近期想做个东西把大段对话转成文字。用语音输入法太慢,所以想到看有没有现成的API,网上一搜,基本就是百度和讯飞。
这里先看百度的
笔者使用的是Java版本号的
下载地址:http://bos.nj.bpc.baidu.com/v1/audio/Baidu_Voice_RestApi_SampleCode.zip
解压之后里面有个51.2KB的PCM格式的音频文件,笔者尝试用各种播放器发现非常少有能打开的。最后找到一种方法分享一下。
一、播放例子音频
下载安装Adobe Audition 3.0当然你也能够用更高的版本号
打开Adobe Audition,然后将test.pcm直接拖进来,这是后会弹出窗体,依照以下这个格式选


然后点击播放。你会听到“百度语音提供技术支持”。
波形图是这种

二、以下我们来看程序的执行结果
首先,你须要创建一个应用,找到应用的API Key和Secret Key,在程序里改成你自己的,然后设置里面的cuid,cuid好像能够随意填,不知道怎么填的就改成你的网卡MAC地址。
以下是执行结果
"D:\Program Files\Java\jdk1.8.0_77\bin\java" -agentlib:jdwp=transport=dt_socket,address=127.0.0.1:52675,suspend=y,server=n -Dfile.encoding=UTF-8 -classpath "D:\Program Files\Java\jdk1.8.0_77\jre\lib\charsets.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\deploy.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\access-bridge-64.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\cldrdata.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\dnsns.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\jaccess.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\jfxrt.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\localedata.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\nashorn.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\sunec.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\sunjce_provider.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\sunmscapi.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\sunpkcs11.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\zipfs.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\javaws.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\jce.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\jfr.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\jfxswt.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\jsse.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\management-agent.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\plugin.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\resources.jar;D:\Program Files\Java\jdk1.8.0_77\jre\lib\rt.jar;D:\IdeaProjects\Helloworld\out\production\Helloworld;C:\Program Files (x86)\JetBrains\IntelliJ IDEA 2016.2\lib\idea_rt.jar" com.baidu.speech.serviceapi.Sample
Connected to the target VM, address: '127.0.0.1:52675', transport: 'socket'
{
"access_token": "24.34cfbc06516a339bca203a7d250d2d19.2592000.1474034743.282335-8506303",
"refresh_token": "25.69215650d359739773609458e2d5ed6a.315360000.1786802743.282335-8506303",
"scope": "public audio_voice_assistant_get audio_tts_post wise_adapt lebo_resource_base lightservice_public hetu_basic lightcms_map_poi kaidian_kaidian wangrantest_test wangrantest_test1 vis-faceverify_faceverify bnstest_test1 vis-ocr_ocr",
"session_key": "9mzdCPAwAJZlQyjkoqSZR4FyJ4v7SKYRS8zy3thuiQfT/K9GAL+fG0zGIm4/kkTagxBIHrJd+qs49Iu59xMKGetYDI1W",
"session_secret": "2a223032e1579bf5996fb6d4b38f767d",
"expires_in": 2592000
}
{
"result": ["百度语音提供技术支持,"],
"err_msg": "success.",
"sn": "678411133801471442744",
"corpus_no": "6319798464275533284",
"err_no": 0
}
{
Disconnected from the target VM, address: '127.0.0.1:52675', transport: 'socket'
"result": ["百度语音提供技术支持,"],
"err_msg": "success.",
"sn": "37862479621471442745",
"corpus_no": "6319798471823426386",
"err_no": 0
}三、音频文件转换
百度语音识别对语音的格式和參数是有要求的。文档看这里:http://yuyin.baidu.com/docs/asr/57
这里就捡重要的说了,格式支持pcm(不压缩)、wav、opus、speex、amr、x-flac。然后採样率深度声道要满足:8k/16k 採样率 16bit 位深的单声道语音。每段要处理的语音不能超过一分钟
格式上。非常多音频软件、播放器能满足要求,可是后面的參数要达到要求就有点难了。
1.少量音频的转换
对于少量音频,我们依旧能够通过Adobe Audition将其转换为符合要求的wav格式。保存或导出,选择ACM波形的wav格式,属性选择8.000kHz 8位 单声道
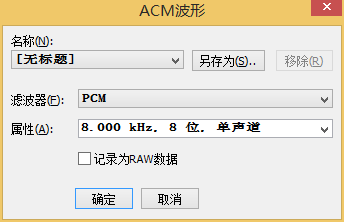
保存之后就能够用到百度语音识别API上了
2.长对话的转换
假设对话过长,一段一段截取导出会很麻烦。好在有一些工具能够帮我们做这些事情
2.1使用Goldwave自己主动分曲功能
自己主动分曲原理通过搜索静音区将对话或歌曲进行分段。
使用Goldwave打开音频文件,Edit-->Cute Point-->Edit Cute Points,点击Auto Cute(自己主动分曲)
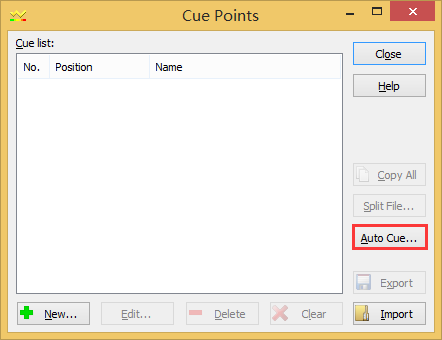

这里有两个值须要注意
Below threshold这个值越大。分曲个数越多。这个是推断静音区的标准,往右调能够将大一点的声音归类到静音
Minimun length这个值确定每段话有最少有多少秒
在最下方的Cue Naming分曲命名中建议选另外一种,方便以后程序做循环处理。
选好须要的值点OK,分曲就分好了。假设不惬意就继续调
分曲完毕后。我们能够点Splite File导出这些分段的音频
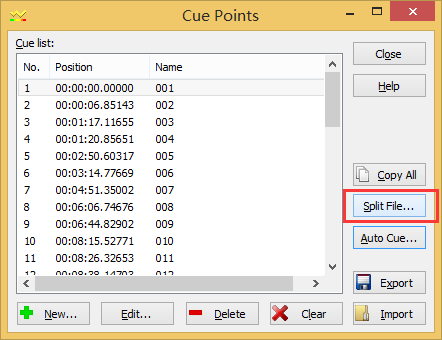
导出选同样格式就好了,反正Goldwave里面没有适合百度识别的格式
2.2使用格式工厂批量转换
格式工厂,选音频-->amr-->改动输出配置例如以下,改完记得点确定。
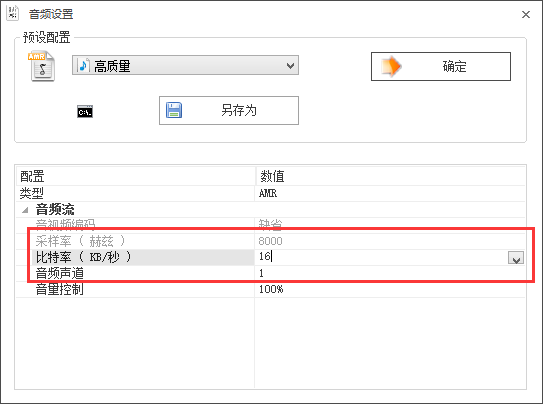
然后批量导出就好了,放到程序里改一下文件名称和文件格式就能识别了。