论文阅读《API2Com: On the Improvement of Automatically Generated Code Comments Using API Documentations》
第一篇论文笔记,感觉还是有点偏向于全文翻译+个人想法
文章链接:https://ieeexplore.ieee.org/document/9463033
笔记原链接:https://shimo.im/docs/dPkpKnywe6FMmJqO

Abstract
代码注释可以帮助理解程序,并且被认为是帮助开发人员进行软件维护的重要构件。然而,这些评论大多缺失或过时,特别是在复杂的软件项目中。
在本文中,作者提出了API2Com模型,这是一个利用应用程序编程接口文档(API Docs)作为注释生成知识资源的模型。API文档包含更详细的方法描述,因此可以注释。
作者将该模型应用于超过130000种方法的大型Java数据集,并使用Transformer和RNNbase架构对其进行评估。有趣的是,当使用API文档时,性能的提高可以忽略不计。因此,作者进行了不同的实验来解释结果。对于只包含一个API的方法,添加API文档会使结果平均提高4%的BLEU分数(BLEU分数是机器翻译中使用的自动评估指标)。然而,随着方法中使用的API数量的增加,由于输入中使用的文档较长,模型在生成注释时的性能会降低。作者的结果证实,API文档可以用于生成更好的评论,但是,需要新的技术来识别方法中信息量最大的文档,而不是同时使用所有文档。
索引术语:代码注释生成、API文档、外部知识源
I. Introduction
作者首先简述了代码注释对程序员的作用,其次作者提到了近年来主要的一个趋势是使用神经网络进行生成。而在此基础上,如果引入外部知识,将会对评论的质量有进一步的提高。
为此,作者提出了一个简单的例子,就以创建和写入json文件常用的FileWriter.write和FileWriter.flush这两个方法为例子,如果把他们的api文档的含义一并写出,那么他们生成的注释将会更客观。
具体的,作者举了两个例子如下:

这里的注释是从作者所使用的dataset里的,作者通过对比API文件与dataset中获取的注释综合考虑,认为如果结合API文档中的信息,注释将会更加客观。
尽管API的名称已在以前的工作中使用[21],但尚未对API的描述进行探讨。仅使用API名称可能无法正确交付代码的功能。相比之下,API文档基于自然语言,并包含更多细节,这对于生成全面的评论非常有用。因此,作者开发了API2Com,这是一个利用API文档丰富生成评论的模型。在该模型中,作者使用API文档、AST和源代码作为三编码器架构的输入。AST捕获了代码的结构表示,并在之前的一些相关研究中使用[11,16,17,18,19,22]。API文档与代码序列一起作为另一种资源添加,以生成注释。作者最初利用Transformer架构[23]来学习代码的语义表示。
第二节解释了选择Transformer而非其他架构的原因。作者对一个包含Husain等人[24]收集的137007条记录的大型Java数据集进行了研究,并进行了几个实验,以了解将API文档添加到模型后的效果
有趣的是,尽管作者使用了外部知识源,但作者的结果表明,性能的提高是微不足道的。因此,作者进行了更多的实验来分析结果,并在本文中报告作者的发现。作者发现,随着方法中使用的API数量的增加,API文档的价值会降低。这主要是因为当使用更多的API文档时,会向模型输入长文本。然而,评论和API文档之间的常用词数量极低。
当API文档的数量超过三个时,这会导致API文档增加噪声。作者使用门控递归单元(GRU)架构获得了类似的结果,虽然GRU比其他门控机制方法LSTM更有效[25]。
这些发现表明,API文档有助于改进评论,但应开发新技术仅包含信息性内容来进行处理。这些结果和作者的见解可能会使研究人员避免采用相同的方法,同时为集成API文档以生成评论开辟新的研究途径。
作者在本研究的贡献总结如下:

- 提出了一个Transformer模型,该模型将API文档与源代码和AST相结合,以生成注释。为此,作者提取代码段中使用的API的所有相应注释。
- 除了将API2Com与其他baseline进行比较之外,作者还进行了一些实验,以了解添加API文档的效果。
本文的其余部分组织如下。在第二节中,作者解释了其方法的细节,然后是第三节和第四节中的实验和结果。第五节对第四节中的结果进行一个系统性的讨论。第六节提到了对实验结果有效性的威胁。第七节总结了相关研究,第八节总结了本文。
II. Proposed Approach
A Overview
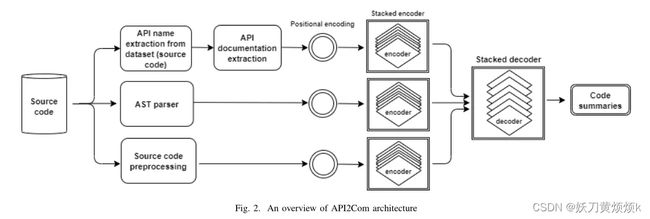
在该模块中,作者绘制出API2Com架构如下图2所示。API2Com由三个编码器组成,分别使用code tokens, AST traversal sequence(AST遍历序列), and a list of API documentations(API文档列表)作为三个不同编码器的输入。其中,AST表示代码的语法结构,并通过树遍历将其变平,以提供给模型;API文档是自然语言,是代码语义的补充。
在该模型中,源代码能够表示语法和语义表示,而加入AST和API文档丰富了这两种表示。这三个编码器具有相似的架构,这三个encoder的结果将会被连接并传递给解码器以生成注释。
B Transformer
基于RNN的神经网络主要利用编码器-解码器架构,其中编码器将输入序列映射到矢量,解码器使用编码器的矢量一次生成一个字的输出序列。在本文的工作中,transformer被用于编码器和解码器,它利用了多头自注意力multi-headed self-attention mechanism和位置编码positional encoding。具体的详细说明如下:
Encoder
编码器组合了多个相同的层,其中每个层由两个子层组成[23]。第一个子层包含多头自注意力机制,而另一个子层是全连接层。两个子层之后是另一层,该层会对每个子层的输出结果进行归一化处理
Decoder
与Encoder结构相似,但是Decoder在Encoder堆叠的子层之外,额外增加了一个子层对输出进行多头注意力机制处理
Multi-head attention mechanism
就是很普通的多头自注意力机制,作者没有在这部分进行改进,所以我在这里不过多赘述
可以看这个视频进行了解:https://www.bilibili.com/video/BV1sN4y1g768/?spm_id_from=333.337.search-card.all.click&vd_source=e7e66988b2137e8db93279ffe39c55e7
Positional Encoding
鉴于该模型不包括重复,需要考虑tokens的相对位置和绝对位置的一些信息,作者在这里使用了positional Encoding的技术。作者在这部分没有进行过多的改进,所以我在这里不过多赘述。
C API documentation
作者从JDK参考文档中提取每个方法中使用的每个API的API文档知识。JDK参考文档包含各种级别的文档,包括包、类和方法,但作者在API2Com模型中仅使用包含方法的文档。
在这里,作者以图1中左边的例子为例(如下图)

如图所示,该程序段包含了被列在 java.lang.reflect.Executable class的JDK文档下的api方法isSynthetic()。在该class的文档中包含两个方面:1)修饰符与类型 2)方法以及方法的描述。在这里,作者仅提取了方法及其描述方面的内容。以上图为例,作者提取了API文档中“Returns true if… returns false otrherwise.”这一部分的内容。
在此基础上,作者提取了方法中所有API中关于方法描述的内容(与上述例子异曲同工),并在拼接后用作模型的第一个编码器的输入使用。
III. Experiments
A. Dataset and Preprocessing
作者使用由Husain等人[24]引入的CodeSearchNet数据集的Java部分来训练和测试API2Com。该数据集在最近的研究中用于各种软件工程任务,包括注释生成[19,33],质量较高。具体而言,CodeSearchNet是一组数据集,最初是在Libraries.io的帮助下通过抓取开源GitHub存储库收集的。在此基础上,作者剔除了数据集中所有少于三行标记的注释和少于三行的代码,以确保数据集的质量。除此之外,作者将构造函数、扩展方法和名称中带有“test”的方法、重复项和自动生成的方法也一并从数据集中删除。
与Feng等人的工作类似[33],作者还将代码和注释的最大长度分别设置为256和64。由于无法为截断的代码生成AST,并且可能会导致有价值的信息丢失,因此作者必须排除代码或注释长度大于256或64的记录。由于某些模型使用AST,因此需要在所有模型之间进行公平比较。
表I显示了数据集的统计信息。数据集分为训练集、验证集和测试集,比例分别为8/1/1。作者使用训练集和验证集来训练模型,测试集用于评估。继之前的工作[16]之后,作者在训练之前进一步预处理数据集,将tokens分为使用CamelCase或Snakecase的tokens;并将所有tokens转换为小写;以及从代码中删除标点符号。
B. API Documentation Extraction
作者开发了一个scraper工具(scraper是一款网站数据提取工具,类似于爬虫,但不需要像python爬虫那样编写代码,使用门槛较低,适用于轻度的数据爬取)来下载JDK参考文档中每个模块和类中的所有API及其相应描述。为了从数据集中的方法中提取API名称,作者使用了srcML工具(来源:https://www.srcml.org/),它可以从源代码构建AST树,并将结果显示为XML标记。通过这样的表示方法,它能够表示出tokens的信息。就比如,如果它正在调用另一个函数,则可以将标记标记为“methodCall”。使用这些信息,作者可以通过遍历AST树来提取所有API名称。然后,作者将每个方法中使用的API名称与收集的数据集相匹配,以检索它们的描述。对于重载函数,则使用参数的数量来提取正确的文档。如果JDK参考文档中多次出现相同的API和不同的API文档,则使用频率最高的文档。
C. Model Training
为了训练模型,作者在第一个编码器中使用API Docs,第二个编码器使用扁平AST(flatten ast),最后一个编码器使用预处理的源代码。这三个编码器的结果被级联以作为单个输入传递给解码器。
D. Experiment setting
作者使用PyTorch框架进行模型的开发,将编码器和解码器层的数量设置为6,多头自注意力子层中的数量设置为8,使用初始速率为0.1的随机梯度下降优化器。
作者用UNK替换了词表外的tokens,隐藏状态和批次大小的维度分别设置为512和32。为了减少过度拟合的概率,作者使用值为0.1的丢弃率。训练共执行100个epoch,但如果学习率下降到 $ 10^{-7} $,训练就会停止,并基于验证数据集的损失函数值选择最佳epoch。
执行模型的设备:搭建NVIDIA Tesla V100 GPU和32 GB内存的Linux服务器。
E. Evaluation Metrics
与先前在代码注释生成中的研究类似[12,18,27],作者基于以下指标评估性能:BLEU[34],ROUGE-L[35]和METEOR[36],并给出了各指标的含义。
BLEU-n分数在简短惩罚[34]的帮助下量化了参考句子和预测句子之间的平均n-gram准确性,并报告了n∈ [1, 4]. ROUGE-L使用F分数,该分数被计算为通过查找文本的最长公共序列获得的召回和精度值的加权调和平均值[35]。METEOR是一种基于回忆的度量,它衡量模型在捕获参考句子内容方面的表现,并基于参考文本和预测文本之间相同的n-gram的数量[36]。
F . Baselines
在该模块中,作者使用处理后的CodeSearchNet数据集对AST-Attendgru、TL-CodeSum、Rencos、TransformerBased,以及API2COM的多个变体模型对API2COM模型进行测试。
在这里,个人认为需要对TransformerBased和API2COM的变体这两个模型进行一个具体的阐述。
TransformerBased模型:最早利用Transformer生成评论的研究之一。Ahmad等人[27]研究了transformer模型生成代码注释的有效性,并进一步将相对位置编码和注意力机制结合到transformer中,以提高生成评论的质量。
Variations of API2Com模型:在这里,作者使用API2Com的变体来比较其组件的有效性。
其中,API2COMbase是不使用AST和API Docs的Transformer架构模型,

API2COMast使用两个编码器来编码AST和输入代码,而不使用API Docs。
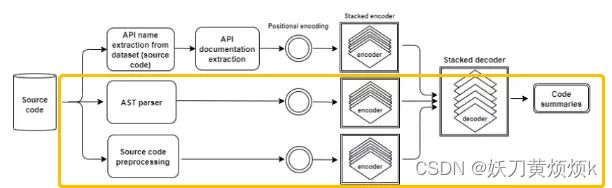
类似地,API2COMapi仅使用输入代码和API文档。
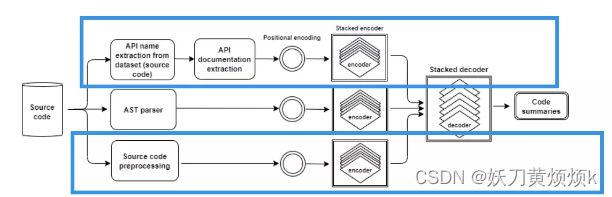
最后,API2COMfull是使用所有三个输入的模型,也就是下图所示的完整API2COM模型

IV. RESULTS
A. Research Questions

RQ1: How does our proposed approach perform compared to the baselines?
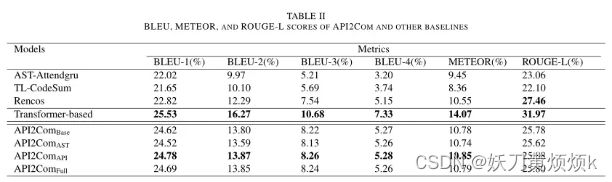
表2(如下图)展示了在测试集下各baseline各指标下的得分情况。
从下表中可以看出,Transformer-based模型在所有模型中表现最好,由于作者采用的是原始的transformer模型,而不是Transformer-based模型中改良过的版本,所以作者在后续也计划尝试将Transformer-based中的模型与本文中的方法结合起来。
其次,使用RNN架构的baseline效果对比起transformer效果较差,这也说明了transformer在处理这类任务效果更好。但有趣的是,作者将AST作为输入信息加入到transformer模型后,指标得分将会有轻微的降低(可以详细对比表中API2COMast和API2COMbase的数据)作者在这里给出的理由是:transformer架构具有能够捕获各tokens之间的关系的优势,所以加入AST会降低transformer的分析效果。
对于除ROUGE-L之外的所有指标,第二好的结果属于API2COMapi,其次是Rencos,AST-Attendgru和TL-CodeSum。
RQ2: What is the effect of each component of API2Com in generating comments?
为了研究API2COM的方法,作者也将各部分组件进行了测试并将数据放在了表2。除此之外,作者还将该方法应用在了GRU模型(替换transformer模型)上,从而进一步查看该方法的效果,并将其命名为API2COMS模型,在这部分的实验中,作者也采用了同样的方法对模型进行拆分,查看各部分的一个效果,并记录在了表3(如下所示)中。

通过对比可以证明,在两种架构中,如果结合AST都会在一定程度上降低模型的性能,而结合API文档则会提高指标下的得分。然而,通过数据的对比,作者可以发现这种变化都是比较不明显的。就算使用完整模型也只会在所有分数中有轻微的变化。值得注意的是,API2ComS的结果还略低于TL CodeSum。
综上所述,由于AST会在一定程度上降低模型的性能,所以在本文的其余部分,作者仅对API2COMbase和API2COMapi进行了实验。
RQ3: What is the effect of number of APIs on the performance of API2Com?
在这个研究问题中,作者研究了API2COMapi在数据集的不同子集中的性能:当一个方法具有一个API、两个API、三个API和四个或更多个API时。每一个方法都有可能利用1个到多个api来实现它的功能。
在API2Com中,作者在拼接后用作模型的第一个编码器的输入使用,这样的方式会导致多行的文档变得彼此相邻,并且可能会给注释添加噪声。这可能也是导致API2COM模型效果提升不明显的原因。
按我的理解的话,就比如在一个method中,同时调用了isSynthetic和setDefaultButton这两个api,而由于训练的时候没有划分各api数量的数据集,所以这两个api的名字和描述堆在一起,在生成的时候效果就会变差。
出于此原因,作者根据方法中使用的API的频率分割数据集来进行实验,表V显示了每次拆分中注释和API文档的平均长度。
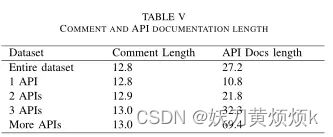
在此基础上,作者在新分离的数据集上训练和测试API2COMbase和API2COMapi模型。
结果列于表四。

表的最后一列显示了所有指标的改进得分的平均值。结果证实,添加API文档是有效的,尽管提升的效果很小。然而,随着API数量的增加,这种影响变得更小。
从表中可以看出,如果method中只使用一个api,那么在数据上平均能提高3.72%,两个API的性能能提高2.42%,三个API仅能提高1.09%。
不过这种影响可能与添加到输入中的API文档的长度有关,如表V所示。当使用一个API时,api文档的长度与代码注释的长度大致相同,而随着method中使用api数量的增多,api文档的长度将会远远长于代码注释的长度,这也会导致一定的负面效果。而由于数据集中使用三个以上API的methods占整个测试数据集的25%以上。这一较大比例会对RQ1和RQ2中报告的结果产生负面影响,所以综合数据上看,API2COMbase相比,API2COMapi的结果改善微不足道。
B:Human Evaluation
作者通过进行定性分析来评估结果。在这个实验中,作者随机抽取了100条记录,使得RQ3每个API都有相同数量的记录。每个样本由3名随机受试者进行评估,最后计算相同数量API的每组平均得分。总共有43名评估人员参加了这项调查。评估人员被要求与参考文本相比,对API2Comapi和API2ComBase每个生成的评论给出1到5之间的相似性评分。其中,1表示最低相似度,5表示最高相似度。API2Comapi和API2ComBase得到的分数分别为2.99和3.16,该结果证实,API2Comapi虽然能够改进了生成的评论,但改进效果一般。
如果将结果按API的数量进行划分,结果也与RQ3中的推论一致,当使用一个API时,两个模型之间的差异更大,API2Comapi将分数从3.08提高到3.39,而添加更多的API会降低效果。
但是与使用指标进行度量的结果相反,当使用3个以上API时,API2Comapi的人工评估平均得分为3.17,高于API2ComBase的2.73分。原因可能取决于这样一个事实,即在该模块中,该模型不基于API频率进行分离,但在RQ3中,模型是针对包含不同数量API的每个数据集单独训练的。作者出于对 API2Comapi的总体评估感兴趣并没有在这里分离模型进行单独训练。
V. DISCUSSIONS
Number of API Docs
作者在上述部分讨论了添加API文档可以改善生成的评论,只要链接的文档数量少于三个即可。
图3显示了四种方法及其来自数据集的参考注释、API2ComBase和API2COMapi生成的注释、每个方法中使用的API名称以及连接的API文档。

最顶上的方法只有一个API,API Doc能够帮助API2COMapi在注释中生成Returns true,效果较好。

左中方法有两个API。尽管第一个API(lastIndexOf)的文档有助于生成更好的注释,但第二个文档并没有让API2COMapi添加任何信息。

右中间的方法包含三个API,在这种情况下,API文档似乎给模型增加了噪音,因此无法帮助生成更好的注释。

最后,底部方法有六个API,这促使模型生成错误的注释。API2ComBase正在生成了正确的代码注释,而API2ComAPI被API文档误导,导致产生错误短语“xml文档”,效果较差。

API categories
为了探究API种类对结果的影响,作者随机选择了368种方法,使用Sample Size Calculator工具(https://www.surveysystem.com/sscalc.htm)制作了置信水平为95%,置信区间为5的具有代表性样本数量的测试集。
首先,作者选择了100个并不常见的随机样本,由两位在Java开发方面有三年经验的作者独立阅读了100种方法并定义了进行将要进行分类的类别(类别由Hu[37]等人的研究以及作者的探究结合得出),并按照讨论的类别将368种方法进行分类。分类结束后,再由一位有5年开发经验的人员对分号的类别进行检查,最终得到数据统计如表6所示。

对于每一个类别,作者进行了试验并分别计算了它们的BLEU分数,最后一组类别和每个类别中方法的数量如表VI所示。从表中可以看出,设置更新和算法这一类api的注释得分会增加,而对象创建/检索、字符串处理和文件操作的得分会降低。这种变化可能与每个类别中的文档有关,在某些类别中有所帮助,而在其他类别中信息较少。
作者通过手动研究样本的方式打算找到特定的模式,目的是确定增加特定类别中的API数量是否有助于改进结果。然而,当添加更多的API样本有助于生成更好的评论时,发现得分并没有像希望的那样越来越好。
作者将这种差异与两个原因联系起来。首先,仅依靠指标进行评分不是100%可靠的,因为它们并没有考虑文本的语义相似性[38]。其次,API文档在生成更好的注释方面的重要性很可能取决于该方法的功能性。
Low frequency words
通过观察,虽然API2Com的设计目的不是解决低频词的问题,但是作者发现添加api文档作为输入可以提高注释中出现低频词的次数,并列出了具体的相关数据,具体如下表所示。

Adverse effect
由于API的数量越多会降低模型的性能,因此需要设计一种仅检索关键信息的API的策略可能是一种更有效的方法,否则api数量的增多只会增加噪声,影响代码的生成。
VI. THREAT TO VALIDITY
Internal validity(内部有效性)
首先,作者的模型没有检查API之间的差异,而是考虑方法中使用的所有API的API文档,这可能导致发送到API编码器的数据重复性较高,从而进一步导致在生成使用三个以上的API的方法时注释效果的不佳。然而在实际操作的过程中,作者检查后发现在该情况下API2COMapi的效果并没有收到影响。
其次,作者考虑到在生成路径的过程中,并没有使用有助于调查不同的路径并产生更好的评论的beam search等搜索方法(https://zhuanlan.zhihu.com/p/82829880),这也可能会导致生成大量的重复词语进而导致得分的下降,但是作者经过手动检查后发现这样的情况并没有发生。
除此之外,作者还考虑到了baselines执行结果方面的问题,作者已经仔细检查了代码的正确性。为了运行基线,作者使用了模型的公开库,并使用了原作者建议的最佳参数来减轻baseline带来的影响。
External validity(外部有效性)
在该模型中,作者使用了大型高质量数据集来提高Java结果的有效性。然而,结果可能无法推广到其他编程语言。尽管如此,API2Com可以应用于其他语言,因为它不是仅针对JAVA语言来实现的,其他语言同样适用。
Construct Validity
在模型的评估中,作者不仅使用了BLEU, METEOR, and ROUGE-L作为指标对模型和baselines进行分析,而且还针对用户进行了定性分析,这能确保baselines和模型之间对比结果的准确性。
VII. RELATED WORKS
提了一些相关工作,这里直接进行翻译,不过多赘述。
VIII. CONCLUSION AND FUTURE WORKS
作者认为目前结果总体上并不乐观,但当一个方法中的API数量少于3个时,API文档可能会很有用。这些结果可以为新技术的研究开辟道路,以将API文档用于注释生成,例如为API类别添加权重或在方法中识别信息丰富的API。