python统计分析 学习笔记
统计数据的展示
数据类型
数值型:采用某些特定的统计学方法
连续数值型:
身高、体重
离散数值型:
子女的个数:012345
分类型:其他方法
分类数据
布尔变量

名义变量

等级变量
在python中作图
函数式和面向对象式的绘图方法
函数式

面向对象式(优势:学术上表达事情明确清晰)


交互式绘图
matplotlib交互不如Matlab直观
展示统计学数据集
seaborn\pandas 都是基于matplotlib
seaborn 旨在提供一个简洁、高层的接口,用于绘制富含信息扯且美观的统计学图形
pandas 提供了许多可视化数据框的方法

单变量数据

1.散点图
或

2.直方图
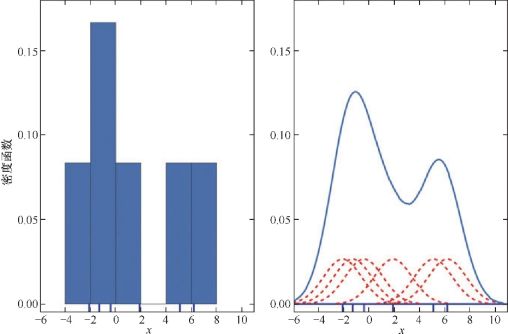
3.核密度(KDE)估计图
用正态分布解决直方图非连续的问题
4.累积频率


正态分布的累积频率函数
5.误差条图

使用标准误有一个很好的特性:当基于标准误的两组误差条图之间有重叠时,我们可以确定两组之间的均值没有统计学差异( p >0.05 )。反之则不一定成立!


6.箱形图
箱子的底部和顶部分别表示第一分位数和第三分位数,箱子内部中间的线表示中位数,
下面的须表示在第一分位数外 1.5 x IQR (四分位距)范围内的最低值,而上面的须表示在第三分位数外
1.5 X IQR (四分位距)范围内的最高值。(另一个习惯用法是须表示了整个数据的范围。)

小提琴图=箱形图+核密度估计图
纵轴和箱形图一样,但是在水平方向上额外绘制了对称的核密度估计图

7.分组的条形图


8.饼图


二元变量和多元变量绘图
1.二元变量散点图
带有不同大小数据点的散点图

2.3D图
3D图坐标轴需要显式声明,一旦正确定义坐标轴,剩下的部分就很直观了



分布和假设检验
总体和样本
总体 :包括数据集中的所有元素
样本 :总体中的一个或多个观察值组成
参数 :总体的特征,如均值或标准偏差(度量数据分布的分散程度)通常用希腊字母表示
统计量: 一个样本的可测量的特征
• 样本数据的均值;
• 样本数据的极差;
• 数据与样本均值的偏离
抽样分布:基于随机样本的给定统计量的概率分布

概率分布
概率密度:X为连续型随机变量,称f(x)为X的概率密度函数,简称为概率密度
概率分布:,在统计图上画出概率密度,概率分布是描述总体和样中数值数据分布的数学工具
离散分布
掷骰子
对于给定的离散分布, Pi称为该分布的概率质量函数 (PMF)
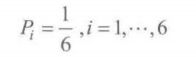
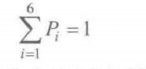

连续分布
例如,一个人的重量可以是任意正数,描述每个值的概率的曲线,即概率分布,是一个连续函数,称为概率
密度函数 (PDF)。

p(x) 是值 x 的概率密度函数。在 a 和 b 之间的 p(x) 上的积分表示在该范围内找到 x 的值的可能性

期望值和方差
1.期望值
离散分布:
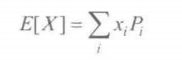
连续分布:

2.方差
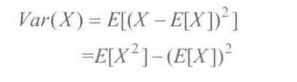
自由度Degrees of Freedom(DOF)
自由度:取值不受限制的变量个数

22个人,分三组,两组样本均值知道,总体样本均值知道,即可求出第三组样本均值,因此确定的值终于三个,自由度减三。
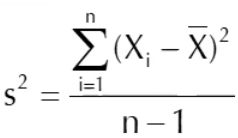
求方差,分母是自由度
研究设计
术语
因素:被控制的输入变量
协同因素:木被控制的输入变量
协变量:一个对研究结局有可能做出预测的变量,并且可以是因素或协同因素
两个输入和 个输出:









概述


单变量的分布
单变量的分布:一个变量的分布
离散分布:整数值
连续分布:浮点值
分布的特征描述
分布中心
用参数描述分布中心
均值(算术均值)
受异常值影响

numpy

2.中位数
数据按顺序排列时中间的值,不受异常值影响
3.众数
一个分布中出现最频繁的值

4.几何均值
几何平均可以用来描述分布的位置,通过计算每个值的对数的算数平均值得到

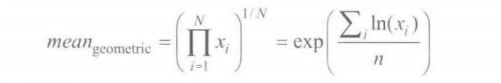
量化变异度
1.极差
2.百分位数

CDF是PDF从负无穷大到给定值的积分
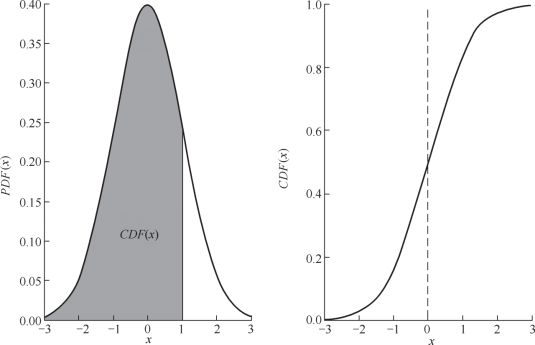
3.标准差和方差
样本方差的极大似然估计(’有偏估计‘)(被除数为样本数)

群体方差的‘无偏估计‘(被除数为自由度n-1)
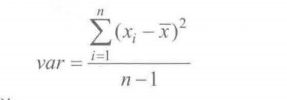
样本标准差
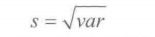

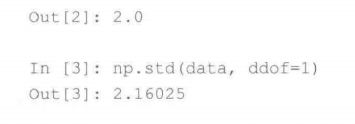
4.标准误
样本均值的标准误(Standard Error for the Sample Mean)
对一个总体多次抽样,每次样本大小都为n,那么每个样本都有自己的平均值,这些平均值的标准差叫做标准误
反映样本平均数对总体平均数的变异程度。

5.置信区间
[a,b]称为置信区间
a = 样本均值 - z标准误差
b = 样本均值 + z标准误差

分布形状的参数描述
1.位置
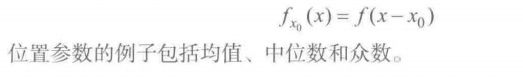
2.尺度
尺度参数描述了概率分布的宽度
3.形状参数
偏度:标准差大于均值的一半是偏斜分布而不是正态
峰度:概率分布的’陡峭程度‘,正太分布峰度为3
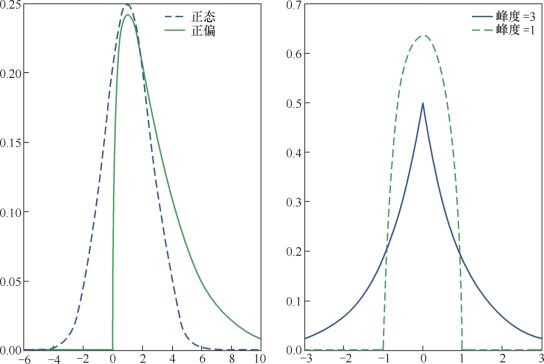
离散分布
伯努利分布
抛硬币一次,是二项分布的特殊情况

二项分布
抛硬币多次
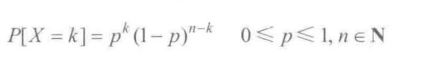

泊松分布
在连续的空间或时间内离散事件发生的次数(X为整数)



正态分布
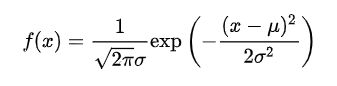

分布和假设检验

来自正态分布的连续型分布
t分布:正态分布的总体中,样本均值的样本分布。通常用于小样本数且真实的均值/标准差不知道的情况。
卡方分布:用于描述正态分布数据的变异程度
F分布:用于比较两组正态分布的变异程度
t分布
在大多数情况下,总体的均值和方差是未知的,我们在分析样本数据的时候一般都是处理t分布
常见应用是:计算均值的置信区间

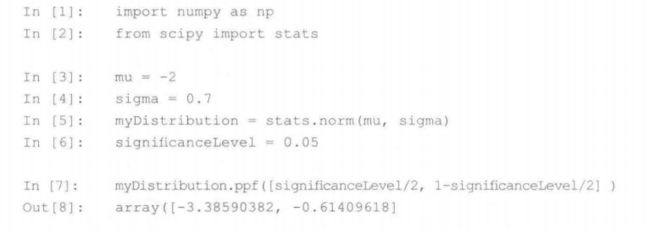
import numpy as np
from scipy import stats
n=20
df=n-1#自由度
alpha=0.05#alpha是分位点 置信区间95%~0.05
stats.t(df).isf(alpha/2)
stats.norm.isf(alpha/2)
#均值的 95% 可信区间
alpha=0.95
df=len(data)-1
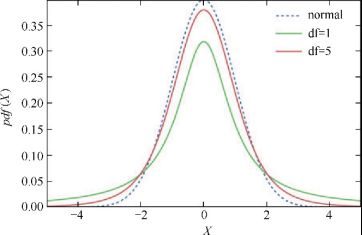
ci=stats.interval(alpha,df,loc=np.mean(data),scale=stats.sem(data))t分布的尾部比正态分布长,它更不易受极端例子影响

t 分布在处理异常值时比正态分布更加稳健。(上图)以来自正态分布的样本进行最佳拟合的正态分布和 t 分布。(下图)是相同的分布,但是加上了 20 个异常值,这些异常值在 5 附近呈正态分布
卡方分布
用于描述正态分布数据的变异程度


当服从正态分布的随机变量数(n)越大时,自由度也越大,卡方分布图像越接近正态分布
F分布
比较两组正态分布的变异程度
方差分析
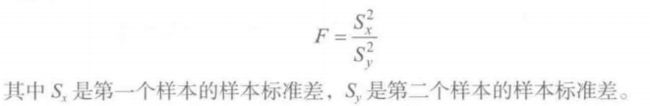
方差分析(Analysis of Variance,简称ANOVA)
又称“变异数分析”,用于两个及两个以上样本均数差别的显著性检验
F分布图

F分布和卡方分布:
F分布定义:设X、Y为两个独立的随机变量,X服从自由度为k1的卡方分布,Y服从自由度为k2的卡方分布,这2 个独立的卡方分布被各自的自由度除以后的比率这一统计量的分布

其他连续型分布
对数正态分布:在对数坐标系上绘制的正态分布 我们常将强烈偏斜的分布通过对数转换成正态分布
韦伯分布:主要用于可靠性或生存数据
指数分布:指数曲线
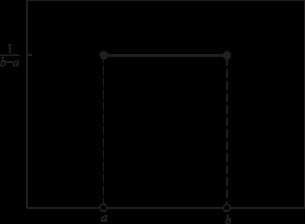
均匀分布:所有的值的可能性都相同
对数正态分布
对数正态分布,在线性横坐标(左)和对数横坐标(右)下绘制。

韦伯分布
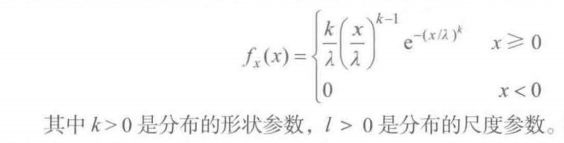
韦伯分布 所有曲线的尺度参数都是 λ=1



指数分布
概率分布函数:

指数分布

均匀分布
所有的数据值的概率都相同
假设检验
数据筛选和离群值
离群值:离祥本均值超过 1.5 x IQR (4 分位数间距),或两个以上的标准偏差之外的数据(对于正态分布的样本)
正态性检验
假设检验:
参数检验:数据可被多个参数定义
非参数检验:不依赖数据服从特定分布
概率图:
QQ-图:quantile (分位数)
PP-图:数据集和参考分布的CDF一起绘制
正态性检验
基于样本的描述性统计学的检验,例如偏度检验、峰度检验
转换
对数据进行对数转换成正态分布
假设概念、错误、P值和样本量
假设检验步骤:
从总体中抽取一个随机样本
构建一个无效假设,同时构建与无效假设对立的备择假设(无效假设:总体均值和样本均值之间没有差异)
计算已知概率分布的检验统计量(确定样本服从的概率分布,正态/t/F分布)
比较观测值的统计量(p值:probability value)
拒绝或接受假设(p值和alpha比较,P值小于alpha,则拒绝无效假设,因为在该假设前提下,小概率事件发生了,因此假设不成立)
错误的类型
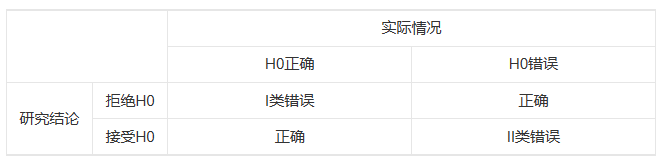
检验效能:与备择假设结合分析才有意义,它的意义是:当两总体确有差别时,按规定的检验水准.α能够发现该差别的能力
受试者操作特征(ROC)曲线
接受者操作特性曲线是指在特定刺激条件下,以被试在不同判断标准下所得的虚报概率P(y/N)为横坐标,以击中概率P(y/SN)为纵坐标,画得的各点的连线。
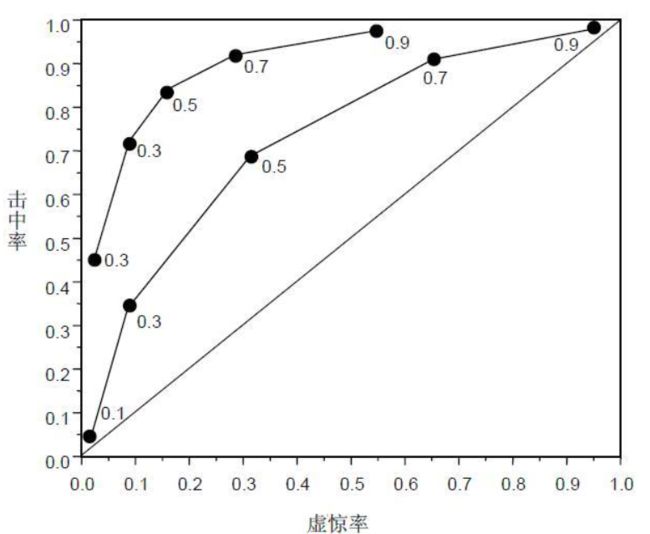
数值型数据的均值检验
样本均值的分布
单样本均值的t检验
从样本中估计均值和标准差,并用来描述来自正态分布的样本均值的t分布(标准误:平均值的标准差)

左:样本数据的频率直方图,带有正态拟合(绿线)。样本均值和总体均值非常接近,黄色三角形代表样本均值,红色三角形代表作为对比的值。右:均值的抽样分布(t 分布,自由度是 n -1)。底部是标准化的样本均值(黄色三角形)和进行比较的值(红色三角形)。红色阴影面积的和表示和红色箭头一样极端或更极端的值对应的 p 值
两组之间的比较
配对t检验
用学生们进入初中时的尺寸和他们第一年后的尺寸`来检验他们是否生长了 由于我们只是对每个个体在第一次和第二次测量之间的差异感兴趣,该检验被叫作配对t检验,该检验基本上和单样本均值t检验相对应

独立组别之间的t检验(非配对t检验)
基本 的思想和单样本t检验是一样 但我们需要的是两组之间均值差异的方差而不是均值的方差

统计学假设检验和统计学建模
1.经典t检验

2.统计学建模
建立一个统计模型,并分析模型参数的显著性

多组比较
方差分析
方差分析的思想是将方差分为组间方差和组内方差,看这些分布是否符合零假设,即所有组都来自同一分布
用于样本平均数与总体平均数或者两个样本平均数间的差异显著性检验


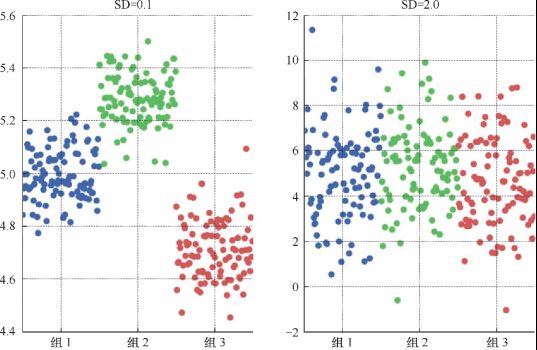
在两个例子中,两组间的差异是相同的。但在左边,组内差异比组间差异要小;而在右边,组内差异比组间差异要大
单因素方差分析
假定所有的样本都来自同方差的正态分布的总体,同方差的假设可以用 Levene 检验来检查。
多重比较:
无效假设是所有样本的均值是相同的,所以如果单因索方差分析产生了一个显著的结果,我们只知逍他们不是相同的。
进行多种检验,每一种检验用于一对样本,可以分析得到等均值假设在哪对样本中被拒绝。(一般来说,这由t检验完成)
多重检验:

两因素方差分析
观察每个因素是否显著,检查这些因素的交互因素是否对数据的分布有显著影响。
三因素方差分析
有两个以 的因素的话,建议使用统计学建校的方法进行数据分析
选择正确的检验方法进行组间比较
典型的检验

假设的例子
名义变量
2组,名义变量 男性/女性,金发/黑发 。比如,"拥有金发的女性要多于男性吗?”
2组, 配对名义量 2个实验室,分析血样 。比如,“实验室1进行的血样分析是否比实验室2的分析预示着更多的感染?”
有序变量
2组,有序变量,牙买加人/美国人,1 00 米短跑排名 比如,"牙买加短跑运动员比美国短跑运动员更成功?”
2组,配对有序变量,短跑运动员,进食前/后 。比如,”进食巧克力会让短跑运动员更成功吗?”
分类数据的检验
置信区间
样本服从分布,样本是否能代表标准总体,对样本的标准误进行假设检验,假设检验结果在置信区间内则可以代表总体。
统计建模
假设检验可以决定两组或两组以上的数据样本是否来自同一总体或不同的总体,但它们不能量化两个或多个变量之间的关系强度

线性回归模型

线性相关
相关系数
pearson方法确定相关系数

秩相关
数据不是正态分布的,需要采取不同的方法(Spearman's ,Kendall's )
对数据集的每个变量进行排序,并比较这个顺序
一般线性回归模型
用一个或多个其他的变量预测一个变量

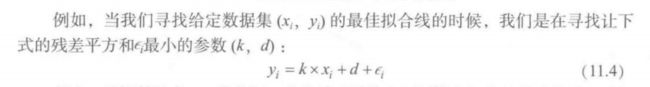
最小二乘法求最佳拟合线
决定系数R^2
多元数据分析
两个变量变为多个变量是,相关系数被相关矩阵取代,需要预测许多其他变量的值,线性回归必须被多重线性回归替代即多多元线性回归。
可视化多元相关
散点图矩阵
散点图表示不同变量之间的相关性

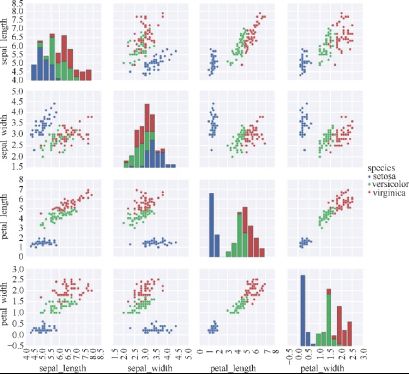
相关性矩阵



多元线性回归


离散数据检验
掷骰子,数据的离散的结果
引入广义线性模型(GLM)
GLM应用:python 实现logistic回归
贝叶斯统计学
probability 概率(P)的解释
频率学派:P为出现的频率
如果一个实验的结果有着P的概率.那意味着如果实验重复N次(其中N是个很大
的数),那么我们会观察到 Nxp 次该结果。
贝叶斯学派:P是对于一个特定结果可能性的信心
将观察到的数据固定下来,观察找到特定校型参数的可能性
贝叶斯学派和频率学派的解释
贝叶斯的优势:在计算概率P的时候应用贝叶斯定理,引入先验知识。

贝叶斯解释:概率测量的是置信度
例如,假设我们有 50% 的程度相信一个硬币正面朝上的概率是背面朝上的2倍,
如果硬币抛了很多次,并观察到了结果,那么基于这个结果,置信度可能上升、下降或保持不变
(会用到全概率法则拓展)

贝叶斯方法提供了处理参数和模型的不确定性的自然框架,借助如 PyMC或,scikit-learn 等工具进行实现