python鸢尾花数据集knn_机器学习(基于Python) 重写Knn算法(鸢尾花数据集)
一.问题描述
用Python语言实现机器学习KNN算法,并用鸢尾花数据集测试。
二.算法设计
1.算法流程图
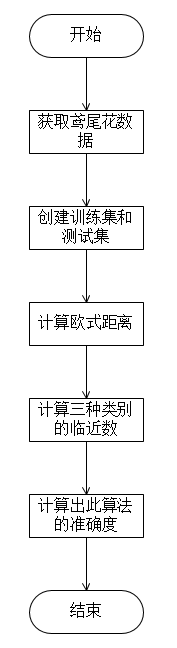
2.具体实现步骤
(1)定义一个My_KNN()函数实现KNN分类算法;
(2)函数参数设为鸢尾花的训练集和测试集;
(3)定义对应的三个列表用来存放测试数据与整个数据的欧氏距离;
(4)定义一个distance列表存放测试数据与所有训练数据的距离;
(5)定义三个整形变量分别表示三类鸢尾花与测试数据的邻近个数;
(6)调用math和numpy库中的函数计算测试数据与鸢尾花数据集的欧氏距离,并存入对应的列表,最后计算结束后,将distance列表按照升序重新排列;
(7)利用循环判断distance中的距离在哪一个列表中,即该类邻近个数自增,循环次数为k次;
(8)判断三类邻近个数的大小,个数最多的那一类即为测试数据的类别;
(9)利用循环判断测试集中正确的结果个数,并用公式计算出预测结果的准确性。
三.程序实现
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 15 15:40:39 2019
@author: fanghejun
"""
import numpy
import math
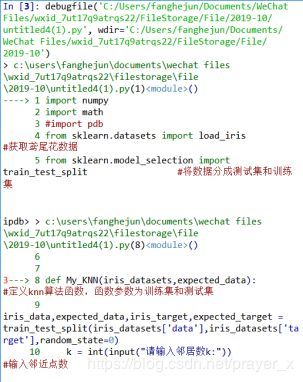
from sklearn.datasets import load_iris #获取鸢尾花数据
from sklearn.model_selection import train_test_split #将数据分成测试集和训练集
def My_KNN(iris_datasets,expected_data): #定义knn算法函数,函数参数为训练集和测试集
iris_data,expected_data,iris_target,expected_target = train_test_split(iris_datasets['data'],iris_datasets['target'],random_state=0)
k = int(input("请输入邻居数k:")) #输入邻近点数
test_target = [] #用来存放测试结果
for j in range(0,len(expected_data)):
distance = [] #用来存放测试集数据与训练集数据的欧氏距离
iris1 = [] #用来存放测试集数据与第一类鸢尾花数据的欧氏距离
iris2 = [] #用来存放测试集数据与第二类鸢尾花数据的欧氏距离
iris3 = [] #用来存放测试集数据与第三类鸢尾花数据的欧氏距离
index1 = 0 #测试集数据与第一类鸢尾花邻近个数
index2 = 0 #测试集数据与第二类鸢尾花邻近个数
index3 = 0 #测试集数据与第三类鸢尾花邻近个数
for i in range(0,len(iris_data)): #计算欧氏距离
distance.append(math.sqrt((numpy.square(expected_data[j][0]-iris_data[i][0])+numpy.square(expected_data[j][1]-iris_data[i][1])+numpy.square(expected_data[j][2]-iris_data[i][2])+numpy.square(expected_data[j][3]-iris_data[i][3]))))
if(iris_target[i]==0):
iris1.append(math.sqrt((numpy.square(expected_data[j][0]-iris_data[i][0])+numpy.square(expected_data[j][1]-iris_data[i][1])+numpy.square(expected_data[j][2]-iris_data[i][2])+numpy.square(expected_data[j][3]-iris_data[i][3]))))
elif(iris_target[i]==1):
iris2.append(math.sqrt((numpy.square(expected_data[j][0]-iris_data[i][0])+numpy.square(expected_data[j][1]-iris_data[i][1])+numpy.square(expected_data[j][2]-iris_data[i][2])+numpy.square(expected_data[j][3]-iris_data[i][3]))))
elif(iris_target[i]==2):
iris3.append(math.sqrt((numpy.square(expected_data[j][0]-iris_data[i][0])+numpy.square(expected_data[j][1]-iris_data[i][1])+numpy.square(expected_data[j][2]-iris_data[i][2])+numpy.square(expected_data[j][3]-iris_data[i][3]))))
distance.sort(reverse = False) #将列表元素升序排列
distance = distance[0:k-1] #截取最短的k个距离
for m in distance: #计算三个类别邻近数
if m in iris1:
index1=index1+1
elif m in iris2:
index2=index2+1
else:
index3=index3+1
final=[index1,index2,index3]
final_index= final.index(max(final))
if final_index==0: #分类
test_target.append(0)
elif final_index==1:
test_target.append(1)
else:
test_target.append(2)
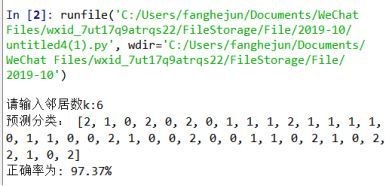
print("预测分类:",test_target)
correct = 0
for i in range(0,len(expected_target)): #将测试集中正确的个数记录下来
if(expected_target[i]==test_target[i]):
correct=correct+1
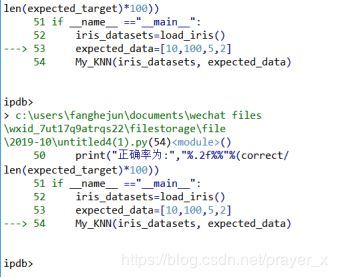
print("正确率为:","%.2f%%"%(correct/len(expected_target)*100))
if __name__ =="__main__":
iris_datasets=load_iris()
expected_data=[10,100,5,2]
My_KNN(iris_datasets, expected_data)
四.运行、调试截图
运行截图:
调试截图:

五.心得体会
本次重写Knn算法的程序是一次很新奇的代码体验,最初即使知道算法的目的也是无从下手,而且Python语言是这学期新接触的语言,因此对其语法、函数等的使用也是很陌生。在查阅了很多资料后才有了思路,本次程序主要借鉴了博客:
https://blog.csdn.net/qq_43696482/article/details/102564879的程序。