《Mask RCNN》论文阅读笔记
论文阅读笔记
此篇论文为2017上 ICCV best paper,而且前面在学Mask Text SpotterV3网络的的过程中,也Mask Text SpotterV3在一定程度上是基于MaskRCNN的结构(字面意思理解,读完之后要论证一下),所以就拿来论文读一读。
该内容采用: 摘录重点部分+提出问题的方式,来阅读该篇论文。 后面会逐一的解答提出来的的问题。
make decision
-
论文名称:MaskRCNN
从论文题目中,说实在话得不出什么信息,也就是该网络与RCNN有一定的关系。 -
作者:Kaiming He, Georgia Gkioxari, Piotr Dollar, Ross Girshick
-
机构:Facebook AI
-
是否精读:是
-
做出决定日期:2021-4-14
-
Q1:该网络与RCNN有什么样的关系
A1:读完摘要后,我们可以回答这个问题。它是扩展了Faster-RCNN,增加了一个与现有的用于边界框识别分支并行的一个分支,该分支是用来预测segmentation mask的
step1:提出读过摘要后的问题
该网络是一个对象实例分割框架,Mask-RCNN扩展了Faster-RCNN,增加了一个与现有的用于边界框识别分支并行的一个分支,该分支是用来预测segmentation mask的。该分支在原有FasterRCNN上运行,只增加了5fps。然后就介绍在coco数据集上instance segmentation,boundingbox object detection和 person keypoint detection三大任务上,都有很好的成绩。
- Q2:该网络中怎样为每个实例生成高质量的segmentation mask呢
回答了第一个问题
- Q1:该网络与RCNN有什么样的关系
A1:读完摘要后,我们可以回答这个问题。它是扩展了Faster-RCNN,增加了一个与现有的用于边界框识别分支并行的一个分支,该分支是用来预测segmentation mask的
step2:读Introduction
在当时的阶段,用于目标检测的Fast/Faster RCNN网络 和 用于语义分割的Fully Convolutional Network(FCN)网络,可以快速的训练和推理,而且具有灵活性和鲁棒性。作者的目的就是为实例分割开发一个具有可比性的框架。
PS:在这里说明一下,语义分割,实例分割和全景分割是不同的。
- 语义分割:简单的将图片中同一种类的东西划分为一类
- 实例分割:不关注背景,但是同种类的各个物体也要进行分割
- 全景分割:也就是上面两个的结合
在论文中也有介绍, 实例分割要求正确检测图像中的所有对象,而且也需要精准的分割每个实例。语义分割是将每个像素分类成一组固定的类别,而不区别对象实例。
该网络扩展了Faster-RCNN,通过增加一个在每一个RoI上预测segmentation mask的分支,该分支与分类预测和边界框回归分支是并行关系。这个mask分支是一个小的FCN网络,该网络是应用在每个RoI上的,来预测像素级的segmentation mask。

文中提到fasterRCNN不是为网络输入的像素和输出的像素对齐设计的,这一点在RoIPool层上,表现得很明显。 事实上,该操作是关注的实例的核心操作,它对特征提取进行粗空间量化(coarse spatial quantization)。为了解决这个不对齐的问题,作者提出了一种简单的、无量化的层,称为RoIAlign,它会保留精确的空间位置信息。RoIAlign有两个主要的影响:第一:这样一个操作使mask的精度提高了相对10%~50%。 第二:必须将分割和分类预测进行分离(decouple),为每个类单独预测一个二进制mask,类之间不存在竞争,并依赖网络的RoI分类分支来预测类别。而FCN通常进行逐像素的多类分类,将分割和分类结合在一起,根据作者的实验,实例分割效果很差。
接下来作者主要说的的该网络的性能如何,在COCO各个任务中表现得有多好,等等。
- Q3:coarse spatial quantization粗空间量化究竟是什么意思?像素对齐又是什么意思?
- Q4:为每个类单独预测一个二进制mask,如何理解?
- Q5:ROI Pool和ROI Align的区别是什么?
A5: ROI Pool和ROI Align的区别
step3:读 Related works
R-CNN:主要介绍了R-CNN,Fast-RCNN,Faster-RCNN。先是在RCNN中应用边界框对象检测,再是再Fast-RCNN中,使用RoIPool处理特征图上的roi,从而提高了速度和准确性。最后在Faster-RCNN中,引入区域建议网络RPN机制。
Instance Segmentation:介绍了一些分割优先的方法,然后引出了实例优先的方法。所谓实例优先的方法,是由成功的语义分割驱动的,从逐像素分类结果开始(如FCN输出),试图将同一类别的像素分割到不同的实例总。MaskRCNN是基于实例优先的方法。
step4:读 MaskRCNN部分
MaskRCNN的输出是在FasterRCNN两个输出(分类预测和边界框偏移量)的基础上,额外的增加了第三个输出,object mask,其需要提取更加精细的对象空间布局(spatial layout of an object)
Faster-RCNN:有两个阶段,第一个阶段是区域建议网络RPN,来提出候选对象边界框。第二个阶段的本质是Fast-RCNN,使用RoIpool从每个候选框中提取特征,进行分类预测和边界框回归。
Mask RCNN:也采用相同的两个阶段,第一阶段RPN相同,在第二阶段中,在预测输出类别和边界框回归的同时,Mask-RCNN也为每个RoI输出了一个binary mask。
然后定义了损失函数
Mask Representation:mask对输入对象的空间布局进行编码。。mask的空间结构可以通过卷积提供的像素对像素来解决。 这种像素对像素的行为要求RoI特征(小特征映射)良好的对齐,因此就有了RoIAlign层
RoIAlign:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。
Network Architecture:为了演示Mask R-CNN的通用性,作者采用多种架构来实例化Mask R-CNN。 为了清楚的表示,我们用采用backbone卷积结构来提取整个图片的特征,head网络用来对每个ROI进行 分类和回归预测 与 mask预测
- 关于backbone部分:
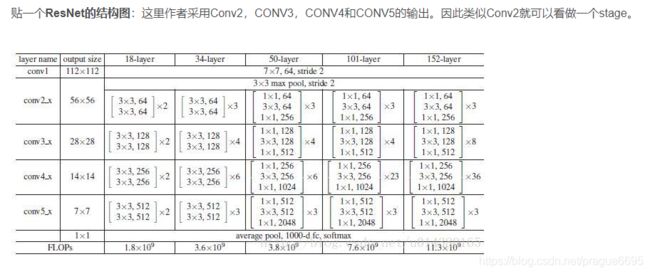
ResNet-50-C4:原始的FasterRCNN在使用ResNet50时,利用的是第四段卷积块的最后一层卷积层的输出。
在这里作者发现,Mask R-CNN使用ResNet-FPN backbone进行进行特征提取,在准确性上和 速度上都有很高的提高。 - 关于head部分:
作者添加了一个含有FCN的mask prediction分支。特别的,作者将基于ResNet和FPN的faster RCNN的box head部分进行了扩展,具体细节如下图所示,ResNet-C4 的 head 包含 ResNet 的第5个卷积块(即 9层的res5)这是 计算密集型(compute-intensive)程序. 对于FPN来说, 它的backbone就已经包含了res5, 因此可以具有效率更高的head(filers更少).
p.s.以上说的意思就是,ResNet50的前四个阶段在backbone里面了,然后在head部分中增加一个ResNet50的第五阶段即res5
论文中也指出,Mask R-CNN使用ResNet-FPN backbone来进行特征提取,在速度上和准确度上都有很好的效果。
FPN获得的性能优于ResNet的性能;主要是FPN使用金字塔特征结构,将low-level的特征与high-level的特征融合,能提取更加准确的位置等特征信息。 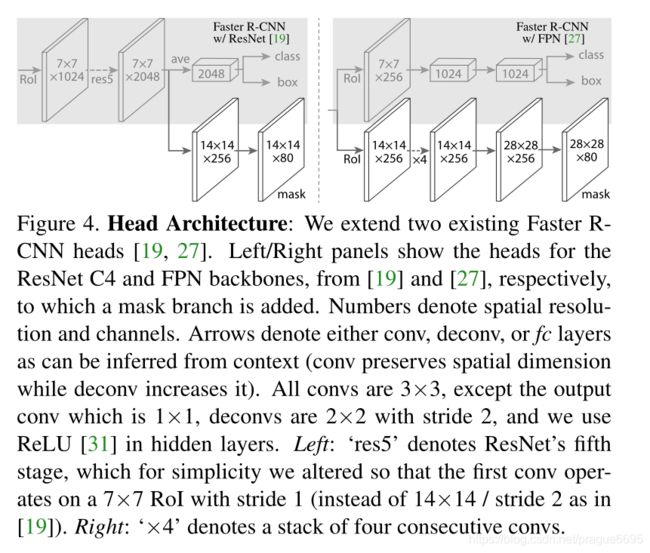
- Q6: mask的空间结构可以通过卷积提供的像素对像素来解决,这句话如何理解?
- Q7: 双线性插值是什么方法?
A7: 图像处理之双线性插值 - Q8: head如何理解?文中 the 5-th stage of ResNet(namely, the 9-layer‘res5’)
接下来就是一些实现细节和实验部分了。
step6: 总结反思
先引用别人的博客的总结

写这里我并没有发现什么问题,而这篇论文却发现了fasterRCNN中ROI pooling层存在由于粗量化导致RoI与pooling后的特征图谱之间的不对齐问题,从而提出了自己的改进方案。也想到把经典的目标检测算法FasterRCNN和经典的语义分割算法FCN进行了结合。FasterRCNN可以既快又准的完成目标检测的功能;FCN算法可以精准的完成语义分割的功能。
我们应该带着批判性的角度,带有创新型的想法,来进行学习,厚积薄发。
回答提出的问题
-
Q1:该网络与RCNN有什么样的关系
A1:读完摘要后,我们可以回答这个问题。它是扩展了Faster-RCNN,增加了一个与现有的用于边界框识别分支并行的一个分支,该分支是用来预测segmentation mask的 -
Q2:该网络中怎样为每个实例生成高质量的segmentation mask呢
A2:由FCN网络,使用卷积层对特征图进行上采样从而实现对图像进行像素级分类。 -
Q3:coarse spatial quantization粗空间量化究竟是什么意思?像素对齐又是什么意思?
A3:这是因为ROI Pooling层在原图转化为固定大小的特征图过程中,会有两次量化操作,从而使特征图无法对齐。像素对齐的意思就是将 固定大小的特征图的感受野能够准确无误的对应到原图上的boundingbox上。 -
Q4:为每个类单独预测一个二进制mask,如何理解?
A4:允许网络为每一类生成一个mask,而不用和其它类进行竞争;我们依赖于分类分支所预测的类别标签来选择输出的mask。这样将分类和mask生成分解开来。
mask分支的执行: mask分支的输出为针对每个RoI 有一个Km2-dimensional输出。掩码为二值掩码——只有0或1。只用来预测该像素级别的点是否为对象。
mask分支的损失计算: 利用平均二值交叉验证损失函数 (binary cross-entroy loss) ,并且根据每个RoI所关联的类别k,只计算该类别k对应的mask损失计算,其他非k的mask不参与损失计算,也就是每个ROI只计算(1,1,m,m)大小的损失。 -
Q5:ROI Pool和ROI Align的区别是什么?
A5: ROI Pool和ROI Align的区别 -
Q6: mask的空间结构可以通过卷积提供的像素对像素来解决,这句话如何理解?
A6:这就是FCN网络结构的特性。 -
Q7: 双线性插值是什么方法?
A7: 图像处理之双线性插值 -
Q8: head如何理解?文中 the 5-th stage of ResNet(namely, the 9-layer‘res5’)
A8:head个人理解就是预测输出的部分。 文中 the 5-th stage of ResNet表示ResNet的第五阶段的输出。
参考
FCN
FCN(一般是对图像进行语义分割的)是对图像进行像素级分类,可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生一个预测,同时保留了原始输入图像中的空间信息,最后再上采样的特征图上进行像素级分类。
FCN与CNN的核心区别就是FCN将CNN末尾的全连接层转化成了卷积层
FPN
关于多尺度的object detection算法:FPN(feature pyramid networks)。原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的。
代码的话应该过段时间就会开源。
看下图 第五阶段清晰明了
TensorFlow实战:Chapter-8上(Mask R-CNN介绍与实现)
Mask R-CNN详解
Mask RCNN阅读笔记