样本不均衡
1. 简介
1.1 定义
- 通常分类机器学习任务期望每种类别的样本是均衡的,即不同目标值样本的总量接近相同。
- 在梯度下降过程中,不同类别的样本量有较大差异时,很难收敛到最优解。
- 很多真实场景下,数据集往往是不平衡的,一些类别含有的数据要远远多于其他类的数据
- 在风控场景下,负样本的占比要远远小于正样本的占比
1.2 举例
- 假设有10万个正样本(正常客户,标签0)与1000个负样本(欺诈客户,标签1),正负样本比例100:1
- 每次梯度下降都使用全量样本,其中负样本所贡献的信息只有模型接收到的总信息的1/100,不能保证模型能很好地学习负样本
1.3 金融风控场景下样本不均衡解决方案
- 下探:最直接的解决方法
- 下探是指在被拒绝的客户中放一部分人进来,即通过牺牲一部分收益,积累负样本,供后续模型学习
- 不过下探的代价很明显:风险越高,成本越高,它会造成信用质量的恶化,不是每个平台都愿意承担这部分坏账,并且往往很难对每次下探的量给出一个较合适的参考值
- 半监督学习
- 标签分列
- 代价敏感:通常对少数类样本进行加权处理,使得模型进行均衡训练
- 采样算法
- 欠采样
- 过采样
2. 解决方案
2.1 代价敏感
1. 简介
- 代价敏感加权在传统风控领域又叫做展开法,依赖于已知表现样本的权重变化
- 假设拒绝样本的表现可以通过接收样本直接推断得到
- 代价敏感加权增大了负样本在模型中的贡献,但没有为模型引入新的信息,既没有解决选择偏误的问题,也没有带来负面影响
- 类权重计算方法如下:
weight = n_samples/(n_classes * np.bincount(y))n_samples为样本数,n_classes为类别数量,np.bincount(y)会输出每个样本的数量
- 逻辑回归通过参数
class_weight = 'balanced'调整正负样本的权重,可以使得正负样本总权重相同
2. 应用
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score,roc_curve,auc
data = pd.read_csv('data/Bcard.txt')
feature_lst = ['person_info','finance_info','credit_info','act_info']
train = data[data.obs_mth != '2018-11-30'].reset_index().copy()
val = data[data.obs_mth == '2018-11-30'].reset_index().copy()
x = train[feature_lst]
y = train['bad_ind']
val_x = val[feature_lst]
val_y = val['bad_ind']
lr_model = LogisticRegression(C=0.1)
lr_model.fit(x,y)
y_pred = lr_model.predict_proba(x)[:,1] #取出训练集预测值
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred) #计算TPR和FPR
train_ks = abs(fpr_lr_train - tpr_lr_train).max() #计算训练集KS
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1] #计算验证集预测值
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) #计算验证集预测值
val_ks = abs(fpr_lr - tpr_lr).max() #计算验证集KS值
print('val_ks : ',val_ks)
- 查看正负样本比例发现y = 1样本和y = 0样本比例约为100:2左右
print('训练集:\n',y.value_counts())
print('跨时间验证集:\n',val_y.value_counts())
import numpy as np
print(np.bincount(y)[1]/np.bincount(y)[0])
print(np.bincount(val_y)[1]/np.bincount(val_y)[0])
- 使用相同的特征和数据,添加逻辑回归参数
class_weight = 'balanced'
lr_model = LogisticRegression(C=0.1,class_weight = 'balanced')
lr_model.fit(x,y)
y_pred = lr_model.predict_proba(x)[:,1] #取出训练集预测值
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred) #计算TPR和FPR
train_ks = abs(fpr_lr_train - tpr_lr_train).max() #计算训练集KS
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1] #计算验证集预测值
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) #计算验证集预测值
val_ks = abs(fpr_lr - tpr_lr).max() #计算验证集KS值
print('val_ks : ',val_ks)
- 从结果中看出,调整了
class_weight = 'balanced'提高了y = 1样本的权重,可以看出模型在训练集和时间验证集上KS值都有5%左右的提升
在风控领域中,将一个坏用户分类为好用户所造成的损失远远大于将一个好用户分类来坏用户的损失,因此在这种情况下要尽量避免将坏用户分类为好用户
# 使用sklearn计算
from sklearn.utils.class_weight import compute_class_weight
class_weight = 'balanced'
classes = np.array([0, 1, 2]) #标签类别
weight = compute_class_weight(class_weight, classes, y)
print(weight)
# [0.66666667 0.88888889 2.66666667]
-
逻辑回归通过参数class_weight = ‘balanced’ 调整正负样本的权重,可以使得正负样本总权重相同
-
使用之前逻辑回归评分卡的例子
train_ks : 0.41573985983413414
val_ks : 0.3928959732014397 -
使用相同的特征和数据,添加逻辑回归参数class_weight = ‘balanced’
train_ks : 0.4482325608488951
val_ks : 0.4198642457760936 -
从结果中看出,调整了class_weight=‘balanced’ 提高了 y=1 样本的权重,可以看出模型在训练集和跨时间验证集上KS值都有5%左右的提升
2.2 过采样
1. 简介
- 代价敏感加权对不均衡问题有一定帮助,但如果想达到更好地效果,仍需为模型引入更多的负样本。
- 过采样是最常见的一种样本不均衡的解决方案,常用的过采样方法
- 随机过采样:将现有样本复制,但训练得到的模型泛化能力通常较差
- SMOTE-少数类别过采样技术(Synthetic Minority Oversampling Technique)
2. SMOTE算法
2.1 简介
- SMOTE算法是一种用于合成少数类样本的过采样样本
- 其基本思想是对少数样本进行分析,然后现有少数类样本之间进行插值,人工合成新样本,并将新样本添加到数据集中进行训练
- 该技术是目前处理非平衡数据的常用手段,并受到学术界和工业界的一致认同
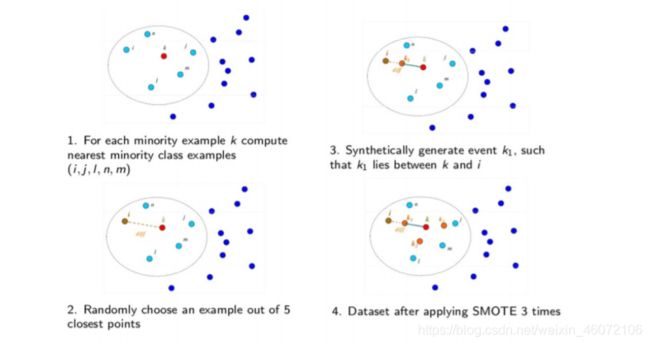
2.2 基本步骤
- 采样最邻近算法,计算出每个少数类样本的K个近邻;
- 从K个近邻中随机挑选N个样本进行随机线性插值;
- 构造新的少数类样本;
- 将新样本与原数据合成,产生新的训练集;
2.3 应用
- 接下来通过引入SMOTE算法使该模型得到更好的模型效果。
- 由于SMOTE算法是基于样本空间进行插值的,回放大数据集中的噪声和异常,因此要对训练样本进行清洗。
- 这里使用LightGBM算法对数据进行拟合,将预测结果较差的样本权重降低不参与SMOTE算法的插值过程
- 创建LightGBM方法,返回AUC
def lgb_test(train_x,train_y,test_x,test_y):
import lightgbm as lgb
clf =lgb.LGBMClassifier(boosting_type = 'gbdt',
objective = 'binary',
metric = 'auc',
learning_rate = 0.1,
n_estimators = 24,
max_depth = 4,
num_leaves = 25,
max_bin = 40,
min_data_in_leaf = 5,
bagging_fraction = 0.6,
bagging_freq = 0,
feature_fraction = 0.8,
)
clf.fit(train_x,train_y,eval_set=[(train_x,train_y),(test_x,test_y)],eval_metric = 'auc')
return clf,clf.best_score_['valid_1']['auc']
- 去掉LightGBM拟合效果不好的数据,不使用这些数据进行过采样
feature_lst = ['person_info','finance_info','credit_info','act_info']
train_x = train[feature_lst]
train_y = train['bad_ind']
test_x = val[feature_lst]
test_y = val['bad_ind']
lgb_model,lgb_auc = lgb_test(train_x,train_y,test_x,test_y)
sample = train_x.copy()
sample['bad_ind'] = train_y
sample['pred'] = lgb_model.predict_proba(train_x)[:,1]
sample = sample.sort_values(by=['pred'],ascending=False).reset_index()
sample['rank'] = np.array(sample.index)/len(sample)
sample
- 定义函数去掉预测值与实际值不符的部分
def weight(x, y):
if x == 0 and y < 0.1:
return 0.1
elif x == 1 and y > 0.7:
return 0.1
else:
return 1
sample['weight'] = sample.apply(lambda x:weight(x.bad_ind,x['rank']),axis = 1)
smote_sample = sample[sample.weight == 1]
drop_sample = sample[sample.weight < 1]
train_x_smote = smote_sample[feature_lst]
train_y_smote = smote_sample['bad_ind']
smote_sample.shape
- 创建smote过采样函数,进行过采样
def smote(train_x_smote,train_y_smote,K=15,random_state=0):
from imblearn.over_sampling import SMOTE
smote = SMOTE(k_neighbors=K, n_jobs=1,random_state=random_state)
rex,rey = smote.fit_resample(train_x_smote,train_y_smote)
return rex,rey
得到正负样本均衡的数据集
def smote(train_x_smote,train_y_smote,K=15,random_state=0):
from imblearn.over_sampling import SMOTE
smote = SMOTE(k_neighbors=K, n_jobs=1,random_state=random_state)
rex,rey = smote.fit_resample(train_x_smote,train_y_smote)
return rex,rey
rex,rey =smote(train_x_smote,train_y_smote)
print('badpctn:',rey.sum()/len(rey))
- 采用过采样数据建模,使用训练集数据和测试集数据验证
x_smote = rex[feature_lst]
y_smote = rey
lr_model = LogisticRegression(C=0.1)
lr_model.fit(x_smote,y_smote)
x = train[feature_lst]
y = train['bad_ind']
val_x = val[feature_lst]
val_y = val['bad_ind']
y_pred = lr_model.predict_proba(x)[:,1] #取出训练集预测值
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred) #计算TPR和FPR
train_ks = abs(fpr_lr_train - tpr_lr_train).max() #计算训练集KS
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1] #计算验证集预测值
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) #计算验证集预测值
val_ks = abs(fpr_lr - tpr_lr).max() #计算验证集KS值
print('val_ks : ',val_ks)
- 上述结果发现,比使用class_weight = ‘balanced’,效果有进一步提升
- 可以将上述过程抽取,创建一个工具类进行SMOTE抽样
class imbalanceData():
"""
处理不均衡数据
train训练集
test测试集
mmin低分段错分比例
mmax高分段错分比例
bad_ind样本标签
lis不参与建模变量列表
"""
def __init__(self, train,test,mmin,mmax, bad_ind,lis=[]):
self.bad_ind = bad_ind
self.train_x = train.drop([bad_ind]+lis,axis=1)
self.train_y = train[bad_ind]
self.test_x = test.drop([bad_ind]+lis,axis=1)
self.test_y = test[bad_ind]
self.columns = list(self.train_x.columns)
self.keep = self.columns + [self.bad_ind]
self.mmin = 0.1
self.mmax = 0.7
'''''
设置不同比例,
针对头部和尾部预测不准的样本,进行加权处理。
0.1为噪声的权重,不参与过采样。
1为正常样本权重,参与过采样。
'''
def weight(self,x,y):
if x == 0 and y < self.mmin:
return 0.1
elif x == 1 and y > self.mmax:
return 0.1
else:
return 1
'''''
用一个LightGBM算法和weight函数进行样本选择
只取预测准确的部分进行后续的smote过采样
'''
def data_cleaning(self):
lgb_model,lgb_auc = self.lgb_test()
sample = self.train_x.copy()
sample[self.bad_ind] = self.train_y
sample['pred'] = lgb_model.predict_proba(self.train_x)[:,1]
sample = sample.sort_values(by=['pred'],ascending=False).reset_index()
sample['rank'] = np.array(sample.index)/len(sample)
sample['weight'] = sample.apply(lambda x:self.weight(x.bad_ind,x['rank']),
axis = 1)
smote_sample = sample[sample.weight == 1][self.keep]
drop_sample = sample[sample.weight < 1][self.keep]
train_x_smote = smote_sample[self.columns]
train_y_smote = smote_sample[self.bad_ind]
return train_x_smote,train_y_smote,drop_sample
'''''
实施smote过采样
'''
def apply_smote(self):
'''''
选择样本,只对部分样本做过采样
train_x_smote,train_y_smote 为参与过采样的样本
drop_sample为不参加过采样的部分样本
'''
train_x_smote,train_y_smote,drop_sample = self.data_cleaning()
rex,rey = self.smote(train_x_smote,train_y_smote)
print('badpctn:',rey.sum()/len(rey))
df_rex = pd.DataFrame(rex)
df_rex.columns =self.columns
df_rex['weight'] = 1
df_rex[self.bad_ind] = rey
df_aff_smote = df_rex.append(drop_sample)
return df_aff_smote,rex,rey
'''''
定义LightGBM函数
'''
def lgb_test(self):
import lightgbm as lgb
clf =lgb.LGBMClassifier(boosting_type = 'gbdt',
objective = 'binary',
metric = 'auc',
learning_rate = 0.1,
n_estimators = 24,
max_depth = 4,
num_leaves = 25,
max_bin = 40,
min_data_in_leaf = 5,
bagging_fraction = 0.6,
bagging_freq = 0,
feature_fraction = 0.8,
)
clf.fit(self.train_x,self.train_y,eval_set=[(self.train_x,self.train_y),
(self.test_x,self.test_y)],
eval_metric = 'auc')
return clf,clf.best_score_['valid_1']['auc']
'''''
调用imblearn中的smote函数
'''
def smote(self,train_x_smote,train_y_smote,K=15,random_state=0):
from imblearn.over_sampling import SMOTE
smote = SMOTE(k_neighbors=K, n_jobs=1, random_state=random_state)
rex,rey = smote.fit_resample(train_x_smote,train_y_smote)
return rex,rey