计算机视觉--历史发展回顾
计算机视觉–历史发展回顾
文章目录
- 计算机视觉--历史发展回顾
- 前言
- 一、神经生理学家的启发
- 二、第一台数字扫描仪的发明
- 三、感知机
- 四、CV的标志性诞生
- 五、CV崛起--LeNet的划时代
- 六、感知分组
- 七、CNN领跑
- 小结
前言
如今,人工智能带来的技术革命火遍了全球,而计算机视觉作为人工智能的分支,借此机会,重温那些计算机视觉默默发展的岁月。
一、神经生理学家的启发
计算机视觉领域最具影响力的论文之一是由两位神经生理学家David Hubel和Torsten Wiesel于1959年发表的。他们的出版物题为“猫纹状皮层中单个神经元的感受野”,描述了视觉皮层神经元的核心反应特性以及猫的视觉体验如何塑造其皮层结构。
两人进行了一些非常精细的实验。他们将电极放入麻醉猫大脑的主要视觉皮层区域,观察或至少尝试该区域的神经元活动,同时向动物展示各种图像。他们最初的努力是徒劳的;他们无法让神经细胞对任何事情做出反应。
然而,在研究几个月后,他们相当偶然地注意到,当他们将一张新幻灯片滑入投影仪时,一个神经元被发射了。这是一次幸运的意外!经过一些最初的困惑,Hubel和Wiesel意识到让神经元兴奋的是玻璃载玻片锋利边缘的阴影产生的线条的运动。
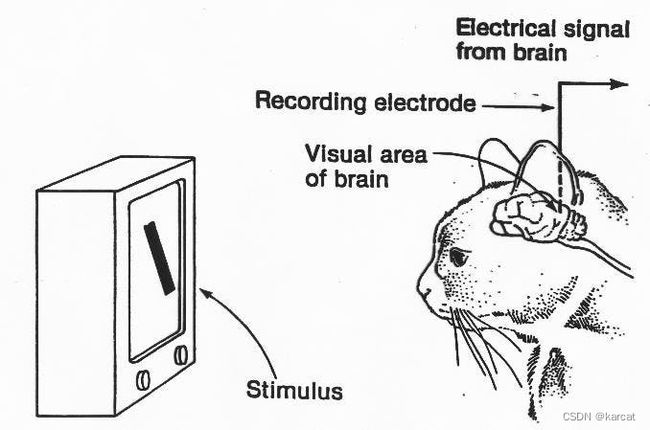
有意思的是,去年2022年在推上各位神经科学和人工智能的大佬,各方混战(图灵奖得主杨立昆 Yann Leecun也参与到了其中),争论到底是不是神经科学直接改变引导了AI的发展,推特上面足足争吵了一个多星期,最后大家各退一步,认为神经科学对神经网络的构造提供了很大的启示,但是神经网络又不是根据现实的神经网络构造的,还是进行了创新性的改进。
这个一个多星期的激烈交流,都是业内前沿的选手,人工智能也是这样在不同思想激烈的碰撞与融合中不断发展的。
二、第一台数字扫描仪的发明
CV历史上的下一个亮点是第一台数字图像扫描仪的发明。
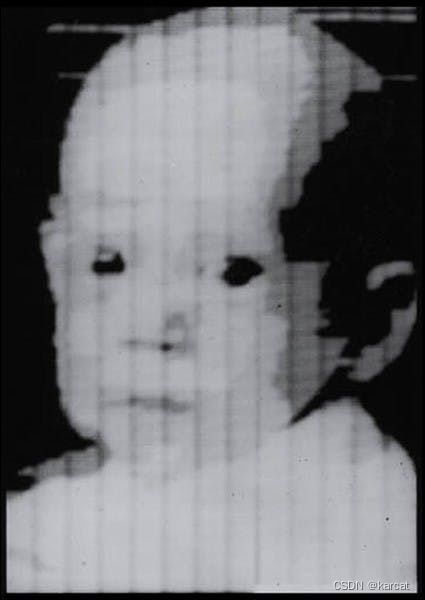
1959年,Russell Kirsch和他的同事开发了一种设备,可以将图像转换为数字网格 - 二进制语言机器可以理解。正是由于他们的工作,我们现在可以用各种方式处理数字图像。
最早的数字扫描照片之一是罗素襁褓中的儿子的照片。这只是一张 5 厘米 x 5 厘米的颗粒状照片,拍摄为 30,976 像素(176x176 阵列),但它已经变得非常有名,以至于原始图像现在存储在波特兰艺术博物馆。
三、感知机
劳伦斯·罗伯茨(Lawrence Roberts)的“三维固体的机器感知”,该书发表于1963年,被广泛认为是现代计算机视觉的先驱之一。
在那篇博士论文中,拉里描述了从2D照片中获取有关固体物体的3D信息的过程。他基本上将视觉世界简化为简单的几何形状。

他在论文中开发和描述的程序的目标是将 2D 照片处理成线条图,然后从这些线条构建 3D 表示,最后显示物体的 3D 结构,并删除所有隐藏线。
Larry 写道,从 2D 到 3D 构建,然后是 3D 到 2D 显示的过程,是未来计算机辅助 3D 系统研究的良好起点。他是非常正确的。
应该指出的是,劳伦斯并没有在计算机视觉领域停留很长时间。相反,他继续加入 DARPA,现在被称为互联网的发明者之一。
四、CV的标志性诞生
1960 年代,人工智能成为一门学科,一些对该领域的未来极为乐观的研究人员认为,用不超过 25 年的时间就能创造出与人类一样智能的计算机。正是在这个时期,麻省理工学院人工智能实验室的教授 Seymour Papert 决定启动夏季视觉项目,并在几个月内解决机器视觉问题。
他认为麻省理工学院的一小群学生有能力在一个夏天开发视觉系统的重要部分。在 Seymour 本人和 Gerald Sussman 的协调下,学生们将设计一个平台,该平台可以自动执行背景/前景分割并从现实世界的图像中提取非重叠对象。
该项目没有成功。五十年后,我们仍远未解决计算机视觉问题。然而,根据许多人的说法,该项目标志着 CV 作为一个科学领域的正式诞生。
五、CV崛起–LeNet的划时代
1982年,英国神经科学家大卫·马尔发表了另一篇颇具影响力的论文——《视觉:视觉信息的人类表征和处理的计算研究》。
基于 Hubel 和 Wiesel(他们发现视觉处理并非从整体对象开始)的想法,David 给了我们下一个重要的见解:他确立了视觉是分层的。他认为,视觉系统的主要功能是创建环境的 3D 表示,以便我们可以与之交互。
他引入了一个视觉框架,其中检测边缘、曲线、角等的低级算法被用作通向对视觉数据的高级理解的垫脚石。
David Marr 的愿景表征框架包括:
图像的原始草图,其中表示了边缘、条形、边界等(这显然受到 Hubel 和 Wiesel 研究的启发);
一个 2½D 草图表示,其中表面、深度信息和图像上的不连续性被拼凑在一起;
根据表面和体积基元分层组织的 3D 模型。
David Marr 的工作在当时是开创性的,但非常抽象和高级。它没有包含任何关于可以在人工视觉系统中使用的数学模型类型的信息,也没有提到任何类型的学习过程。
大约在同一时间,同样深受 Hubel 和 Wiesel 启发的日本计算机科学家 Kunihiko Fukushima 构建了一个由简单和复杂细胞组成的自组织人工网络,可以识别模式并且不受位置变化的影响。Neocognitron网络包括多个卷积层,其(通常为矩形)感受野具有权重向量(称为过滤器)。
这些过滤器的功能是在输入值(例如图像像素)的二维数组中滑动,并在执行某些计算后生成激活事件(二维数组),这些激活事件将用作网络后续层的输入。
Fukushima 的 Neocognitron 可以说是第一个配得上deep这个绰号的神经网络;它是当今 convnet 的祖父。
几年后的 1989 年,年轻的法国科学家 Yann LeCun 将反向传播风格的学习算法应用于福岛的卷积神经网络架构。在这个项目上工作了几年后,LeCun发布了 LeNet- 5——第一个引入了我们今天仍在 CNN 中使用的一些基本成分的现代卷积神经网络。
和之前的福岛一样,LeCun 决定将他的发明应用于字符识别,甚至发布了一款阅读邮政编码的商业产品。
除此之外,他的工作促成了MNIST手写数字数据集的创建——这可能是机器学习中最著名的基准数据集。
六、感知分组
1997 年,一位名叫 Jitendra Malik 的伯克利教授(和他的学生施建波)发表了一篇论文,描述了他在解决感知分组问题上的尝试。
研究人员试图让机器使用图论算法将图像分割成可感知的部分(自动确定图像上的哪些像素属于一起,并将物体与其周围环境区分开来)。
他们并没有走多远。感知分组的问题仍然是 CV 专家正在努力解决的问题。
在 20 世纪 90 年代后期,计算机视觉作为一个领域在很大程度上改变了它的重点。
1999 年左右,许多研究人员不再尝试通过创建对象的 3D 模型(Marr 提出的路径)来重建对象,而是将他们的努力转向基于特征的对象识别。David Lowe 的作品“从局部尺度不变特征进行对象识别”特别说明了这一点。
该论文描述了一种视觉识别系统,该系统使用对旋转、位置和部分光照变化不变的局部特征。根据 Lowe 的说法,这些特征有点类似于下颞叶皮层中发现的神经元的特性,这些神经元参与灵长类动物视觉中的物体检测过程。
此后不久,Paul Viola 和 Michael Jones 于 2001 年推出了第一个实时人脸检测框架。虽然不是基于深度学习,但该算法仍然具有深度学习的味道,因为在处理图像时,它学习了哪些特征(非常简单,类似 Haar 的特征)可以帮助定位人脸。
 Viola/Jones 人脸检测器仍然被广泛使用。它是一个由多个弱分类器构建而成的强二元分类器;在学习阶段,在这种情况下非常耗时,弱分类器级联使用Adaboost进行训练。
Viola/Jones 人脸检测器仍然被广泛使用。它是一个由多个弱分类器构建而成的强二元分类器;在学习阶段,在这种情况下非常耗时,弱分类器级联使用Adaboost进行训练。
为了找到感兴趣的对象(面部),该模型将输入图像划分为矩形块,并将它们全部提交给级联的弱检测器。如果一个补丁通过了级联的每个阶段,它就被归类为积极的,如果没有,算法会立即拒绝它。这个过程在不同的规模上重复了很多次。
论文发表五年后,富士通发布了一款具有实时人脸检测功能的相机,该功能依赖于 Viola/Jones 算法。
随着计算机视觉领域的不断发展,社区迫切需要一个基准图像数据集和标准评估指标来比较其模型的性能。
七、CNN领跑
2006年,Pascal VOC项目启动。它提供了一个用于对象分类的标准化数据集以及一组用于访问所述数据集和注释的工具。从 2006 年到 2012 年,创始人还举办了年度竞赛,评估不同对象类别识别方法的性能。
2009 年,Pedro Felzenszwalb、David McAllester 和 Deva Ramanan 开发了另一个重要的基于特征的模型——可变形零件模型。
从本质上讲,它将对象分解为多个部分的集合(基于Fischler 和 Elschlager 在 1970 年代引入的图形模型),在它们之间强制执行一组几何约束,并对作为潜在变量的潜在对象中心进行建模。
DPM 在对象检测任务(使用边界框来定位对象)和节拍模板匹配等当时流行的对象检测方法中表现出色。
您可能听说过的 ImageNet 大规模视觉识别竞赛 (ILSVRC) 始于 2010 年。跟随 PASCAL VOC 的脚步,它也每年举办一次,包括一个赛后研讨会,参与者可以在其中讨论他们从最具创新性的条目。
与只有 20 个对象类别的 Pascal VOC 不同,ImageNet 数据集包含超过一百万个图像,手动清理,跨越 1k 个对象类别。
自成立以来,ImageNet 挑战赛已成为跨大量对象类别的对象类别分类和对象检测的基准。
2010 年和 2011 年,ILSVRC 在图像分类方面的错误率徘徊在 26% 左右。但在 2012 年,多伦多大学的一个团队将卷积神经网络模型 (AlexNet) 投入竞赛,这改变了一切。该模型的架构类似于 Yann LeCun 的 LeNet-5,错误率为 16.4%。
这是 CNN 的突破性时刻。
在接下来的几年里,ILSVRC 图像分类的错误率下降到百分之几,自 2012 年以来,赢家一直是卷积神经网络。
正如我之前提到的,卷积神经网络自 1980 年代就出现了。那么,为什么他们花了这么长时间才流行起来呢?
我们将当前的 CNN 爆炸归因于三个因素:
- 多亏了摩尔定律,与 1990 年代发布 LeNet-5 时相比,我们的机器现在速度更快、功能更强大。
- NVIDIA 的可并行图形处理单元帮助我们在深度学习方面取得了重大进展。
- 最后,今天的研究人员可以访问大型、带标签的高维视觉数据集(ImageNet、Pascal 等)。因此,他们可以充分训练他们的深度学习模型并避免过度拟合。
小结
浅尝即止,本文仅仅简单介绍了计算机视觉发展的的几个重要历史时期,更多的讲解在后续的更新中