keras中的学习率控制以及代码实现
【时间】2019.12.04
【题目】keras中的学习率控制以及代码实现
一、keras中的学习率控制
使用两个回调函数进行lr控制:
keras.callbacks.LearningRateScheduler(schedule)以及
keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=10, verbose=0, mode='auto', epsilon=0.0001, cooldown=0, min_lr=0)具体见:
Keras学习率调整
keras 的LearningRateScheduler
二、常见的学习率衰减方式
详见:Tensorflow 中 learning rate decay 的奇技淫巧
Tensorflow 中 learning rate decay 的奇技淫巧(代码)
learning rate衰减策略文件在tensorflow/tensorflow/python/training/learning_rate_decay.py中,函数中调用方法类似tf.train.exponential_decay就可以了。
keras 中也可以调用tf.train.exponential_decay进行设置。具体如下(以cosine decay为例):
import keras.backend as K
from keras.callbacks import LearningRateScheduler
def scheduler_cosine_decay(epoch,learning_rate=0.01, decay_steps=250, alpha=0.0001):
if epoch==0:
global global_step
global new_lr
global sess
global_step = tf.Variable(tf.constant(0))
new_lr = tf.train.cosine_decay(learning_rate,global_step, decay_steps, alpha)
sess = tf.Session()
lr = sess.run(new_lr,feed_dict={global_step: epoch})
return lr
reduce_lr = LearningRateScheduler(scheduler_cosine_decay)
model.fit(train_x, train_y, batch_size=32, epochs=300, callbacks=[reduce_lr])
下面介绍各种学习率衰减
2.1、exponential_decay 指数衰减
tf.train.exponential_decay(
learning_rate,初始学习率
global_step,当前迭代次数
decay_steps,衰减速度(在迭代到该次数时学习率衰减为earning_rate * decay_rate)
decay_rate,学习率衰减系数,通常介于0-1之间。
staircase=False,(默认值为False,当为True时,(global_step/decay_steps)则被转化为整数) ,选择不同的衰减方式。
name=None
)
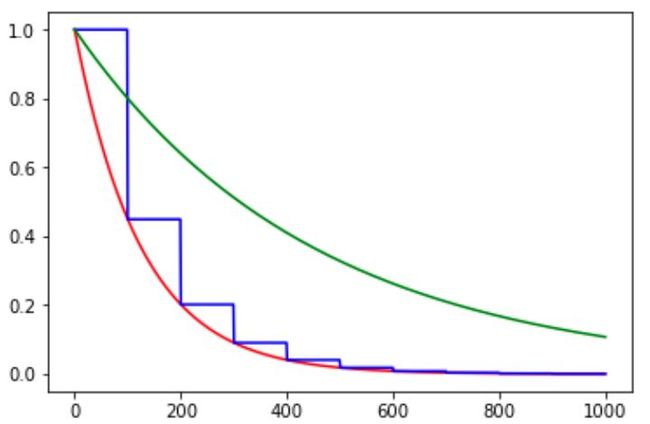
图1. exponential_decay示例,其中红色线条是staircase=False,即指数型下降曲线,蓝色线条是staircase=True,即阶梯式下降曲线
计算公式为:
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)2.2 piecewise_constant 分段常数衰减
piecewise_constant(x, boundaries, values, name=None)分段常数下降法类似于exponential_decay中的阶梯式下降法,不过各阶段的值是自己设定的。
其中,x即为global step,boundaries=[step_1, step_2, ..., step_n]定义了在第几步进行lr衰减,values=[val_0, val_1, val_2, ..., val_n]定义了lr的初始值和后续衰减时的具体取值。需要注意的是,values应该比boundaries长一个维度。

2.3 polynomial_decay 多项式衰减
polynomial_decay(learning_rate, global_step, decay_steps,
end_learning_rate=0.0001, power=1.0,
cycle=False, name=None)计算公式:
global_step = min(global_step, decay_steps)
decayed_learning_rate = (learning_rate - end_learning_rate) *
(1 - global_step / decay_steps) ^ (power) + end_learning_rate
cycle参数是决定lr是否在下降后重新上升的过程。cycle参数的初衷是为了防止网络后期lr十分小导致一直在某个局部最小值中振荡,突然调大lr可以跳出注定不会继续增长的区域探索其他区域。


2.4、自然指数衰减
natural_exp_decay(learning_rate, global_step, decay_steps, decay_rate,
staircase=False, name=None)计算公式:
natural_exp_decay:
decayed_learning_rate = learning_rate * exp(-decay_rate * global_step / decay_steps)natural_exp_decay和exponential_decay形式差不多,只不过自然指数下降的底数是 1/e。
由图可知,自然数指数下降比exponential_decay要快许多,适用于较快收敛,容易训练的网络。
2.5、inverse_time_decay 倒数衰减
inverse_time_decay(learning_rate, global_step, decay_steps, decay_rate,
staircase=False, name=None)公式:
decayed_learning_rate = learning_rate / (1 + decay_rate * global_step / decay_step)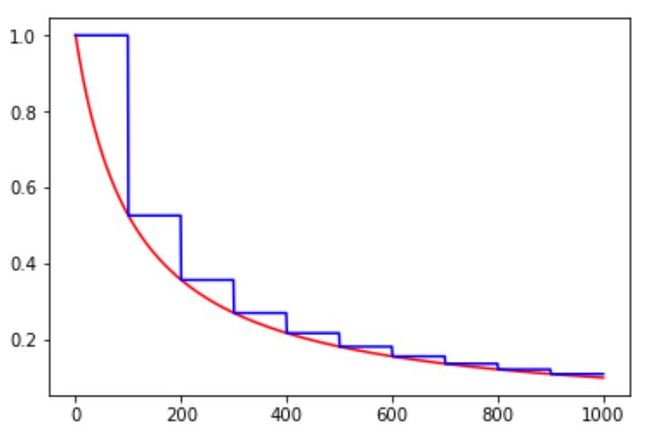
2.1-2.5几种衰减方式相差不大,主要都是基于指数型的衰减。个人理解其问题在于一开始lr就快速下降,在复杂问题中可能会导致快速收敛于局部最小值而没有较好地探索一定范围内的参数空间。
2.6、cosine_decay 余弦衰减
cosine_decay(learning_rate, global_step, decay_steps, alpha=0.0,
name=None)公式:
global_step = min(global_step, decay_steps)
cosine_decay = 0.5 * (1 + cos(pi * global_step / decay_steps))
decayed = (1 - alpha) * cosine_decay + alpha
decayed_learning_rate = learning_rate * decayed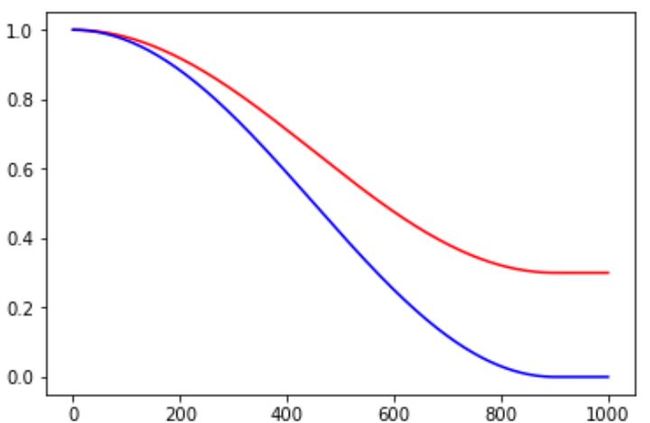
alpha的作用可以看作是baseline,保证lr不会低于某个值,即不会低于lr*alpha这个值。
2.7 cosine_decay_restarts 重新开始余弦函数
cosine_decay_restarts(learning_rate, global_step, first_decay_steps,
t_mul=2.0, m_mul=1.0, alpha=0.0, name=None)cosine_decay_restarts是cosine_decay的cycle版本。first_decay_steps是指第一次完全下降的step数,t_mul是指每一次循环的步数都将乘以t_mul倍,m_mul指每一次循环重新开始时的初始lr是上一次循环初始值的m_mul倍。
余弦函数式的下降模拟了大lr找潜力区域然后小lr快速收敛的过程,加之restart带来的cycle效果,有涨1-2个点的可能。

图、cosine_decay_restarts示例,红色线条t_mul=2.0,m_mul=0.5,蓝色线条t_mul=2.0,m_mul=1.0
2.8、linear_cosine_decay 线性预先衰减,主要用在RL增强学习领域。
linear_cosine_decay(learning_rate, global_step, decay_steps,
num_periods=0.5, alpha=0.0, beta=0.001,
name=None)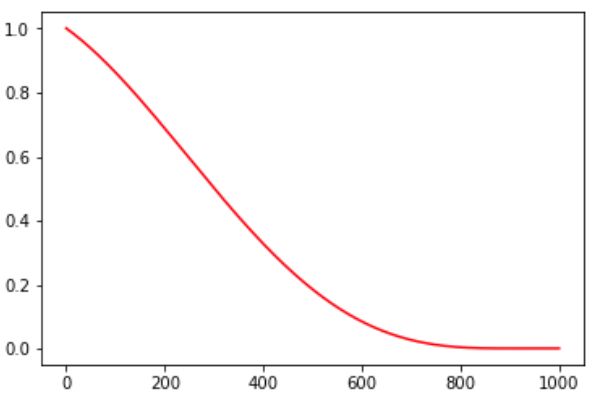
2.9.noisy_linear_cosine_decay 噪声线性余弦衰减
noisy_linear_cosine_decay(learning_rate, global_step, decay_steps,
initial_variance=1.0, variance_decay=0.55,
num_periods=0.5, alpha=0.0, beta=0.001,
name=None)该方法在衰减过程中加入了噪声,某种程度上增加了lr寻找最优值的随机性和可能性。

题外话:
Google在2018年的 ICLR2018 上的论文《DON’T DECAY THE LEARNING RATE, INCREASE THE BATCH SIZE》提出:
不用衰减学习率啦,只要增大 Batch Size 就可以啦!
详见:抛弃Learning Rate Decay吧!