不均衡学习和异常检测
06_不均衡学习和异常点检测
学习目标
-
知道样本不均衡时的常用处理方式
-
掌握SMOTE过采样的使用
-
知道LOF算法的原理
-
知道IForest算法的原理
-
应用异常检测算法进行数据清洗
1 样本不均衡简介
-
通常分类机器学习任务期望每种类别的样本是均衡的,即不同目标值样本的总量接近相同。
-
在梯度下降过程中,不同类别的样本量有较大差异时,很难收敛到最优解。
-
很多真实场景下,数据集往往是不平衡的,一些类别含有的数据要远远多于其他类的数据
-
在风控场景下,负样本的占比要远远小于正样本的占比
-
-
样本不均衡举例
-
假设有10万个正样本(正常客户,标签0)与1000个负样本(欺诈客户,标签1),正负样本比例100:1
-
每次梯度下降都使用全量样本,其中负样本所贡献的信息只有模型接收到的总信息的1/100,不能保证模型能很好地学习负样本
-
-
金融风控场景下样本不均衡解决方案
-
下探:最直接的解决方法。
-
下探是指在被拒绝的客户中放一部分人进来,即通过牺牲一部分收益,积累负样本,供后续模型学习
-
不过下探的代价很明显:风险越高,成本越高。它会造成信用质量的恶化,不是每个平台都愿意承担这部分坏账,并且往往很难对每次下探的量给出一个较合适的参考值。
-
-
半监督学习
-
代价敏感:通常对少数类样本进行加权处理,使得模型进行均衡训练
-
采样算法
-
欠采样
-
过采样
-
-
2 样本不均衡解决方案_代价敏感
-
代价敏感加权在传统风控领域又叫作展开法,依赖于已知表现样本的权重变化
-
假设拒绝样本的表现可以通过接收样本直接推断得到
-
代价敏感加权增大了负样本在模型中的贡献,但没有为模型引入新的信息,既没有解决选择偏误的问题,也没有带来负面影响。
-
类权重计算方法如下:
weight = n_samples/n_classes X np.bincount(y)
-
n_samples 为样本数,n_classes为类别数量,np.bincount(y)会输出每个类别样本的数量
-
-
逻辑回归通过参数class_weight = 'balanced' 调整正负样本的权重,可以使得正负样本总权重相同
-
使用之前逻辑回归评分卡的例子
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score,roc_curve,auc
data = pd.read_csv('data/Bcard.txt')
feature_lst = ['person_info','finance_info','credit_info','act_info']
train = data[data.obs_mth != '2018-11-30'].reset_index().copy()
val = data[data.obs_mth == '2018-11-30'].reset_index().copy()
x = train[feature_lst]
y = train['bad_ind']
val_x = val[feature_lst]
val_y = val['bad_ind']
lr_model = LogisticRegression(C=0.1)
lr_model.fit(x,y)
y_pred = lr_model.predict_proba(x)[:,1] #取出训练集预测值
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred) #计算TPR和FPR
train_ks = abs(fpr_lr_train - tpr_lr_train).max() #计算训练集KS
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1] #计算验证集预测值
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) #计算验证集预测值
val_ks = abs(fpr_lr - tpr_lr).max() #计算验证集KS值
print('val_ks : ',val_ks)显示结果:
train_ks : 0.41573985983413414 val_ks : 0.3928959732014397
-
查看正负样本比例发现 y = 1样本 和y=0 样本比例约为 100:2左右
print('训练集:\n',y.value_counts())
print('跨时间验证集:\n',val_y.value_counts())显示结果:
训练集: 0.0 78361 1.0 1470 Name: bad_ind, dtype: int64 跨时间验证集: 0.0 15647 1.0 328 Name: bad_ind, dtype: int64
import numpy as np
print(np.bincount(y)[1]/np.bincount(y)[0])
print(np.bincount(val_y)[1]/np.bincount(val_y)[0])显示结果:
0.01875933181046694 0.02096248482137151
-
使用相同的特征和数据,添加逻辑回归参数class_weight = 'balanced'
lr_model = LogisticRegression(C=0.1,class_weight = 'balanced')
lr_model.fit(x,y)
y_pred = lr_model.predict_proba(x)[:,1] #取出训练集预测值
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred) #计算TPR和FPR
train_ks = abs(fpr_lr_train - tpr_lr_train).max() #计算训练集KS
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1] #计算验证集预测值
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) #计算验证集预测值
val_ks = abs(fpr_lr - tpr_lr).max() #计算验证集KS值
print('val_ks : ',val_ks)显示结果:
train_ks : 0.4482325608488951 val_ks : 0.4198642457760936
-
从结果中看出,调整了class_weight='balanced' 提高了 y=1 样本的权重,可以看出模型在训练集和跨时间验证集上KS值都有5%左右的提升
3 样本不均衡解决方案_过采样
-
代价敏感加权对不均衡问题有一定帮助,但如果想达到更好的效果,仍需为模型引入更多的负样本。
-
过采样是常见的一种样本不均衡的解决方案,常用的过采样方法
-
随机过采样:将现有样本复制,但训练得到的模型泛化能力通常较差
-
SMOTE-少数类别过采样技术(Synthetic Minority Oversampling Technique)
-
SMOTE算法
-
SMOTE算法是一种用于合成少数类样本的过采样技术
-
其基本思想是对少数类样本进行分析,然后在现有少数类样本之间进行插值,人工合成新样本,并将新样本添加到数据集中进行训练
-
该技术是目前处理非平衡数据的常用手段,并受到学术界和工业界的一致认同
-
-
SMOTE算法基本步骤如下:
-
采样最邻近算法,计算出每个少数类样本的K个近邻;
-
从K个近邻中随机挑选N个样本进行随机线性插值;
-
构造新的少数类样本;
-
将新样本与原数据合成,产生新的训练集;
-
SMOTE案例
-
接下来通过引入SMOTE算法使该模型得到更好的模型效果。由于SMOTE算法是基于样本空间进行插值的,会放大数据集中的噪声和异常,因此要对训练样本进行清洗。这里使用LightGBM算法对数据进行拟合,将预测结果较差的样本权重降低不参与SMOTE算法的插值过程。
-
创建lightGBM方法,返回AUC
def lgb_test(train_x,train_y,test_x,test_y): import lightgbm as lgb clf =lgb.LGBMClassifier(boosting_type = 'gbdt', objective = 'binary', metric = 'auc', learning_rate = 0.1, n_estimators = 24, max_depth = 4, num_leaves = 25, max_bin = 40, min_data_in_leaf = 5, bagging_fraction = 0.6, bagging_freq = 0, feature_fraction = 0.8, ) clf.fit(train_x,train_y,eval_set=[(train_x,train_y),(test_x,test_y)],eval_metric = 'auc') return clf,clf.best_score_['valid_1']['auc']-
去掉lightGBM拟合效果不好的数据, 不使用这些数据进行过采样
feature_lst = ['person_info','finance_info','credit_info','act_info'] train_x = train[feature_lst] train_y = train['bad_ind'] test_x = val[feature_lst] test_y = val['bad_ind'] lgb_model,lgb_auc = lgb_test(train_x,train_y,test_x,test_y) sample = train_x.copy() sample['bad_ind'] = train_y sample['pred'] = lgb_model.predict_proba(train_x)[:,1] sample = sample.sort_values(by=['pred'],ascending=False).reset_index() sample['rank'] = np.array(sample.index)/len(sample) sample显示结果:
index person_info finance_info credit_info act_info bad_ind pred rank 0 12039 0.062660 0.690476 0.85 0.076923 1.0 0.614655 0.000000 1 79624 0.078853 0.619048 0.86 0.076923 0.0 0.538042 0.000013 2 50459 0.078853 0.571429 0.17 0.153846 1.0 0.520490 0.000025 3 56269 0.078853 0.738095 0.35 0.525641 1.0 0.508676 0.000038 4 12355 0.078853 0.666667 0.25 0.397436 0.0 0.473718 0.000050 ... ... ... ... ... ... ... ... ... 79826 22029 -0.322581 0.023810 0.00 0.576923 0.0 0.003539 0.999937 79827 22000 -0.322581 0.023810 0.00 0.576923 0.0 0.003539 0.999950 79828 40540 -0.322581 0.023810 0.00 0.551282 0.0 0.003539 0.999962 79829 56988 -0.322581 0.023810 0.00 0.525641 0.0 0.003539 0.999975 79830 39915 -0.322581 0.023810 0.00 0.538462 0.0 0.003539 0.999987 79831 rows × 9 columns
-
定义函数去掉预测值与实际值不符的部分
def weight(x, y): if x == 0 and y < 0.1: return 0.1 elif x == 1 and y > 0.7: return 0.1 else: return 1 sample['weight'] = sample.apply(lambda x:weight(x.bad_ind,x['rank']),axis = 1) smote_sample = sample[sample.weight == 1] drop_sample = sample[sample.weight < 1] train_x_smote = smote_sample[feature_lst] train_y_smote = smote_sample['bad_ind'] smote_sample.shape显示结果:
(72533, 9)-
创建smote过采样函数,进行过采样
def smote(train_x_smote,train_y_smote,K=15,random_state=0): from imblearn.over_sampling import SMOTE smote = SMOTE(k_neighbors=K, n_jobs=1,random_state=random_state) rex,rey = smote.fit_resample(train_x_smote,train_y_smote) return rex,rey rex,rey =smote(train_x_smote,train_y_smote) print('badpctn:',rey.sum()/len(rey))显示结果:
badpctn: 0.5-
使用过采样数据建模,使用训练集数据和测试集数据验证
x_smote = rex[feature_lst] y_smote = rey lr_model = LogisticRegression(C=0.1) lr_model.fit(x_smote,y_smote) x = train[feature_lst] y = train['bad_ind'] val_x = val[feature_lst] val_y = val['bad_ind'] y_pred = lr_model.predict_proba(x)[:,1] #取出训练集预测值 fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred) #计算TPR和FPR train_ks = abs(fpr_lr_train - tpr_lr_train).max() #计算训练集KS print('train_ks : ',train_ks) y_pred = lr_model.predict_proba(val_x)[:,1] #计算验证集预测值 fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) #计算验证集预测值 val_ks = abs(fpr_lr - tpr_lr).max() #计算验证集KS值 print('val_ks : ',val_ks)显示结果:
train_ks : 0.4716648926514621 val_ks : 0.42672424543316184-
上述结果发现,比使用class_weight = 'balanced',效果有进一步提升
-
-
可以将上述过程抽取,创建一个工具类进行SMOTE抽样
class imbalanceData():
"""
处理不均衡数据
train训练集
test测试集
mmin低分段错分比例
mmax高分段错分比例
bad_ind样本标签
lis不参与建模变量列表
"""
def __init__(self, train,test,mmin,mmax, bad_ind,lis=[]):
self.bad_ind = bad_ind
self.train_x = train.drop([bad_ind]+lis,axis=1)
self.train_y = train[bad_ind]
self.test_x = test.drop([bad_ind]+lis,axis=1)
self.test_y = test[bad_ind]
self.columns = list(self.train_x.columns)
self.keep = self.columns + [self.bad_ind]
self.mmin = 0.1
self.mmax = 0.7
'''''
设置不同比例,
针对头部和尾部预测不准的样本,进行加权处理。
0.1为噪声的权重,不参与过采样。
1为正常样本权重,参与过采样。
'''
def weight(self,x,y):
if x == 0 and y < self.mmin:
return 0.1
elif x == 1 and y > self.mmax:
return 0.1
else:
return 1
'''''
用一个LightGBM算法和weight函数进行样本选择
只取预测准确的部分进行后续的smote过采样
'''
def data_cleaning(self):
lgb_model,lgb_auc = self.lgb_test()
sample = self.train_x.copy()
sample[self.bad_ind] = self.train_y
sample['pred'] = lgb_model.predict_proba(self.train_x)[:,1]
sample = sample.sort_values(by=['pred'],ascending=False).reset_index()
sample['rank'] = np.array(sample.index)/len(sample)
sample['weight'] = sample.apply(lambda x:self.weight(x.bad_ind,x['rank']),
axis = 1)
smote_sample = sample[sample.weight == 1][self.keep]
drop_sample = sample[sample.weight < 1][self.keep]
train_x_smote = smote_sample[self.columns]
train_y_smote = smote_sample[self.bad_ind]
return train_x_smote,train_y_smote,drop_sample
'''''
实施smote过采样
'''
def apply_smote(self):
'''''
选择样本,只对部分样本做过采样
train_x_smote,train_y_smote 为参与过采样的样本
drop_sample为不参加过采样的部分样本
'''
train_x_smote,train_y_smote,drop_sample = self.data_cleaning()
rex,rey = self.smote(train_x_smote,train_y_smote)
print('badpctn:',rey.sum()/len(rey))
df_rex = pd.DataFrame(rex)
df_rex.columns =self.columns
df_rex['weight'] = 1
df_rex[self.bad_ind] = rey
df_aff_smote = df_rex.append(drop_sample)
return df_aff_smote,rex,rey
'''''
定义LightGBM函数
'''
def lgb_test(self):
import lightgbm as lgb
clf =lgb.LGBMClassifier(boosting_type = 'gbdt',
objective = 'binary',
metric = 'auc',
learning_rate = 0.1,
n_estimators = 24,
max_depth = 4,
num_leaves = 25,
max_bin = 40,
min_data_in_leaf = 5,
bagging_fraction = 0.6,
bagging_freq = 0,
feature_fraction = 0.8,
)
clf.fit(self.train_x,self.train_y,eval_set=[(self.train_x,self.train_y),
(self.test_x,self.test_y)],
eval_metric = 'auc')
return clf,clf.best_score_['valid_1']['auc']
'''''
调用imblearn中的smote函数
'''
def smote(self,train_x_smote,train_y_smote,K=15,random_state=0):
from imblearn.over_sampling import SMOTE
smote = SMOTE(k_neighbors=K, n_jobs=1, random_state=random_state)
rex,rey = smote.fit_resample(train_x_smote,train_y_smote)
return rex,rey
4 反欺诈与异常点检测
4.1 反欺诈检的难点
反诈骗似乎是一个二分类问题(binary classification),但其实是个多分类问题(multi-class classification)——每种不同的诈骗都当做一种单独的类型。
除了欺诈手段多样且持续变化,欺诈检测一般还面临以下问题:
-
大部分情况下数据是没有标签(label)的,各种成熟的监督学习(supervised learning)没有用武之地。
-
区分噪音(noise)和异常点(anomaly)时难度很大,甚至需要发挥一点点想象力和直觉。
-
当多种诈骗数据混合在一起,区分不同的诈骗类型更难。根本原因还是因为我们并不了解每一种诈骗定义。
-
即使真的有诈骗的历史数据,即在有标签的情况下用监督学习,也存在很大的风险。用这样的历史数据学出的模型只能检测曾经出现过与历史诈骗相似的诈骗,而对于变种的诈骗和从未见过的诈骗,模型将无能为力。
因此,在实际情况中,不建议直接用任何监督学习,至少不能单纯依靠一个监督学习模型来奢求检测到所有的诈骗。
一般使用无监督学习(unsupervised learning),且需要领域专家(domain experts)也就是对这个行业非常了解的人来验证我们的预测,提供反馈,以便于及时的调整模型。
4.2 解决反欺诈问题的可能手段
首先思考,当我们有一个场景需要做预判的时候,又完全没有标签,我们能做什么?
-
迁移学习
-
专家模型
-
无监督算法
迁移学习
源域样本和目标域样本分布有区别,目标域样本量又不够。通过算法缩小边缘分布之间和条件分布下的差异。
-
基于实例迁移
-
基于特征的迁移
-
基于模型的迁移
缺点:需要拥有与当前目标场景相关的源域数据。
专家模型
专家经验判断是根据信贷专家多年从业经验进行定性判断。与我们常用的模型不同,它是根据主观经验进行打分,而不是根据统计分析或者模型算法来进行客观的计算。
操作:
-
凭经验判断特征重要性
-
凭经验为变量加权
缺点:需要大量的行业经验积累,有时候很难让人信服。
无监督算法
缺乏足够的先验知识,无法对数据进行标记时,使用的一种机器学习方法。代表有聚类、降维等。在风控领域中我们主要使用的是聚类和无监督异常检测。而聚类是发现样本间的相似性,异常检测则是发现样本间的相异性。
聚类
-
K-Means
-
DBSCAN
-
DBSCAN是数据挖掘中最经典基于密度的聚类算法
-
基于密度的聚类算法的核心是,通过某个点r邻域内样本点的数量来衡量该点所在空间的密度
-
和k-means算法的不同的是:
-
可以不需要事先指定cluster的个数。
-
可以找出不规则形状的cluster。
-
-
-
社区发现
-
对负样本聚类,将我们的逾期客群描述成欺诈风险和信用风险两部分。社区发现算法也是当前识别团伙欺诈的主要手段之一,主要思想是通过知识图谱将小团体筛选出来。在金融领域,聚集意味着风险。
-
-
....
4.3 异常检测
异常点检测(Outlier detection),又称为离群点检测,是找出与预期对象的行为差异较大的对象的一个检测过程。这些被检测出的对象被称为异常点或者离群点。
异常点检测应用非常广泛
-
信用卡反欺诈
-
工业损毁检测
-
广告点击反作弊
-
刷好评,刷单检测
-
羊毛党检测
异常点(outlier)是一个数据对象,它明显不同于其他的数据对象。如下图1所示,N1、N2区域内的点是正常数据。而离N1、N2较远的O1、O2、O3区域内的点是异常点。
异常检测一般是无监督的,和普通的二分类问题也不大相同,因为异常检测往往看似是二分类,但其实是多分类(造成异常的原因各不相同)。
算法假设
-
异常数据跟样本中大多数数据不太一样。
-
异常数据在整体数据样本中占比比较小。
主要思想
主流异常检测方法都是基于样本(小群体)间的相似度(proximity)
-
距离
-
密度
-
角度
-
隔离所需的难度
-
簇
为什么要用无监督异常检测方法?
-
样本群体有异构成分,可以对样本做筛选
-
很多场景没有标签或者标签很少,不能训练监督模型(比如冷启动项目、欺诈模型)
-
样本总是在发生变换,只能从一个小群体内部发现异常(比如欺诈检测,手段多变,团伙欺诈通常集中在某段时间内)
-
异常检测假设异常样本占比很少,并且从某种度量上远离其他样本,这符合我们个体欺诈的先验知识。但是在团体欺诈检测中就不太适用了
异常点检验常用算法:
-
Z-score检验
-
Local Outlier Factor
-
孤立森林
z-score异常检测
假设样本服从正态分布,用于描述样本偏离正态分布的程度。
通过计算$\mu$和$\sigma$得到当前样本所属于的正态分布的表达式,然后分别计算每个样本在这个概率密度函数下被生成的概率,当概率小于某一阈值我们认为这个样本是不属于这个分布的,因此定义为异常值。
计算公式:
Z score = (x -μ) /δ
上图中展示了一组符合正态分布的数据,从图中看出
-
68% 的数据分布在 +/- 1 倍标准差之间
-
95% 的数据分布在 +/- 2 倍标准差之间
-
99.7% 的数据分布在 +/- 3 倍标准差之间
从上面结论中得出,如果一个数据计算出它的z score >2 甚至>3 说明这个数据和其它数据之间有很大差别
缺点:需要假设样本满足正态分布,而我们大部分场景都不满足这种假设条件。
Local Outlier Factor
LOF是基于密度的经典算法(Breuning et. al. 2000), 文章发表于 SIGMOD 2000
-
在 LOF 之前的异常检测算法大多是基于统计方法的,或者是借用了一些聚类算法用于异常点的识别(比如 ,DBSCAN)。
-
基于统计的异常检测算法通常需要假设数据服从特定的概率分布,但假设往往不成立
-
聚类方法通常只能给出 0/1 的判断(即:是不是异常点),不能量化每个数据点的异常程度
-
基于密度的LOF算法要更简单、直观,不需要对数据的分布做太多要求,还能量化每个数据点的异常程度(outlierness)。
LOF会为每一个数据点计算出一个分数,通过这个分数的大小来判断数据是否异常
-
LOF ≈1 ⇒ 非异常 LOF ≫1 ⇒ 异常
LOF相关概念
-
首先要确定参数K,K是LOF计算时需要考虑的近邻点数量
-
LOF通过计算最近的K个点的距离来计算密度,然后将其与其它点的密度进行比较
-
K的选择会对结果产生影响
-
选择比较小的K值,会只计算附近的点,但会受到噪声的影响
-
如果K选的比较大,可能会错过局部离群点
-
-
-
K-邻近距离(k-distance):K确定下来,我们可以计算k-distance,即点到第k个邻居的距离。 如果k为3,则k-distance将是点到第三最近点的距离
-
可达距离(reachability distance):该距离表示的是两个点的距离和第二个点的k-distance中的最大值。
-
reach-dist(a,b) = max{k-distance(b), dist(a,b)}
-
如果点a在点b的k个邻居内,则reach-dist(a,b)将是b的k-距离。否则,它将是a和b的实际距离。为了便于理解,可以当做两点之间的距离
-
-
局部可达密度(local reachability density)lrd:LRD可以通过reach-dist计算得出
-
点a的lrd,首先计算a到它的所有k个最近邻居的reach-dist,并取该数字的平均值,lrd是该平均值的倒数。
-
LRD代表一种密度,因此,到下一个近邻点的距离越长,相应点所在的区域就越稀疏。反之密度越小
-
lrd(a) = 1/(sum(reach-dist(a,n))/k)
-
通俗点儿说,LRD告诉我们,从一点到另一个点或者另一堆点,距离多远,LRD越小,密度越低,距离越远
-
上图中,右上角的点的lrd = 它最近的邻居[ (-1, -1), (-1.5, -1.5) , (-1, -2)] 这三个点的reach-dist的平均值的倒数
但是计算下面点的lrd时不会把右上角的点计算进去
-
LOF 局部异常因子(local outlier factor):将每个点的lrd与它们的k个邻居的lrd相比较
-
某点的LOF= K个邻居的LRD的平均值/该点的LRD
-
LRD 越小 密度越低距离越远 ,离群点的LRD小,它的邻居的LRD会比较大
-
离群点的LOF = 较大的邻居的LRD平均值/ 较小的离群点的LRD >>1
-
算法流程 LOF算法的实现流程如下: 1)首先对样本空间进行去重,分别计算每一个样本到样本空间内其余点的距离。 2)将步骤1中的距离升序排列。 3)指定近邻样本个数k,对于每个样本点,寻找其k近邻样本,然后计算LOF分数,作为异常分数。
根据局部异常因子的定义
-
如果数据点 p 的 LOF 得分在1附近,表明数据点p的局部密度跟它的邻居们差不多;
-
如果数据点 p 的 LOF 得分小于1,表明数据点p处在一个相对密集的区域,不像是一个异常点;
-
如果数据点 p 的 LOF 得分远大于1,表明数据点p跟其他点比较疏远,很有可能是一个异常点
-
下面这个图来自 Wikipedia 的 LOF 词条,展示了一个二维的例子。上面的数字标明了相应点的LOF得分
了解了 LOF 的定义,整个算法也就显而易见了:
-
对于每个数据点,计算它与其它所有点的距离,并按从近到远排序;
-
对于每个数据点,找到它的 k-nearest-neighbor,计算 LOF 得分。
PyOD是一个用于检测数据中异常值的库。它提供对20多种不同算法的访问,以检测异常值,下面的算法都通过PYOD实现
from pyod.models.lof import LOF
clf = LOF(n_neighbors=20, algorithm='auto') #n_neighbors K个最近的邻居 ,algorithm:找到最近邻居的算法,传入auto 会根据传入的数据自动选择最合适算法
clf.fit(x)
out_pred = clf.predict_proba(x)[:,1]
train['out_pred'] = out_pred
key = train['out_pred'].quantile(0.93)
x = train[train.out_pred< key][feature_lst]
y = train[train.out_pred < key]['bad_ind']
val_x = val[feature_lst]
val_y = val['bad_ind']
lr_model = LogisticRegression(C=0.1,class_weight='balanced')
lr_model.fit(x,y)
y_pred = lr_model.predict_proba(x)[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
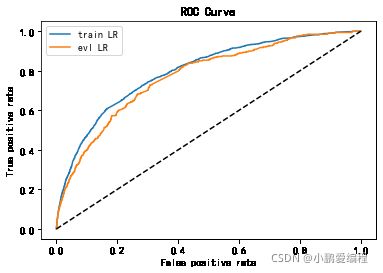
from matplotlib import pyplot as plt
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR')
plt.plot(fpr_lr,tpr_lr,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
train_ks : 0.44478665277545076 val_ks : 0.4212513658817166显示结果:
算法应用
LOF算法中关于局部可达密度的定义其实暗含了一个假设,即:不存在大于等于 k 个重复的点。当这样的重复点存在的时候,这些点的平均可达距离为零,局部可达密度就变为无穷大,会给计算带来一些麻烦。在实际应用时,为了避免这样的情况出现,可以把 k-distance 改为 k-distinct-distance,不考虑重复的情况。或者,还可以考虑给可达距离都加一个很小的值,避免可达距离等于零。
LOF 算法需要计算数据点两两之间的距离,造成整个算法时间复杂度为 $O(n^2)$ 。为了提高算法效率,后续有算法尝试改进。
FastLOF (Goldstein,2012)先将整个数据随机的分成多个子集,然后在每个子集里计算 LOF 值。对于那些 LOF 异常得分小于等于 1 的,从数据集里剔除,剩下的在下一轮寻找更合适的 nearest-neighbor,并更新 LOF 值。
这种先将数据粗略分成多个部分,然后根据局部计算结果将数据过滤来减少计算量的想法,并不罕见。比如,为了改进 K-means 的计算效率, Canopy Clustering 算法也采用过比较相似的做法。
Isolation Forest
先用一个简单的例子来说明 Isolation Forest 的基本想法
-
假设现在有一组一维数据(如下图所示),我们要对这组数据进行随机切分,希望可以把点 A 和点 B 单独切分出来
-
先在最大值和最小值之间随机选择一个值 x,然后按照
=x 可以把数据分成左右两组 -
在这两组数据中分别重复这个步骤,直到数据不可再分。点 B 跟其他数据比较疏离,可能用很少的次数就可以把它切分出来
-
点 A 跟其他数据点聚在一起,可能需要更多的次数才能把它切分出来。
把数据从一维扩展到两维,沿着两个坐标轴进行随机切分,尝试把下图中的点A'和点B'分别切分出来
-
先随机选择一个特征维度,在这个特征的最大值和最小值之间随机选择一个值,按照跟特征值的大小关系将数据进行左右切分
-
在左右两组数据中重复上述步骤,随机按某个特征维度的取值把数据细分,直到无法细分(剩下一个数据点,或剩下的数据都相同。
-
点B'跟其他数据点比较疏离,可能只需要很少的几次操作就可以将它细分出来;点A'需要的切分次数可能会更多一些。
按照之前提到的关于“异常”的两个假设,一般情况下在上面的例子中:
-
点B和点B' 由于跟其他数据隔的比较远,会被认为是异常数据
-
而点A和点A' 会被认为是正常数据
-
直观上,异常数据由于跟其他数据点较为疏离,可能需要较少几次切分就可以将它们单独划分出来,而正常数据恰恰相反。
-
这正是Isolation Forest(IF)的核心概念。IF采用二叉树去对数据进行切分,数据点在二叉树中所处的深度反应了该条数据的“疏离”程度。整个算法大致可以分为两步:
-
训练:抽取多个样本,构建多棵二叉树(Isolation Tree,即 iTree);
-
预测:综合多棵二叉树的结果,计算每个数据点的异常分值。
训练:构建一棵 iTree 时,先从全量数据中抽取一批样本,然后随机选择一个特征作为起始节点,并在该特征的最大值和最小值之间随机选择一个值,将样本中小于该取值的数据划到左分支,大于等于该取值的划到右分支。然后,在左右两个分支数据中,重复上述步骤,直到满足如下条件:
-
数据不可再分,即:只包含一条数据,或者全部数据相同。
-
二叉树达到限定的最大深度。
预测:计算数据 x 的异常分值时,先要估算它在每棵 iTree 中的路径长度(也可以叫深度)。具体的,先沿着一棵 iTree,从根节点开始按不同特征的取值从上往下,直到到达某叶子节点。假设 iTree 的训练样本中同样落在 x 所在叶子节点的样本数为 T.size,则数据 x 在这棵 iTree 上的路径长度 h(x),可以用下面这个公式计算:
公式中,e 表示数据 x 从 iTree 的根节点到叶节点过程中经过的边的数目,C(T.size) 可以认为是一个修正值,它表示在一棵用 T.size 条样本数据构建的二叉树的平均路径长度。一般的,C(n) 的计算公式如下:
其中,H(n-1) 可用 ln(n-1)+0.5772156649 估算,这里的常数是欧拉常数。数据 x 最终的异常分值 Score(x) 综合了多棵 iTree 的结果:
公式中,E(h(x)) 表示数据 x 在多棵 iTree 的路径长度的均值,$φ$表示单棵 iTree 的训练样本的样本数,$C(φ)$表示用$φ$条数据构建的二叉树的平均路径长度,它在这里主要用来做归一化。
-
从异常分值的公式看
-
如果数据 x 在多棵 iTree 中的平均路径长度越短,得分越接近 1,表明数据 x 越异常
-
如果数据 x 在多棵 iTree 中的平均路径长度越长,得分越接近 0,表示数据 x 越正常
-
如果数据 x 在多棵 iTree 中的平均路径长度接近整体均值,则打分会在 0.5 附近。
-
应用案例
-
对比之前的评分卡案例
import pandas as pd
'''
省略部分代码
'''
data = pd.read_csv('data/Bcard.txt')
data.head()
train = data[data.obs_mth != '2018-11-30'].reset_index().copy()
val = data[data.obs_mth == '2018-11-30'].reset_index().copy()
feature_lst = ['person_info','finance_info','credit_info','act_info']
x = train[feature_lst]
y = train['bad_ind']
val_x = val[feature_lst]
val_y = val['bad_ind']
lr_model = LogisticRegression(C=0.1,class_weight='balanced')
lr_model.fit(x,y)
y_pred = lr_model.predict_proba(x)[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
'''
省略绘图代码
'''
显示结果:
train_ks : 0.4482453222991063 val_ks : 0.4198642457760936
-
使用原有数据,对数据进行清洗,将异常样本通过无监督算法进行筛选
from pyod.models.iforest import IForest
clf = IForest(behaviour='new',n_estimators=500, n_jobs=-1)#behaviour = 'new' 为了兼容后续版本
clf.fit(x)
显示结果:
IForest(behaviour='new', bootstrap=False, contamination=0.1, max_features=1.0, max_samples='auto', n_estimators=500, n_jobs=-1, verbose=0)
-
去掉原有数据中异常值可能性较大的进行建模
out_pred = clf.predict_proba(x,method ='linear')[:,1]
train['out_pred'] = out_pred
x = train[train.out_pred< 0.7][feature_lst]
y = train[train.out_pred < 0.7]['bad_ind']
val_x = val[feature_lst]
val_y = val['bad_ind']
lr_model = LogisticRegression(C=0.1,class_weight='balanced')
lr_model.fit(x,y)
y_pred = lr_model.predict_proba(x)[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
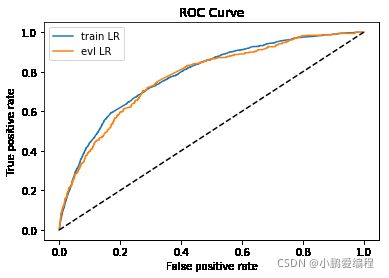
from matplotlib import pyplot as plt
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR')
plt.plot(fpr_lr,tpr_lr,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
显示结果:
train_ks : 0.4236319500363655 val_ks : 0.4303032062563228
-
可以看出,验证集上KS表现有所提升
-
通过样本异常程度进行分析
-
分月份查看样本异常情况,异常概率的:均值,极值,方差,去掉超出阈值的异常点之后的概率均值
-
发现每个月份异常情况差别不是特别大
-
如果某个月份的平均异常概率较高/方差较大,需要查明原因(渠道问题,运营动作导致... ....)
-
train.out_pred.groupby(train.obs_mth).mean()
显示结果:
obs_mth 2018-06-30 0.192007 2018-07-31 0.187192 2018-09-30 0.240995 2018-10-31 0.229805 Name: out_pred, dtype: float64
train.out_pred.groupby(train.obs_mth).max()
显示结果:
obs_mth 2018-06-30 1.000000 2018-07-31 0.986448 2018-09-30 0.989131 2018-10-31 0.969128 Name: out_pred, dtype: float64
train.out_pred.groupby(train.obs_mth).var()
显示结果:
obs_mth 2018-06-30 0.026854 2018-07-31 0.023288 2018-09-30 0.039062 2018-10-31 0.037413 Name: out_pred, dtype: float64
train['for_pred'] = np.where(train.out_pred>0.7,1,0)
train.for_pred.groupby(train.obs_mth).mean()
显示结果:
obs_mth 2018-06-30 0.016825 2018-07-31 0.010785 2018-09-30 0.035111 2018-10-31 0.028017 Name: for_pred, dtype: float64
-
preA模型
-
PreA模型指在申请评分卡之前,设置一张根据免费数据进行粗筛选的评分卡
-
贷款用户首次申请贷款时,平台通常要查询外部收费数据,如征信数据等,从而更好地评估用户信用情况
-
避免资金浪费,贷款平台会用一些免费数据对用户进行初筛(被拒绝的用户调用收费数据,这部分用户数据的钱相当于白花了)
-
preA模型可以拒绝很少量的客群,其中大部分是负样本
-
-
使用异常分数作为PreA模型的评分,使用0.7分作为正负样本的分割阈值
#看一下badrate train.bad_ind.groupby(train.for_pred).sum()/train.bad_ind.groupby(train.for_pred).count()显示结果:
for_pred 0 0.016417 1 0.122995 Name: bad_ind, dtype: float64-
异常值超过0.7的客群badrate达到了12%,将这一部分人拒绝会使我们的收益有所提高
-
-
使用IF模型做冷启动/反欺诈模型
-
假设前面的A卡没有标签,我们来看一下直接无监督建模的模型实际效果会是怎么样
-
y_pred = clf.predict_proba(x,method ='linear')[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = clf.predict_proba(val_x,method ='linear')[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
from matplotlib import pyplot as plt
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR')
plt.plot(fpr_lr,tpr_lr,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
显示结果:
train_ks : 0.31704360914573587 val_ks : 0.30647599399557623
-
模型报告
import math
#准备数据
model = clf
bins = 20
temp_ = pd.DataFrame() #创建空白DataFrame
temp_['bad_rate_predict'] = [s[1] for s in model.predict_proba(val_x)]# 预测结果(坏人概率)
temp_['real_bad'] = val_y # 真实结果
temp_ = temp_.sort_values('bad_rate_predict',ascending = False)#按照预测坏人概率降序排列
temp_['num'] = [i for i in range(temp_.shape[0])] #添加序号列,用于分组
temp_['num'] = pd.cut(temp_.num,bins = bins,labels = [i for i in range(bins)])#分成20组,为每组添加组号
#创建报告
report = pd.DataFrame()#创建空白DataFrame
#计算每一组坏人数量
report['BAD'] = temp_.groupby('num').real_bad.sum().astype(int)
#计算每一组好人数量
report['GOOD'] = temp_.groupby('num').real_bad.count().astype(int)-report['BAD']
#累计求和坏人数量
report['BAD_CNT'] = report['BAD'].cumsum()
#累计求和好人数量
report['GOOD_CNT'] = report['GOOD'].cumsum()
good_total = report.GOOD_CNT.max()
bad_total = report.BAD_CNT.max()
#计算到当前组坏人比例(占所有坏人比例)
report['BAD_PCTG'] = round(report.BAD_CNT/bad_total,3)
#计算当前组坏人概率
report['BADRATE'] =report.apply(lambda x: round(x.BAD/(x.BAD+x.GOOD),3),axis = 1)
#计算KS值
def cal_ks(x):
#当前箱累计坏人数量/总坏人数量 - 当前箱累计好人数量/好人数量
ks = (x.BAD_CNT/bad_total)-(x.GOOD_CNT/good_total)
return round(math.fabs(ks),3)
report['KS'] = report.apply(cal_ks,axis = 1)
report
显示结果:
Out[37]:
num
BAD GOOD BAD_CNT GOOD_CNT BAD_PCTG BADRATE KS 0 70 729 70 729 0.213 0.088 0.167 1 36 763 106 1492 0.323 0.045 0.228 2 27 772 133 2264 0.405 0.034 0.261 3 27 771 160 3035 0.488 0.034 0.294 4 18 781 178 3816 0.543 0.023 0.299 5 18 781 196 4597 0.598 0.023 0.304 6 10 788 206 5385 0.628 0.013 0.284 7 13 786 219 6171 0.668 0.016 0.273 8 14 785 233 6956 0.710 0.018 0.266 9 20 779 253 7735 0.771 0.025 0.277 10 6 792 259 8527 0.790 0.008 0.245 11 2 797 261 9324 0.796 0.003 0.200 12 10 789 271 10113 0.826 0.013 0.180 13 3 795 274 10908 0.835 0.004 0.138 14 12 787 286 11695 0.872 0.015 0.125 15 5 794 291 12489 0.887 0.006 0.089 16 10 788 301 13277 0.918 0.013 0.069 17 5 794 306 14071 0.933 0.006 0.034 18 9 790 315 14861 0.960 0.011 0.011 19 13 786 328 15647 1.000 0.016 0.000
-
相比于逻辑回归有监督的评分卡来看效果还是稍差一些的,但是对于无监督学习来说效果是非常不错的
-
实际效果可能没有这么好,上面数据中的变量是通过有监督的方式筛选出来的
小结
-
知道样本不均衡时的常用处理方式
-
掌握SMOTE过采样的使用
-
知道LOF算法的原理
-
知道IForest算法的原理
-
应用异常检测算法进行数据清洗