trans. Affective Comput., vol. 4, no. 2, pp. 151–160, Apr.-Jun. 2013.
[23] D. McDuff, R. El Kaliouby, T. Senechal, M. Amr, J. F. Cohn, an R. Picard, “Affectiva-mit facial expression dataset (am-fed): Natural-istic and spontaneous facial expressions collected in-the-wild,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. Workshops, 2013,pp. 881–888
[24] S. Wang, et al. “Analyses of a multimodal spontaneous facial expression database,” IEEE Trans. Affective Comput., vol. 4, no. 1, pp. 34–46, Jan.-Mar. 2013.
[25] X. Zhang, et al., “Bp4d-spontaneous: A high-resolution spontane-ous 3d dynamic facial expression database,” Image Vis. Comput.,vol. 32, no. 10, pp. 692–706, 2014.
[28] X. Li, T. Pfister, X. Huang, G. Zhao, and M. Pietikainen, “A spontaneous micro-expression database: Inducement, collection andbaseline,” in Proc. 10th IEEE Int. Conf. and Workshops Autom. Face Gesture Recognit., 2013, pp. 1–6
[29] W.-J. Yan, Q. Wu, Y.-J. Liu, S.-J. Wang, and X. FU, “CASME Data-base: A dataset of spontaneous micro-expressions collected from neutralized faces,” in Proc. 10th IEEE Conf. Autom. Face Gesture Recognit., 2013, pp. 1–7.
[30] W.-J. Yan, et al., “CASME II: An improved spontaneous micro-expression database and the baseline evaluation,” PLoS ONE,vol. 9, no. 1, 2014, Art. no. e86041