撕起来了!谁说数据少就不能用深度学习?这锅俺不背!
原文地址:Don’t use deep learning your data isn’t that big
作者:Andrew L. Beam
编译:AI100
撕逼大战,从某种角度,标志着一个产业的火热。
最近,大火的深度学习,也开始撕起来了。
前几日,有一篇帖子在“Simply Stats”很火,作者Jeff Leek在博文中犀利地将深度学习拉下神坛,他谈到了深度学习现在如何狂热,人们正试图用这个技术解决每一个问题。但是呢,只有极少数情况下,你才能拿到足够的数据,这样看来,深度学习也就没那么大用处了。
帖子原文标题为“Don’t use deep learning your data isn’t that big.”(即数据不多时,就别用深度学习了),喜欢看热闹的,不妨搜一下。
帖子一出,人们就炸开了。
这里面就有牛人就看不惯了,直接怼起来!

哈佛大学生物医药信息学的专业的博士后专门写了篇文章来反驳:You can probably use deep learning even if your data isn’t that big.(即便数据不够,也能用深度学习)
谁说数据少就不能用深度学习了,那是你根本没搞懂好吗?
(嗯,深度学习默默表示,这锅俺不背)

来我们先来看一下正反方的观点:
正方:
原贴观点:倘若你的样本数量少于100个,最好不要使用深度学习,因为模型会过拟合,这样的话,得到的结果将会很差。
反方:
模型表现很差并不是由过拟合引起的。没能收敛,或者难以训练很可能才是罪魁祸首。你正方因此得出这样的结论,是因为你实验本身的问题。方法用对了,即使只有100-1000个数据,仍然可以使用深度学习技术,得到好的结果。
(到底谁在扯淡?这场争论有没有意义?谁的实验更有道理?欢迎各位牛人在留言区拍砖)
以下,AI100专程对反方的观点及研究进行了全文编译,略长,但,很有意思。准备好围观了吗?出发!
以下对反方内容的全文编译:
老实讲,原文中的部分观点,我也算是认同,不过,有一些事情需要在这篇文章中进行探讨。
Jeff做了一个关于辨识手写数字0和1的实验,他的数据源是来自大名鼎鼎的MNIST数据集。
此次实验,他采用了两种方法:
- 一种方法采用的是神经网络模型,共5层,其中激活函数是双曲正切函数;
- 另一种方法使用的是李加索变量选择方法,这种方法思想就是挑选10个边际p值最小的像素来进行(用这些值做回归就可以了)。
实验结果表明,在只有少量的样本的情况下,李加索方法的表现要优于神经网络。
下图是性能表现:
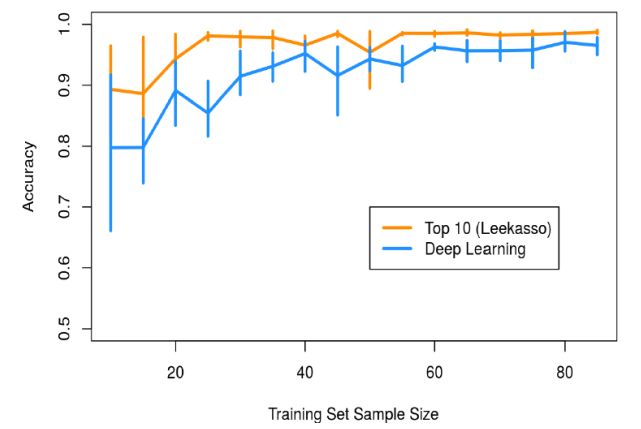
很惊奇对不对?
的确!倘若你的样本数量少于100个,最好不要使用深度学习,因为模型会过拟合,这样的话,得到的结果将会很差。
我认为在这里需要仔细探讨一下。深度学习模型很复杂,有很多的训练技巧。我觉得模型表现很差并不是由过拟合引起的,没能收敛,或者难以训练很可能才是罪魁祸首。
Deep Learning VS Leekasso Redux
我们首先要做的事情就是构建一个使用MNIST数据集,并且可用的深度学习模型。一般来说我们所使用的就是多层感知机与卷积神经网络。倘若原帖思想是正确的话,那么当我们使用少量样本来训练我们的模型的话,那么我们的模型将会过拟合。
我们构建了一个简单的多层感知机,使用的激活函数是RELU。于此同时,我们还构建了一类似VGG的卷积神经网络。将这两个神经网络模型的表现同李加索(Leekasso)模型进行对比。你可以在这里获取相关代码。非常感谢我的暑期实习生Michael Chen。他做了大部分的工作。使用的语言是python,工具是Keras。
代码获取地址:https://github.com/beamandrew/deep_learning_works/blob/master/mnist.py
MLP是标准的模型,如下面代码所示:

我们的CNN模型的网络结构,如下面所示(我想很多人对此都很熟悉)

作为参考,我们的多层感知机MLP模型大概有120000个参数,而我们的CNN模型大概有200000个参数。根据原帖中所涉及的假设,当我们有这么多参数,而我们的样本数量很少的时候,我们的模型真的是要崩溃了。
我们尝试尽可能地复原原始实验——我们采用5折交叉验证,但是使用标准的MNIST测试数据集做为评估使用(验证集中0与1样本的个数大概有2000多个)。我们将测试集分成两部分。第一部分用来评估训练程序的收敛性,第二部分数据用来衡量模型预测的准确度。我们并没用对模型进行调参。对于大多数参数,我们使用的都是合理的默认值。
我们尽我们最大的努力重写了原贴中的Leekasso和MLP代码的python版本。你可以在这里获得源码。下面就是每个模型在所抽取的样本上的准确率。通过最下面的放大图,你能够很容易的知道哪个模型表现最好。

是不是很惊奇?这看上去和原帖的分析完全不同!原帖中所分析的MLP,在我们的试验中,依然是在少量数据集中表现很差。但是我所设计的神经网络在所使用的样本中,却有很好的表现。那么这就引出了一个问题……
到底在我们的实验中发生了什么?
众所周知,深度学习模型的训练过程是一个精细活,知道如何“照顾”我们的网络是一个很重要的技能。过多的参数会导致某些特定的问题(尤其是涉及到SGD),倘若没有选择好的话,那么将会导致很差的性能,以及误导性。当你在进行深度学习相关工作的时候,你需要谨记下面的话:
模型的细节很重要,你需要当心黑箱调用那些任何看起来都像是deeplearning()的东西。
下面是我对原帖中问题的一些猜想:
- 激励函数很重要,使用tanh作为激励函数的神经网络很难训练。这就是为什么当我们使用Relu函数作为我们的激活函数,会有很大进步的原因了。
- 确保随机梯度下降能够收敛。在原始实验对照中,作者仅仅训练了20轮,这样的话,可能是训练的次数不够。仅仅有10个样本,仅仅训练了20轮,那么结果是我们仅仅进行了200次的梯度更新。然而要想完整的训练一遍我们所有的数据,我们需要6000次的梯度更新。进行上百轮、上千轮训练是很正常的。我们大概会有1000000梯度更新。假若你仅仅打算进行200次的梯度更新,那么你可能需要很大的学习速率,否则的话,你的模型不太可能会收敛。h2o.deeplearning()默认的学习速率是0.005。假若你仅仅是更新几次的话,这个学习速率就太小了。我们使用训练200轮的模型,我们会看到在前50轮,模型在样本上的准确率会有很大的波动。所以,我觉得模型没有收敛在很大程度上能够解释原贴中所观察到的差异。
- **需要一直检查参数的默认值。**Keras是一个很好的工具。因为Keras会将参数设置成它觉得代表当前训练的最好的默认值。但是,你仍然需要确保你所选择的参数的值匹配你的问题。
- 不同的框架会导致不同的结果。我曾尝试回到原始的R代码,以期望得到最后的结果。然而,我无法从h2o.deeplearning()函数中得到好的结果。我觉得原因可能涉及到优化过程。它所使用的可能是Elastic Averaging SGD,这种方法会将计算安排到多个节点上,这样就会加速训练速度。我不清楚在仅有少量数据的情况下,这种方法是否会失效。我只是有这个猜测而已。对于h2o我并没有太多的使用经验,其他人也许知道原因。
幸运的是,Rstudio的好人们刚刚发布了针对于Keras的R的接口。因此我可以在R的基础上,创建我的python代码了。我们之前使用的MLP类似于这个样子,现在我们用R语言将其实现。

我将这个代码改成了Jeff的R代码,并重新生成了原始的图形。我同样稍微修改了下Leekasso的代码。我发现原先的代码使用的是lm() (线性回归),我认为不是很好。所以我改成了glm()(逻辑回归)。新的图形如下图所示:
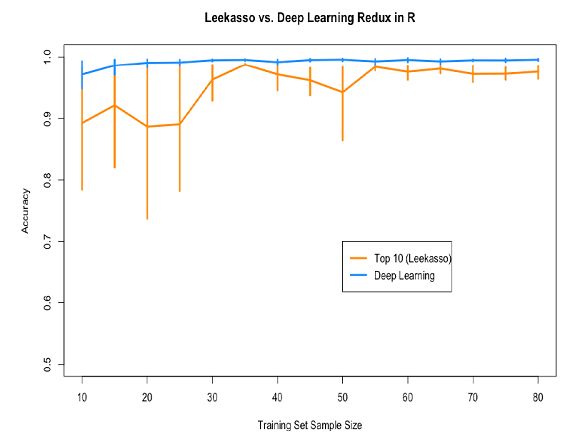
深度学习胜利了!类似的现象可能表明python与R版本的Leekasso算法不同之处。Python版本的逻辑回归使用的是liblinear来实现,我觉得这样做的话,会比R默认的实现方式更加的健壮,有更强的鲁棒性。因为Leekasso选择的变量是高度共线的,这样做也许会更好。
这个问题意义非凡:我重新运行了Leekasso,但是仅使用最高的预测值,最终的结果和完整的Leekasso的结果一致。事实上,我认为我可以做出一个不需要数据的分类器,这个分类器会有很高的准确率。我们仅仅需要选择中心的像素,假若它是黑色的话,我们就可以认为它是1,否则的话就预测是0。正如David Robinson所指出的:

David同样认为对于大部分的数字对儿,我们只需使用一个像素就能分开。因此,那个帖子反映的问题看上去并不能反应数据很少的情形。我们对他得出结论最好有所保留。
为什么深度学习会产生误解?
最后,我想在重新回顾一下Jeff在他原帖中的观点,尤其是下面的陈述:
问题是,现在仅仅有很少的领域可获得数据,并使用深度学习技术进行处理……但是,我认为深度学习对于简单模型的优势在于深度学习可处理大量的数据以及大量的参数。
我并不是赞同这一段,尤其是最后一部分的观点。许多人认为深度学习是一个巨大的黑箱。这个黑箱有海量的参数,只要你能够提供足够多的数据(这里足够多所代表的数据量在一百万和葛立恒数之间),你就能学习到任何的函数。很明显,神经网络极其的灵活,它的灵活性是神经网络之所以取得成功的部分原因。但是,这并不是唯一的原因,对不对?
毕竟,统计学与机器学习对超级灵活模型的研究已经有70多年了。我并不认为神经网络相较于其他拥有同样复杂度的算法,会拥有更好的灵活性。
以下是我认为为什么神经网络会取得成功的一些原因:
1.任何措施都是为了取得偏差与方差的平衡:
需要说清楚的是,我认为Jeff实际上想要讨论的模型复杂度与偏差/方差的平衡。假若你没有足够多的数据,那么使用简单的模型相比于复杂模型来说可能会更好(简单模型意味着高偏差/低方差,复杂模型意味着低偏差/高方差)。我认为在大部分情况下,这是一个很好的客观建议。然而……
2.神经网络有很多的方法来避免过拟合:
神经网络有很多的参数。在Jeff看来,倘若我们没有足够多的数据来估计这些参数的话,这就会导致高方差。人们很清楚这个问题,并研究出了很多可降低方差的技术。像dropout与随机梯度下结合,就会起到bagging算法的作用。我们只不过使用网络参数来代替输入变量。降低方差的技术,比如说dropout,专属于训练过程,在某种程度上来说,其他模型很难使用。这样的话,即使你没有海量的数据,你依然可以训练巨大的模型(就像是我们的MLP,拥有120000个参数)。
3.深度学习能够轻易地将具体问题的限制条件输入到我们的模型当中,这样很容易降低偏差:
这是我认为最重要的部分。然而,我们却经常将这一点忽略掉。神经网络具有模块化功能,它可以包含强大的约束条件(或者说是先验),这样就能够在很大程度上降低模型的方差。最好的例子就是卷积神经网络。在一个CNN中,我们将图像的特征经过编码,然后输入到模型当中去。例如,我们使用一个3X3的卷积,我们这样做实际上就是在告诉我们的网络局部关联的小的像素集合会包含有用的信息。此外,我们可以将经过平移与旋转的但是不变的图像,通过编码来输入到我们的模型当中。这都有助于我们降低模型对图片特征的偏差。并能够大幅度降低方差并提高模型的预测能力。
4.使用深度学习并不需要如google一般的海量数据:
使用上面所提及的方法,即使你是普通人,仅仅拥有100-1000个数据,你仍然可以使用深度学习技术,并从中受益。通过使用这些技术,你不仅可以降低方差,同时也不会降低神经网络的灵活性。你甚至可以通过迁移学习的方法,来在其他任务上来构建网络。
总之,我认为上面的所列举的理由已经能够很好地解释为什么深度学习在实际中会有效。它之所以有效,并不仅仅是因为它拥有大量的参数以及海量的数据。最后,我想说的是本文并没有说Jeff的观点是错误的,本文仅仅是从不同的角度来解读他的观点。希望这篇文章对你有用。
PS:关于正方的观点,请查看:
http://beamandrew.github.io/deeplearning/2017/06/04/deep_learning_works.html
2017中国人工智能大会(CCAI 2017)| 7月22日-23日 杭州
本届CCAI由中国人工智能学会、蚂蚁金服主办,由CSDN承办,最专业的年度技术盛宴:
- 40位以上实力讲师
- 8场权威专家主题报告
- 4场开放式专题研讨会
- 超过100家媒体报道
- 超过2000位技术精英和专业人士参会
与大牛面对面,到官网报名:http://ccai.caai.cn/
