Spring Batch 入门
一、应用场景
在银行、电信等一些大型的企业应用上,经常需要处理大批量的数据。比如,银行的交易流水文件的处理等。这些大批量数据的处理有一些共同点,从文件或数据库中读取数据,进行加工处理,再写入到文件或数据库中。Spring Batch 正是完成这样的功能。Spring Batch 的出现,让我们可以专注业务编程,而不去关心批量如何执行。
Spring Batch 的主要功能:
1、与quartz整合,实现定时批任务处理;当然,spring batch 内部也有集成调度框架,不过没有quartz强大。
2、可以并行处理批任务;
3、可以按顺序定义相关的处理步骤;
4、支持事务;
5、支持对批任务的失败重试;
.......
二、基本架构
官网上,spring batch 的架构图如下:
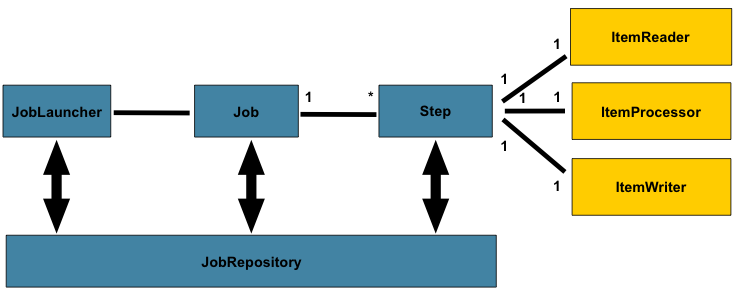
简单点说,JobRepository 用于存放批处理的结果,不管成功或者 失败,都会保存在JobRepository 中。JobRepository 可以是内存,也可以是数据库。
而JobLauncher则用于启动一个批任务。
Job、step需要程序员自己定义,一个job可以有多个step,而一个step下,又分别包含一个ItemReader、ItemProcessor、ItemWriter,这三个接口用于读取文件(或数据库)、处理读取的内容(对数据进行加工)、处理后的写入操作(可以简单打印,也可以进行持久化)。
有些简单的批处理任务,可以不要中间的ItemProcessor,这表示读取到的文件可以直接给ItemWriter进行输出或持久化。
下面用一个简单的小程序展示以上这几个类及接口的使用。
三、入门程序
以下展示一个Spring Batch 的简易程序。主要的业务场景是:从文件中读取出学生的信息,根据学生的成绩生成学生的成绩等级,然后打印输出。
项目的目录结构如下:

主要的java类介绍:
其中Bootstrap 是启动类,Student是学生pojo类,StudentProcessor是处理学生信息的处理器类,StudentWriter 是输出学习信息的类。
下面是源代码及解析。
1、首先,配置一个批处理的上下文job-context.xml,配置一个jobRepository,以及jobLauncher。transactionManager 是一个事务管理器。
JobRepository存储执行期的元数据,提供两种默认实现,一种是存放在内存中,默认实现类为:MapJobRepositoryFactoryBean(即本示例的配置)。
另一种是存入数据库中,可以随时监控批处理Job的执行状态,查看Job执行结果是成功还是失败,并且使得在Job失败的情况下重新启动Job成为可能。
2、接着,编写一个Student的pojo类。为了节省篇幅,我把getter、setter都省去了。
package example.ch01;
/**
* @author maplezhang
* @date 2019/11/14
*/
public class Student {
private String name;
private int score;
private String grade;
public Student() { }
public Student(String name, int score) {
this.name = name;
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", score=" + score +
", grade='" + grade + '\'' +
'}';
}
}3、造一个纯文本文件,里面是学生的基本信息,包括学生的姓名和分数,grade则后面由程序计算得出,因此不会在文本中给出。具体数据见:student_info.txt
张三,99
李四,52
王五,86
赵六,75
刘七,604、有了文件,则需要一个读取文件的读取器,对应上面框架图中的ItemReader。ItemReader是一个接口。
但这里,我们不需要编写自定义的ItemReader, SpringBatch已经提供了一个类FlatFileItemReader用于读取txt文件。
FlatFileItemReader用于读取Flat格式的文件,什么是Flat格式的文件?
Flat文件是一种包含没有相对关系结构的记录的文件。可以简单理解为纯文件的文件,如txt,csv等格式的文件就是Flat文件。
5、处理器ItemProcessor,这是我们编写业务处理代码的地方,需要我们自己定义,类是StudentProcessor。代码如下:
package example.ch01;
import org.springframework.batch.item.ItemProcessor;
/**
* @author maplezhang
* @date 2019/11/15
*/
public class StudentProcessor implements ItemProcessor {
public Student process(Student student) throws Exception {
int score = student.getScore();
if(score >= 90) {
student.setGrade("A");
} else if(score >= 80) {
student.setGrade("B");
} else if(score >= 70) {
student.setGrade("C");
} else if(score >= 60){
student.setGrade("D");
} else {
student.setGrade("E");
}
return student;
}
} 这是我们处理学生分数的逻辑。
当然,如果在某些场景下,你认为不需要对数据进行处理,只需要用ItemReader将数据读入并传送给ItemWriter,则processor可以省去,这并不是必须的。
6、输出器ItemWriter,我们想把Student的信息简单地输出即可,所以StudentWriter 也很简单,代码如下:
package example.ch01;
import org.springframework.batch.item.ItemWriter;
import java.util.List;
/**
* @author maplezhang
* @date 2019/11/15
*/
public class StudentWriter implements ItemWriter {
public void write(List list) throws Exception {
System.out.println(list);
}
} 7、定义完相应的Reader、Writer、Processor后,我们需要加配置文件,才能用上这些类。
配置文件是:job.xml。
name
score
在这个文件里,首先要定义本次批处理的任务及步骤,可以看到,我们定义了一个任务job,名称是 job1;
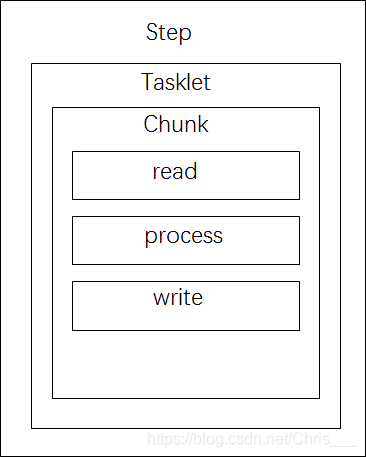
该任务下有一个步骤Step,名称是step1,step下是一个tasklet, tasklet下是一个chunk, chunk里面配置着刚才定义的reader、processor、writer,还有一个commit-interval。
上文我们提过,Job下可包含多个step,但因为本次示例过于简单,所以只有一个step。
step、tasklet、chunk等的关系如下图所示:
关于commit-interval
commit-interval 表示提交的间隔,意思是每读取、处理n条数据,才进行一次写入,n就是commit-interval的值。
官方文档如下描述:
Once the number of items read equals the commit interval, the
entire chunk is written out by the ItemWriter, and then the transaction is committed. The following
image shows the process:
Figure 14. Chunk-oriented Processing
The following code shows the same concepts shown:
The following code shows the same concepts shown:
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read()
Object processedItem = itemProcessor.process(item);
items.add(processedItem);
}
itemWriter.write(items);

题外话:读者可以试试,把上面的commit-interval值改成其它数字,看是否会有不同的执行结果。
如果commit-interval != 1,则需要在配置student 这一bean时,将作用域指定为 prototype,即student bean 要如下配置:
如果Student作用域不配置为原型,则默认的作用域是单例模式,那么当commit-interval>1时(假设commit-interval=n),spring batch 会循环n次,读取多个文件记录;然而,每次将文件记录映射到java 对象时,从容器中取出的student 对象,都是同一个对象(单例模式)。这就导致student信息会不断被覆盖,最终的结果就是传到 ItmProcessor 的student信息会出现重复。
解决办法如上所述,将student的bean作用域 设置为 prototype。
事务的隔离机制
关于作用域
在上面配置FlatFileItemReader 的代码中,可以看到scope='step',表示该bean的作用域 是step。
以下引用《spring batch 批处理框架》中的解释:

FlatFileItemReader 的具体配置
参考job.xml代码的注释
四、运行结果
---------------------------------- start batch job ------------------------------
十一月 20, 2019 4:22:06 下午 org.springframework.batch.core.launch.support.SimpleJobLauncher$1 run
信息: Job: [FlowJob: [name=job1]] launched with the following parameters: [{}]
十一月 20, 2019 4:22:06 下午 org.springframework.batch.core.job.SimpleStepHandler handleStep
信息: Executing step: [step1]
[Student{name='张三', score=99, grade='A'}]
[Student{name='李四', score=52, grade='E'}]
[Student{name='王五', score=86, grade='B'}]
[Student{name='赵六', score=75, grade='C'}]
[Student{name='刘七', score=60, grade='D'}]
十一月 20, 2019 4:22:06 下午 org.springframework.batch.core.launch.support.SimpleJobLauncher$1 run
JobExecution: id=0, version=2, startTime=Wed Nov 20 16:22:06 CST 2019, endTime=Wed Nov 20 16:22:06 CST 2019, lastUpdated=Wed Nov 20 16:22:06 CST 2019, status=COMPLETED, exitStatus=exitCode=COMPLETED;exitDescription=, job=[JobInstance: id=0, version=0, Job=[job1]], jobParameters=[{}]
---------------------------------- end batch job ------------------------------
参考:
1. spring batch 官方文档:
https://docs.spring.io/spring-batch/docs/4.2.x/reference/pdf/spring-batch-reference.pdf
2. 《Spring batch 批处理框架》