评分卡模型建模详细步骤-评分卡建模实例之scorecardpy
目录
0.引言
1.scorecardpy介绍
2.评分卡建模过程
2.1数据加载
2.1变量筛选
2.2数据划分
2.3变量分箱
2.3.1 自动分箱
2.3.2 手动调整分箱
2.4变量转化woe
2.5模型训练
2.5.1分离训练数据
2.5.2缺失值处理
2.5.3模型训练
2.6 模型评估
2.7模型验证
2.8评分表尺
3.完整源码
0.引言
今天来给大家介绍另一个python开源评分卡建模库-scorecardpy。
在上一篇内容中,我们学习了toad库评分卡模型的基本建模思路与方法,有感兴趣的小伙伴可以点击查看:
数据分析建模之逻辑回归(Logistic Regression)-使用toad进行评分卡建模详细步骤_python toad_江湖人称桂某人的博客-CSDN博客逻辑回归与toad包评分卡模型建模,简单上手,功能强大,含可用源码。https://blog.csdn.net/qq_39837305/article/details/128296317?spm=1001.2014.3001.5502
1.scorecardpy介绍
scorecardpy是由谢士晨博士开发的一款用于金融风控模型的python开源库。其中包含了许多丰富、强大的功能,包括但不限于:内置数据集、数据集划分、变量分箱、评价指标曲线绘制等。scorecardpy封装了众多实用方法,让我们实际应用起来非常简单,一句话:传参就行。
实验环境:
scorecardpy==0.1.9.2
sklearn==0.0.post1
pandas==1.1.5
python==3.6.2
2.评分卡建模过程
2.1数据加载
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import plot_precision_recall_curve
from sklearn.metrics import plot_roc_curve
import scorecardpy as sc
#1. 读入数据
#读入数据
data = sc.germancredit()
#数据信息
data.info()
data.describe()数据集依旧是经常使用的德国信用卡的数据,但这里有所不同,首先scorecardpy将数据集封装在了库中,直接调用即可,其次数据集对比我们在网上常见的进行了删减。
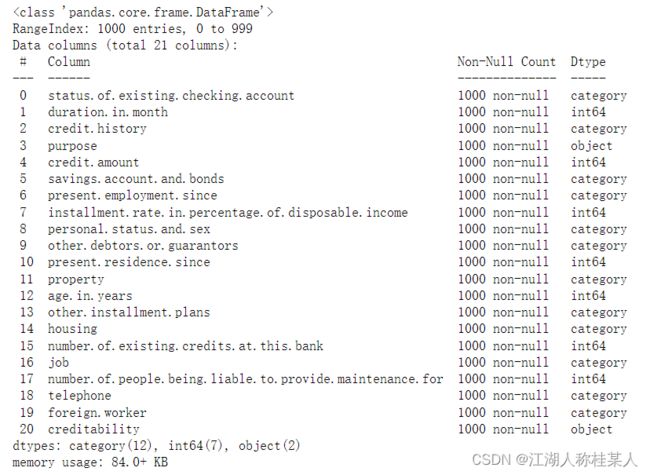
可以明显看到的是,每一列数据只有1000个,而且已经帮我们进行了预处理,我们直接使用即可。数据的格式就是我们最熟悉的DataFrame类型,可以使用我们常用的任何数据分析操作。
还可以使用data.head()查看数据的具体样式,第一次使用数据集一定要查看一下每一项都是什么样的。可以看到我们读取的数据是1000行*21列。
2.1变量筛选
由于数据都已经预处理好了,我们可以直接进行筛选。
#变量筛选
data_s = sc.var_filter(data,
y="creditability",
iv_limit=0.02,
missing_limit=0.95,
identical_limit=0.95,
var_rm=None,
var_kp=None,
return_rm_reason=False,
positive='bad|1')
data_s.shapescorecardpy.var_filter()方法,参数为:
iv_limit:最小iv值
missing_limit:缺失值限制,如果设置为0.95,那么缺失率大于95%的都会被筛选掉。
identical_limit:同值率大于95%删除
var_rm:强制删除变量的名称
var_kp:强制保留变量的名称
return_rm_reason:是否返回每个变量被删除的原因
positive:坏样本的标签,默认为'bad|1'
最后查看一下筛选后的数据形状,变成了(1000,14),筛选删除了7个变量。
2.2数据划分
#3.数据区分
train,test = sc.split_df(data_s,'creditability',ratio=0.7,seed=123).values()scorecardpy.spilt_df返回值有两个,分别是训练集和测试集。
参数如下:
data_s:数据集
'creditability':因变量,也就是好坏客户这一列
ratio:训练集测试集比率,0.7就是训练集:测试集7:3
seed:随机数种子
2.3变量分箱
2.3.1 自动分箱
bins = sc.woebin(train,y="creditability")
这就是scorecardpy的强大之处,一行简略代码直接分箱,传入的两个参数分别是:训练集,因变量的列名。
#细分箱结果报告
sc.woebin_plot(bins)scorecardpy还可以直接对分箱的结果进行图像绘制,一行代码绘制所有自变量数据:
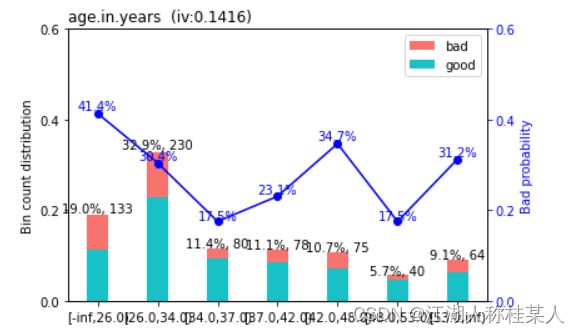
图像的含义是:每个分箱好坏样本的占比,如图也就是年龄分为了7个箱,每个箱具体坏客户的占比就是蓝色的折线,x坐标就是每个分箱范围边界。

同时可以把分享结果进行输出,结果也是一目了然。
2.3.2 手动调整分箱
breaks_adj = {'age.in.years':[22,35,40,60],
'other.debtors.or.guarantors':["none","co-applicant%","%guarantor"]}
bins_adj = sc.woebin(train,y="creditability",breaks_list=breaks_adj)首先定义了一个字典,将年龄(age.in.years)与其他投标人或担保人(other.debtors.or.guarantors)重新进行了分箱。年龄手动分箱结果如下:
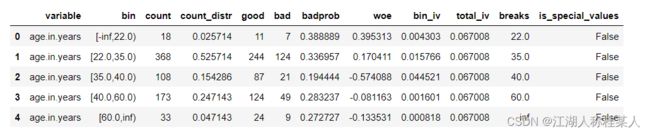
这就按照我们设置的边界进行分箱了。
2.4变量转化woe
#6.变量转换WOE
train_woe = sc.woebin_ply(train,bins_adj)
test_woe = sc.woebin_ply(test,bins_adj)一行代码直接搞定,sc.woebin_ply,分别传入我们准备好的数据集与分箱结果即可。
2.5模型训练
2.5.1分离训练数据
# 分离自变量因变量,用于训练
X_train = train_woe.loc[:,train_woe.columns != 'creditability']
y_train = train_woe.loc[:,'creditability']
X_test = test_woe.loc[:,train_woe.columns != 'creditability']
y_test = test_woe.loc[:,'creditability']将训练集测试集的自变量因变量分成两部分,传入模型训练。
如果直接将数据传入模型进行训练,你会发现:

报错了!我当时按照书上的步骤检查了一遍,没发现有什么问题,后来读了一下报错,其原因是因为出现了缺失值!
所以查看一下数据是否存在缺失值,发现:

2.5.2缺失值处理
我们之前手动分箱的一个变量出现了问题,所以这里要把缺失值进行填充,为了方便,我这里就填充为了0,大家在处理不同数据集的时候,一定要考虑到多方面考虑应该如何填入合适的值(比如均值等)。
X_train = X_train.fillna(0)
X_test = X_test.fillna(0)2.5.3模型训练
#定义分类器
lr = LogisticRegression(penalty='l1',C=0.9,solver='saga',n_jobs=-1)
lr.get_params()
#拟合模型
lr.fit(X_train,y_train)
#拟合的参数
lr.coef_
lr.intercept_采用逻辑回归进行训练,LogisticRegression()参数为:
penalty:惩罚项,默认为l2,l1规范假设的是模型的参数满足拉普拉斯分布,l2假设的模型参数满足高斯分布。
C:正则化系数λ的倒数,float类型,默认为1.0。必须是正浮点型数。像SVM一样,越小的数值表示越强的正则化。
solver:优化算法选择参数,只有五个可选参数,即newton-cg,lbfgs,liblinear,sag,saga。默认为liblinear。
n_jobs:并行数。int类型,默认为1。1的时候,用CPU的一个内核运行程序,2的时候,用CPU的2个内核运行程序。为-1的时候,用所有CPU的内核运行程序。
这些参数大家可以自行进行尝试,觉得那个效果好就用哪个,优化的过程中无非就是调整此类参数,达到一个最好的效果。
2.6 模型评估
# 8.模型评估
# 对训练样本计算预测概率值
y_train_pred = lr.predict_proba(X_train)[:,1]
# 绘制KS、ROC、PR曲线
train_perf = sc.perf_eva(y_train, y_train_pred, plot_type=['ks', 'roc', 'pr', 'lift'], title='train')
plot_roc_curve(lr, X_train, y_train)
plot_precision_recall_curve(lr, X_train, y_train)使用lr.predict_proba(X_train)[:,1]获取到的是预测值。
接下来scorecardpy为我们封装好了模型评估的方法:
sc.perf_eva,传入参数即可,分别是,原数据集,预测值,需要绘制的曲线类型,标题。
绘制结果:
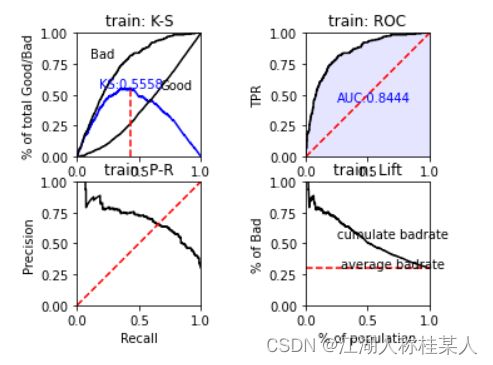
接下来是ROC-AUC图:
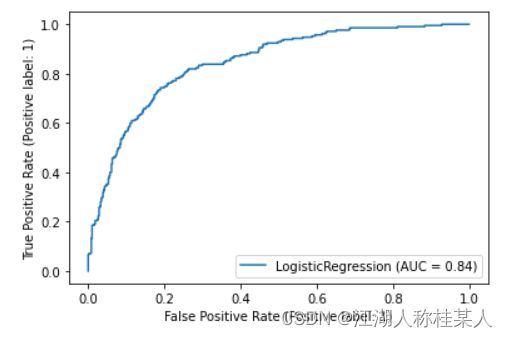
以及召回率准确率:
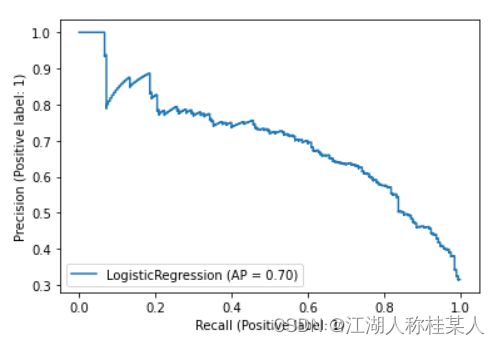
大家可以根据自己实际需求,绘制各种各样的图像,只需传入正确参数即可。
2.7模型验证
其实际过程与上述模型评估基本相同,后面在完整源码中会贴出。
2.8评分表尺
# 10.评分标尺
card = sc.scorecard(bins_adj,
lr,
X_train.columns,
points0=600,
odds0=1/19,
pdo=50,
basepoints_eq0=True)
# 使用评分表尺打分
train_score = sc.scorecard_ply(train, card, print_step=0)
test_score = sc.scorecard_ply(test, card, print_step=0)
# 比较训练集、测试集分数分布是否一致
sc.perf_psi(
score={'train':train_score, 'test':test_score},
label={'train':y_train,'test':y_test})card就是我们获取的最终评分结果,下面随便贴出几个结果:
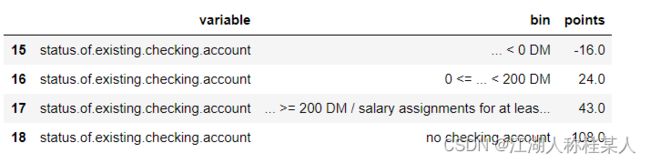
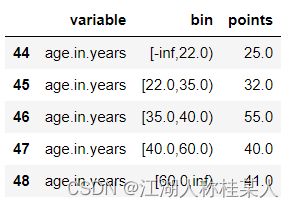
最后还有一个psi的验证,这里不多赘述了,本篇文章目的就是让大家掌握整体的建模流程,很多概念上的东西,大家可以查看我的上一篇博客,或者去网上学习一下含义。
3.完整源码
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import plot_precision_recall_curve
from sklearn.metrics import plot_roc_curve
import scorecardpy as sc
#1. 读入数据
#读入数据
data = sc.germancredit()
#数据信息
data.info()
data.describe()
data.head()
data.isnull().any()
#变量筛选
data_s = sc.var_filter(data,
y="creditability",
iv_limit=0.02,
missing_limit=0.95,
identical_limit=0.95,
var_rm=None,
var_kp=None,
return_rm_reason=False,
positive='bad|1')
data_s.shape
#3.数据区分
train,test = sc.split_df(data_s,'creditability',ratio=0.7,seed=123).values()
#4.变量分箱
#自动分箱
bins = sc.woebin(train,y="creditability")
#细分箱结果报告
sc.woebin_plot(bins)
#5.分箱调整
#交互式输入切分点后分箱
# breaks=adj=sc.woebin_adj(train,"creditability",bins)
#也可以手动设置
breaks_adj = {'age.in.years':[22,35,40,60],
'other.debtors.or.guarantors':["none","co-applicant%","%guarantor"]}
bins_adj = sc.woebin(train,y="creditability",breaks_list=breaks_adj)
bins_adj['age.in.years']
#6.变量转换WOE
train_woe = sc.woebin_ply(train,bins_adj)
test_woe = sc.woebin_ply(test,bins_adj)
#7.训练模型
#处理数据
X_train = train_woe.loc[:,train_woe.columns != 'creditability']
y_train = train_woe.loc[:,'creditability']
X_test = test_woe.loc[:,train_woe.columns != 'creditability']
y_test = test_woe.loc[:,'creditability']
X_train.isnull().any()
X_test.isnull().any()
X_train = X_train.fillna(0)
X_test = X_test.fillna(0)
#定义分类器
lr = LogisticRegression(penalty='l1',C=0.9,solver='saga',n_jobs=-1)
lr.get_params()
#拟合模型
lr.fit(X_train,y_train)
#拟合的参数
lr.coef_
lr.intercept_
# 8.模型评估
# 对训练样本计算预测概率值
y_train_pred = lr.predict_proba(X_train)[:,1]
# 绘制KS、ROC、PR曲线
train_perf = sc.perf_eva(y_train, y_train_pred, plot_type=['ks', 'roc', 'pr', 'lift'], title='train')
plot_roc_curve(lr, X_train, y_train)
plot_precision_recall_curve(lr, X_train, y_train)
# 9.模型验证
# 对测试样本计算预测概率值
y_test_pred = lr.predict_proba(X_test)[:,1]
test_perf = sc.perf_eva(y_test, y_test_pred, plot_type=['ks', 'roc', 'pr', 'lift'], title='test')
plot_roc_curve(lr, X_test, y_test)
plot_precision_recall_curve(lr, X_test, y_test)
# 10.评分标尺
card = sc.scorecard(bins_adj,
lr,
X_train.columns,
points0=600,
odds0=1/19,
pdo=50,
basepoints_eq0=True)
# 使用评分表尺打分
train_score = sc.scorecard_ply(train, card, print_step=0)
test_score = sc.scorecard_ply(test, card, print_step=0)
# 比较训练集、测试集分数分布是否一致
sc.perf_psi(
score={'train':train_score, 'test':test_score},
label={'train':y_train,'test':y_test})
# 查看评分
card['age.in.years']scorecardpy封装很多高级方法,我们只需传入自己的参数即可,但是正因为如此,在过程中想要修改一些底层的内容是非常繁琐的,在使用高级方法的同时,大家也要记住机器学习领域的一句话:世上没有免费的午餐!
源码亲测可用,如有问题,欢迎大家指正!