Paddle目标检测学习笔记
目标检测 学习笔记
来自课程:百度AI Studio课程_学习成就梦想,AI遇见未来_AI课程 - 百度AI Studio - 人工智能学习与实训社区 (baidu.com)的学习笔记
文章目录
- 目标检测 学习笔记
-
- 发展历程
-
- **Viola Jones Detectors:**
- **HOG Detector:**
- **DPM(Deformable Part Model):**
- **YOLOv3**:
- Fast R-CNN
- **Faster R-CNN**:
- FPN:
- **Cascade R-CNN**:
- Libra R-CNN:
- Faster R-CNN简析
-
- RPN
- 生成Proposals
- BBox Head
- 补充
发展历程
参考[1905.05055] Object Detection in 20 Years: A Survey (arxiv.org)综述,如图所示(图源论文):

在2012年AlexNet横空出世之前,物体检测主导方法都还是利用人工设计的特征,比如:
Viola Jones Detectors:

在2001年,Viola 和 Jones 在CVPR上发表了经典的《Rapid Object Detection using a Boosted Cascade of Simple Features》和《Robust Real-Time Face Detection》,提出了Viola-Jones检测器。VJ框架在AdaBoost算法的基础上,使用Haar-like小波特征和积分图技术来进行人脸检测。
VJ Det.采用最直接的检测方法,即,利用滑动窗口查看图像中所有可能的位置和比例,看看是否有窗口包含人脸。它通过结合“积分图像”、“特征选择”和“检测级联”三种技术,在当时大大提高了检测速度。
HOG Detector:

HOG Det.利用方向梯度直方图(HOG)特征描述符作为新的特征描述。同时,为了检测不同大小的对象,HOG Det.在保持检测窗口大小不变的情况下,对输入图像进行多次重标**。**
DPM(Deformable Part Model):

正如其名称所述,可变形的组件模型,是一种基于组件的检测算法,其所见即其意。该模型由大神Felzenszwalb在2008年提出,发表了一系列的cvpr,NIPS。并且还拿下了2010年,PASCAL VOC的“终身成就奖
DPM算法采用了改进后的HOG特征,SVM分类器和滑动窗口检测思想,针对目标的多视角问题,采用了多组件的策略,针对目标本身的形变问题,采用了基于图结构的部件模型策略。
2012年之后,在深度学习进入这一领域,诞生了很多优秀的算法,这里我将选取了一些我个人很仰慕的典型的算法。
单阶段*(one-stage)*
YOLOv3:
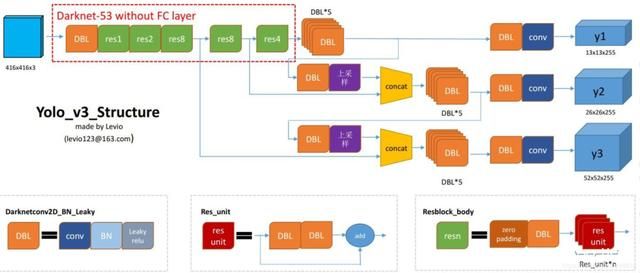
YOLO系列中,我感觉YOLOv3的应用最广。不同于两阶段的算法,YOLO将候选区和对象识别这两个阶段合二为一 ,将图像分为多个区域,同时预测多个区域的边界框和概率。YOLOv3中,未解决多尺度问题,使用FPN用不同尺寸特征图进行预测。
两阶段*(two-stage)*
R-CNN**:**对每张图通过 Selective search提取2000个候选区域,每个区域被 warped到卷积网络要求的输入大小,然后通过卷积网络得到一个输出作为这个区域的特征。使用这些特征来训练多个SVM来识别物体,每个SVM预测一个区域是不是包含某个物体。最后,使用这些区域特征来训练线性回归器来对区域位置进行调整。

- 每张图会通过 Selective Search提取2000个候选区域
- 每个区域被 warped到卷积网络要求的输入大小,然后通过卷积网络得到一个输出,作为这个区域的特征
- 使用这些特征来训练多个svm来识别物体,每个sm预测一个区域是不是包含某个物体
- 使用这些区域特征训练线性回归器,对区域位置调整
存在问题:
- 每个候选区的需要单独过CNN,计算量大
- Selective Search提取的区域质量不好
- 特征提取、SVM分类器是独立训练而非联合训练,耗时长
Fast R-CNN

改进:
- RoI Pooling:将每个区域内均匀分成若干小块,每个小块得到该区域内的最大值
- Softmax+regressor:可以联合训练
Faster R-CNN:
针对Fast R-CNN中提取候选区域耗时长的不足,Faster R-CNN在产生候选区域时,使用 Anchor + RPN网络替代 Selective Search选取候选区域,选出包含物体的 Anchor进入RoI Pooling提取特征。在第二阶段,对候选区域进行分类并预测目标物体位置。

改进:
RPN替代Selective Search,用于提取候选区域
FPN:
构造多尺度金字塔,期望模型能够具备检测不同大小尺度物体的能力
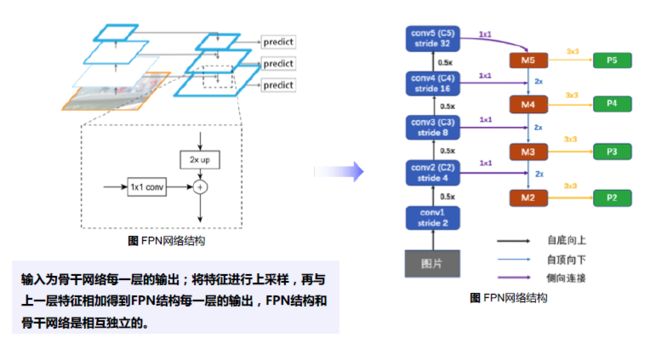
- Anchor:{322,642,1282,2562,5122}{P2,P3,P4,P5,P6}
- RPN网络分为多个head预测不同尺度上的候选框
- RPN网络的预测结果和 anchor解码得到的R会进行合并
Cascade R-CNN:

在Faster R-CNN中,RPN提出的proposals大部分质量不高,导致没办法直接使用高阈值的detector。为解决此问题,Cascade R-CNN引入多个head对RoI进行微调,每次 BBox head的偏移量和RoI解码作为下个阶段的RoI输入。
Libra R-CNN:

摘要:
相比于模型结构,相比之下如何对模型进行训练这一方面受到的关注比较少,但是其对于目标检测任务来说同样的重要。作者回顾了检测器的标准训练过程,发现了检测性能往往受到训练过程中不平衡的限制,而这种不平衡一般由三个层次组成:样本层(sample level)、特征层(feature level)和目标层(objective level)。
为了解决这个问题,作者提出了Libra R-CNN,用来平衡训练过程。Libra R-CNN由三个新组建构成:IoU平衡采样(IoU-balanced sampling)、平衡特征金字塔(balanced feature pyramid)和平衡L1损失(balanced L1 loss),分别用于降低采样、特征和目标三个层次的不平衡。
***AnchorFree****系列*
CornerNet:

将目标检测问题当作关键点检测问题来解决,也就是通过检测目标框的左上角和右下角两个关键点得到预测框。简单来说,CornerNet预测左上角和右下角两个关键点,再将其通过Embedding,将距离近的关键点组成预测框。
FCOS:

FCOS是基于FCN的逐像素目标检测算法,实现了anchor-free\proposal free的解决方案。简单来说,FCOS的核心思想是预测点和点到目标框四边的距离。
Faster R-CNN简析
第一阶段:产生候选区域
- 使用 Anchor替代 Selective search,选取候选区域
- 选出包含物体的 Ancho进入Rol Pooling提取特征
第二阶段:对候选区域进行分类并预测目标物体位置
RPN
结构:

训练:
- 向RPN网络输入一个监督信息,判断 Anchor.是否包含物体。
- Anchor包含物体-正样本
- Anchor不包含物体-负样本
- 根据Anch和真实框loU取值,判断正or负样本
- 正样本:
- 与某一真实框loU最大的 Anchor
- 与任意真实框loU>07的 Anchor
- 负样本:
- 与所有真实框的loU<0.3的 Anchor
- 采样规则:
- 共采样256个样本
- 从正样本中随机采样,采样个数不超过128个
- 从负样本中随机采样,补齐256个样本
loss
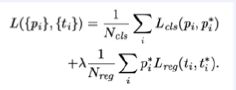
生成Proposals

RoI pooling
候选框分为若干子区域,将每个区域对应到输入特征图上,取每个区域内的最大值作为该区域的输出。
不足:
在两次取整近似时,导致检测信息与提取出的特征不匹配
解决:RoI Align
BBox Head
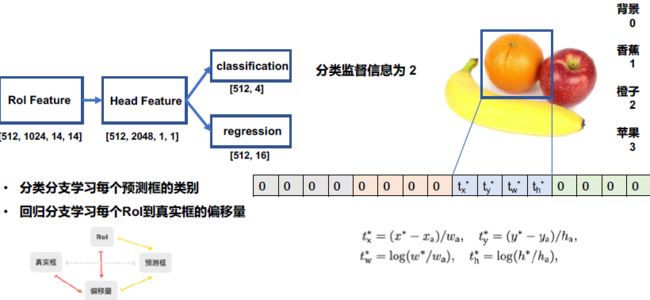
补充
Q:请分别列举你所认为的当前最先进的目标检测方法,并解释为什么该方法的是当前最先进的方法?在原理上,该方法做了什么创新?
EfficientDet
来自[1911.09070] EfficientDet: Scalable and Efficient Object Detection (arxiv.org)
主要贡献点是BiFPN和Compound scaling方法,具体我也没有精读,下面是我对其直观的理解。
BiFPN是在FPN的基础上对其进行改进,对原始的FPN模块又添加了添加上下文信息的边,并对每个边乘以一个相应的权重。
Compound scaling方法是一种复合特征金字塔网络缩放方法,统一缩放所有backbone的分辨率、深度和宽度、特征网络和box/class预测网络。
今年的单阶段算法TOOD(来自[2108.07755] TOOD: Task-aligned One-stage Object Detection (arxiv.org)),在COCO数据集上刷新了单阶段目标检测新纪录,但我还没有去了解。
特征金字塔网络缩放方法,统一缩放所有backbone的分辨率、深度和宽度、特征网络和box/class预测网络。
今年的单阶段算法TOOD(来自[2108.07755] TOOD: Task-aligned One-stage Object Detection (arxiv.org)),在COCO数据集上刷新了单阶段目标检测新纪录,但我还没有去了解。