python 数据分析核心--pandas
前言
Python作为一门数据可视化很好的语言,可以使用像matplotlib等库画出图形,处理数据主要使用pandas
这里主要讨论Pandas
初识pandas
大多数人只要提及pandas,基本都知道,只要是学习python的人
Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算),其次数series,还有一个DataFrame,这三个比较常用。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas的主体
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
Series:带标签的一维同构数组,一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
DataFrame:带标签,大小可变,二维异构表格。一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
Pandas的安装
一般情况下只要电脑上安装Python后,并将python环境布置入path之中,pandas安装可以在CMD中或者在Anaconda终端进行安装
安装命令
pip install pandas
Pandas的应用
- 导入pandas库
# 导入pandas库
import pandas as pd
- pandas之series
Pandas Series类似表格中的一个列(column),类似于一堆数组,可以保存为任何数据类型Series由索引(index)和列组成,函数如下:
pandas.Series(data, index, dtype, name, copy)
参数说明:
data:一组数据(ndarray 类型)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会自己判断。
name:设置名称。
copy:拷贝数据,默认为 False。
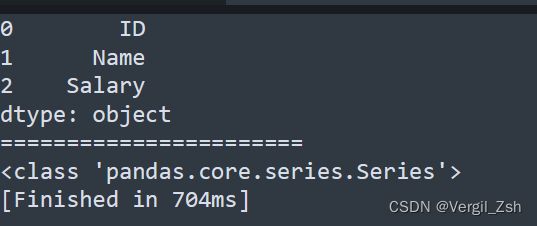
Demo:
import pandas as pd
a = ["ID", "name", "salary"]
salary_series = pd.Series(a)
print(salary_series)
print(type(salary_series)
代码结果:
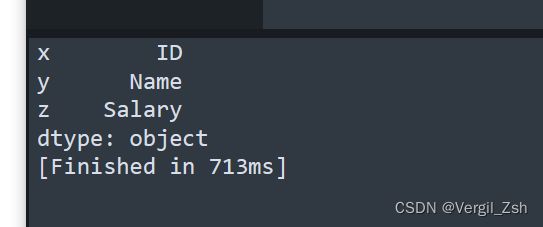
index参数
索引是可以修改的
索引只上图的最左边(0,1,2)
import pandas as pd
columns = ['ID', 'Name', 'Salary']
salary_series = pd.Series(columns, index=['x','y','z'])
print(salary_series)
使用字典, key/value对象, 创建Series
import pandas as pd
a = {1:'Name',2:'salary'}
series = pd.Series(a)
print(series)
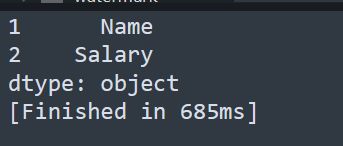
可以通过索引的指定来取值
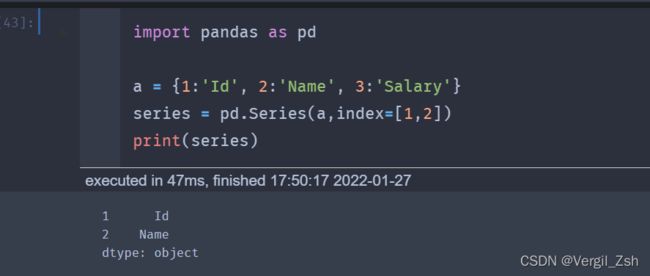
import pandas as pd
a = {1:'Id', 2:'Name', 3:'Salary'}
series = pd.Series(a,index=[1,2])
print(series)
- pandas之DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame既有行索引也有列索引,它可以被看做由 多个Series 组成的字典(共同用一个索引)。
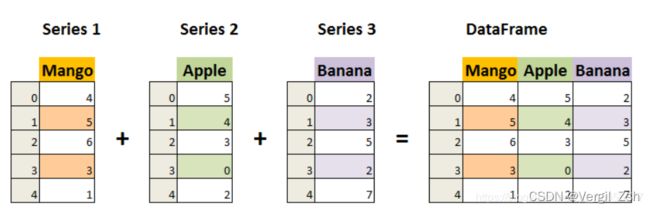
DataFrame构造方法如下:
pandas.DataFrame(data, index, column, dtype)
data:一组数据(ndarray、series, map, lists, dict 等类型)。
index:索引值,或者可以称为行标签。
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
dtype:数据类型。
Demo
- 指定列表
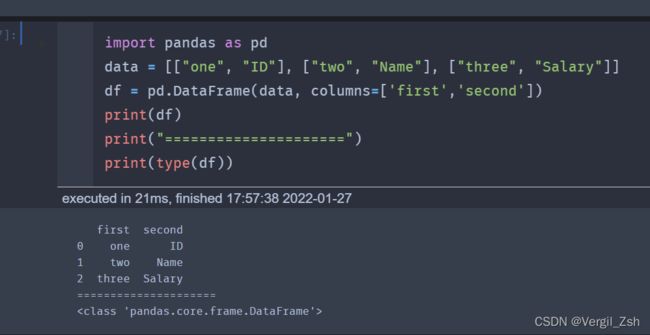
import pandas as pd
data = [["one", "ID"], ["two", "Name"], ["three", "Salary"]]
df = pd.DataFrame(data, columns=['first','second'])
print(df)
- 通过字典形式创建,列分开插入
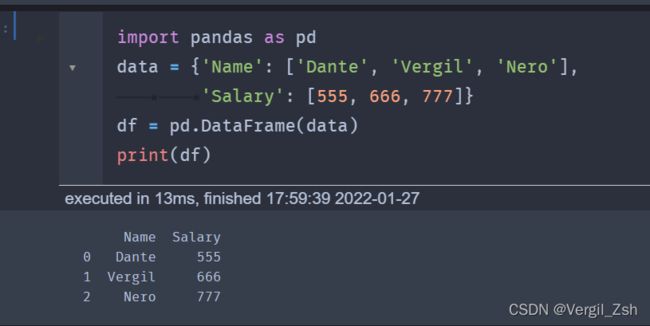
import pandas as pd
data = {'Name': ['Dante', 'Vergil', 'Nero'],
'Salary': [555, 666, 777]}
df = pd.DataFrame(data)
print(df)
- 使用字典 key/value,其中字典的key就是列名
import pandas as pd
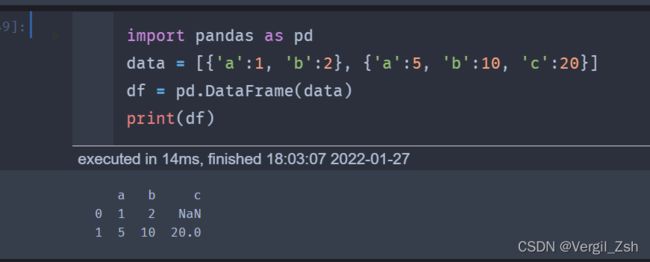
data = [{'a':1, 'b':2}, {'a':5, 'b':10, 'c':20}]
df = pd.DataFrame(data)
print(df)
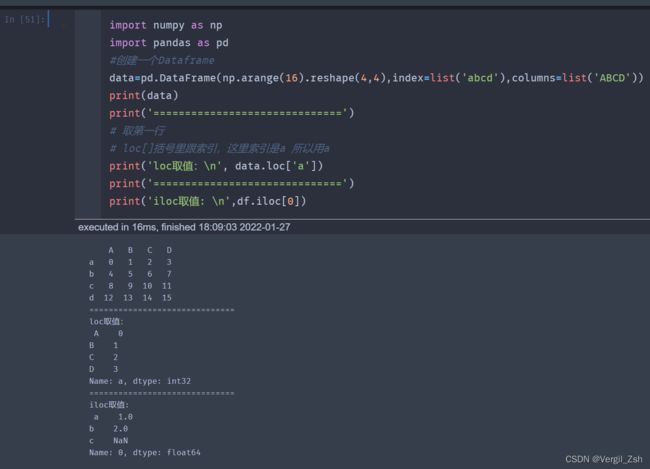
- 讲下取值使用的函数iloc和loc
import numpy as np
import pandas as pd
#创建一个Dataframe
data=pd.DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('ABCD'))
print(data)
print('==============================')
# 取第一行
# loc[]括号里跟索引,这里索引是a 所以用a
print('loc取值:\n', data.loc['a'])
print('==============================')
print('iloc取值: \n',df.iloc[0])
- 返回多行数据使用iloc或loc,使用[[:]]格式,以逗号隔开
import numpy as np
import pandas as pd
#创建一个Dataframe
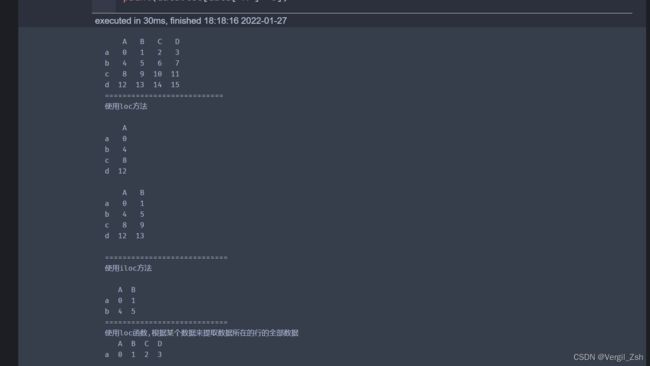
data=pd.DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('ABCD'))
print(data)
print('===========================')
print('使用loc方法\n')
print(data.loc[:,['A']],'\n')
#取'A'列所有行,多取几列格式为
print(data.loc[:,['A','B']],'\n')
data.loc[['a','b'],['A','B']]
#提取index为'a','b',列名为'A','B'中的数据
print('============================')
print('使用iloc方法\n')
#提取第0、1行,第0、1列中的数据
print(data.iloc[[0,1],[0,1]])
print('============================')
print('使用loc函数,根据某个数据来提取数据所在的行的全部数据')
print(data.loc[data['A']==0]