论文阅读笔记:Frequency-Aware Contrastive Learning for Neural Machine Translation
论文链接:https://arxiv.org/abs/2112.14484
author={Zhang, Tong and Ye, Wei and Yang, Baosong and Zhang, Long and Ren, Xingzhang and Liu, Dayiheng and Sun, Jinan and Zhang, Shikun and Zhang, Haibo and Zhao, Wen},
journal={arXiv preprint arXiv:2112.14484},
year={2021}
背景:
低频词预测在现代神经机器翻译(neural machine translation, NMT)系统中仍然是一个挑战。最近的自适应训练方法通过强调它们在整体训练目标中的权重来促进不常用词的输出。尽管低频词的召回率有所提高,但它们的预测精度却意外地受到自适应目标的阻碍。
作者提出了一种频率感知 token 级对比学习方法(Frequency-aware token-level Contrastive Learning
method , FCL),该方法将每个解码步骤的隐藏状态基于相应的词频率,以软对比的方式远离其他目标词的对应状态。作者在广泛使用的NIST中英任务和WMT14英语德语翻译任务进行了实验。实证结果表明,该方法不仅能显著提高翻译质量,而且还能提高词汇多样性,优化词汇表示空间。进一步的研究表明,与相关的自适应训练策略相比,FCL在低频词预测方面的优势在于在不牺牲精度的情况下,具有不同频率的标记级召回的鲁棒性。
Method
FCL首先将自回归神经机器翻译转换为一系列分类任务,并通过token级对比学习方法(TCL)来区分变压器解码器中不同目标token的隐藏表示。为了便于低频词的翻译,进一步为TCL配备了频率感知的软权值,突出了不频繁标记的分类边界。
以下是作者给出的TCL和FCL的概述示意图:

令牌级对比学习(TCL)和频率感知对比学习(FCL)的一个例子。(a)TCL对比了批处理中目标token的token级隐藏表示s。对于第一句y1中的锚定“gene”,其阳性有两个来源,即其对应的辍学噪声(用红色自指向箭头表示)和y2中的“gene”。所有其他的成批代币都是底片。(b)FCL进一步利用token频率信息来应用频率感知的软权值w(i,j)。因此,相对不频繁的标记(如“gene基因”和“alopecia脱发”)之间的对比效应被放大,它们可以在表征空间中进一步分开。
数学表达:
给定一个带有K个平行句子对的小批处理, { X k , Y k } k = 1 … K \left\{\mathbf{X}_{k}, \mathbf{Y}_{k}\right\}_{k=1} \ldots K {Xk,Yk}k=1…K,其中包含M个源token和N个目标token,第 i i i批中目标标记 y i y_{i} yi的转换概率 p ( y i ∣ y < i , x ) p(yi | y
p ( y i ∣ y < i , x ) ∝ exp ( W s ⋅ s i ) p\left(y_{i} \mid \mathbf{y}_{
- TCL 的目标可以表示为 L T C L = − 1 N ∑ i = 1 N ∑ s p ∈ S p ( i ) log e sim ( s i ⋅ s p ) ∑ j = 1 N e sim ( s i ⋅ s j ) L_{T C L}=-\frac{1}{N} \sum_{i=1}^{N} \sum_{s_{p} \in S_{p}(i)} \log \frac{e^{\operatorname{sim}\left(s_{i} \cdot s_{p}\right)}}{\sum_{j=1}^{N} e^{\operatorname{sim}\left(s_{i} \cdot s_{j}\right)}} LTCL=−N1i=1∑Nsp∈Sp(i)∑log∑j=1Nesim(si⋅sj)esim(si⋅sp)
其中, s i m ( s i ⋅ s p ) sim(s_{i}·s_{p}) sim(si⋅sp)表示 s i s_{i} si和 s p s_{p} sp之间的余弦相似性。这里, s p ( i ) = S s u p ( i ) ∪ S d r o p ( i ) sp(i)=S_{sup}(i)∪ S_{drop}(i) sp(i)=Ssup(i)∪Sdrop(i)是yi的所有积极实例集。 S s u p ( i ) = { s p : p ≠ i , p = 1 … N , y p = y i } S_{sup}(i)=\{s_{p} : p \neq i,p=1…N,y_{p}=y_{i} \} Ssup(i)={sp:p=i,p=1…N,yp=yi}表示监督对比设置中的积极因素, S d r o p ( i ) = { s i ′ } S_{drop}(i)=\left\{s_{i}^{\prime}\right\} Sdrop(i)={si′}是由漏失噪声构建的对应因素。
最后,总体训练目标结合了传统的NMT目标 L M T L_{MT} LMT和token级对比目标 L T C L L_{TCL} LTCL:
L = L M T + λ L T C L L = L_{MT}+ \lambda L_{TCL} L=LMT+λLTCL - FCL的目标可以表示为 L F C L = − 1 N ∑ i = 1 N ∑ s p ∈ S p ( i ) log e sim ( s i ⋅ s p ) ∑ j = 1 N w ( i , j ) e sim ( s i ⋅ s j ) L_{F C L}=-\frac{1}{N} \sum_{i=1}^{N} \sum_{s_{p} \in S_{p}(i)} \log \frac{e^{\operatorname{sim}\left(s_{i} \cdot s_{p}\right)}}{\sum_{j=1}^{N} w(i, j) e^{\operatorname{sim}\left(s_{i} \cdot s_{j}\right)}} LFCL=−N1i=1∑Nsp∈Sp(i)∑log∑j=1Nw(i,j)esim(si⋅sj)esim(si⋅sp)
其中 w ( i , j ) w(i,j) w(i,j)根据锚点yi和负样本 y j y_{j} yj的频率是一个软权重:
w ( i , j ) = γ f ( y i ) f ( y j ) f ( y i ) = 1 − log ( Count ( y i ) ) max j = 1 … N log ( Count ( y j ) ) w(i, j)=\gamma f\left(y_{i}\right) f\left(y_{j}\right) \\ f\left(y_{i}\right)=1-\frac{\log \left(\operatorname{Count}\left(y_{i}\right)\right)}{\max _{j=1 \ldots N} \log \left(\operatorname{Count}\left(y_{j}\right)\right)} w(i,j)=γf(yi)f(yj)f(yi)=1−maxj=1…Nlog(Count(yj))log(Count(yi))
其中, f ( y i ) f(y_{i}) f(yi)和 f ( y j ) f(y_{j}) f(yj)分别为 y i y_{i} yi和 y j y_{j} yj的个体频率得分。 γ γ γ是 w ( i , j ) w(i,j) w(i,j)的一个比例因子。 c o u n t ( y i ) count(y_{i}) count(yi)表示训练集中 y i yi yi的单词计数。锚点 y i y_{i} yi的所有负值的频率感知权值的平均值被归一化为1。
最后,总体训练目标结合了传统的NMT目标 L M T L_{MT} LMT和频率感知对比目标 L F C L L_{FCL} LFCL:
L = L M T + λ L F C L L = L_{MT}+ \lambda L_{FCL} L=LMT+λLFCL
实验结果
1.下图是作者在 NIST Zh-En 和 WMT14 En-De 实验的主要结果。可以看出使用 TCL 和 FCL 都在各方面上有了显著提升。

2.低频标记对翻译质量的影响,不同方法在 “High”, “Middle”, “Low”三个子集上的BLEU得分:

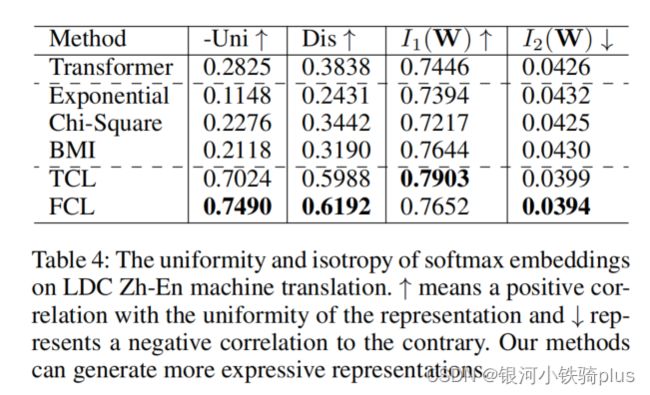
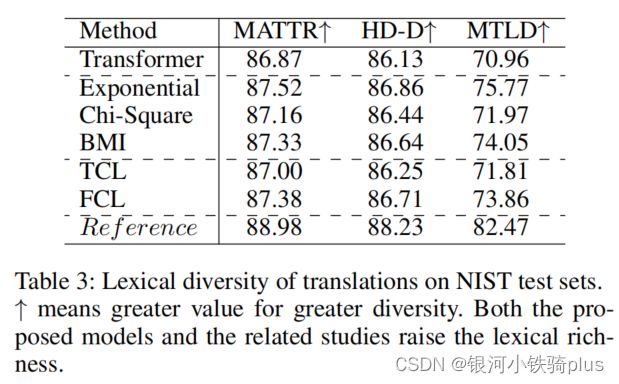
3.词汇多样性
统计了基于NIST测试集上的翻译结果的三个词汇多样性度量
4.对token级别预测的影响

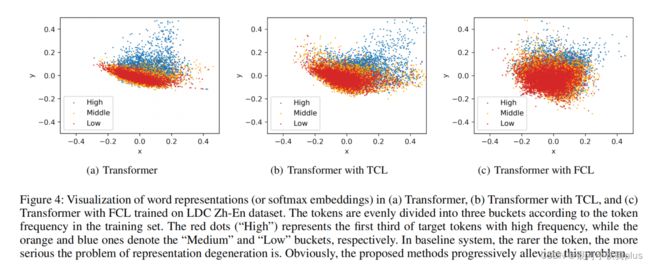
5.对表示学习的影响