分布式学习第三天—远程调用和网关
Feign远程调用
Feign的介绍
Feign是一个声明式的http客户端,官方地址:https://github.com/OpenFeign/feign
其作用就是帮助我们优雅的实现http请求的发送
Feign远程调用的使用步骤
1.引入依赖
在子模型服务的pom文件中引入feign的依赖:
org.springframework.cloud
spring-cloud-starter-openfeign
2.添加注解
@EnableFeignClients在子模型的启动类添加注解开启Feign的功能:
3.编写Feign的客户端
在子模型中新建一个接口,内容如下:
@FeignClient("userservice")
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}测试
修改order-service中的OrderService类中的queryOrderById方法,使用Feign客户端代替RestTemplate:
总结
使用Feign的步骤:
① 引入依赖
② 添加@EnableFeignClients注解
③ 编写FeignClient接口
④ 使用FeignClient中定义的方法代替RestTemplate
配置文件方式
基于配置文件修改feign的日志级别可以针对单个服务:
feign:
client:
config:
userservice: # 针对某个微服务的配置
loggerLevel: FULL # 日志级别
也可以针对所有服务(默认拦截器))
feign:
client:
config:
default: # 这里用default就是全局配置,如果是写服务名称,则是针对某个微服务的配置
loggerLevel: FULL # 日志级别
而日志的级别分为四种:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
Feign性能优化
Feign的性能优化
Feign底层发起http请求,依赖于其它的框架。其底层客户端实现包括:
•URLConnection:默认实现,不支持连接池
•Apache HttpClient :支持连接池 常用
•OKHttp:支持连接池
因此提高Feign的性能主要手段就是使用连接池代替默认的URLConnection。
连接池的配置
1.子模型的pom文件中引入Apache的HttpClient依赖
io.github.openfeign
feign-httpclient
2.配置连接池
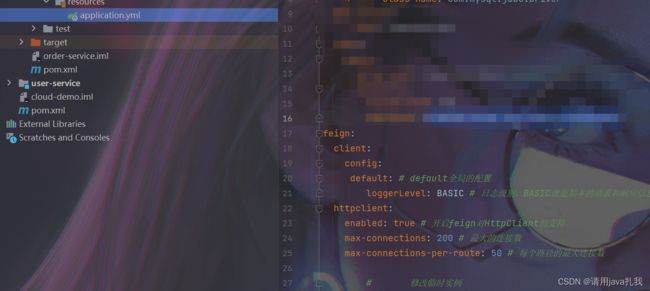
在子模型的application.yml中添加配置:
feign:
client:
config:
default: # default全局的配置
loggerLevel: BASIC # 日志级别,BASIC就是基本的请求和响应信息
httpclient:
enabled: true # 开启feign对HttpClient的支持
max-connections: 200 # 最大的连接数
max-connections-per-route: 50 # 每个路径的最大连接数
总结,Feign的优化:
1.日志级别尽量用basic】
2.使用HttpClient或OKHttp代替URLConnection
① 引入feign-httpClient依赖
② 配置文件开启httpClient功能,设置连接池参数
Gateway网关
1.为什么需要网关
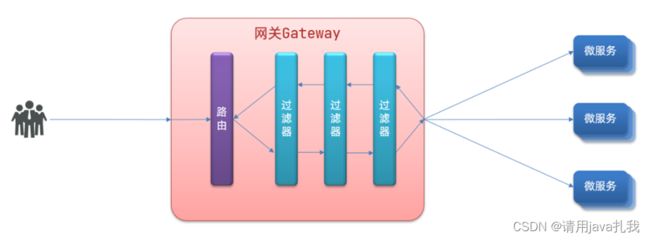
Gateway网关是我们服务的守门神,所有微服务的统一入口。
网关的核心功能特性:
- 请求路由
- 路由和负载均衡:一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务,这个过程叫做路由。当然路由的目标服务有多个时,还需要做负载均衡
- 权限控制
- 权限控制:网关作为微服务入口,需要校验用户是是否有请求资格,如果没有则进行拦截。
- 限流
- 当请求流量过高时,在网关中按照下流的微服务能够接受的速度来放行请求,避免服务压力过大。

在SpringCloud中网关的实现包括两种:
- gateway
- zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能。
Gateway快速搭建
1.创建项目并且引入依赖:
org.springframework.cloud
spring-cloud-starter-gateway
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-discovery
2)编写启动类
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
3. 编写基础配置和路由规则
创建application.yml文件,内容如下:
server:
port: 10010 # 网关端口
spring:
application:
name: gateway # 服务名称
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes: # 网关路由配置
- id: user-service # 路由id,自定义,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址
uri: lb://userservice # 路由的目标地址 lb就是负载均衡,后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求
我们将符合Path 规则的一切请求,都代理到 uri参数指定的地址。
本例中,我们将 /user/**开头的请求,代理到lb://userservice,lb是负载均衡,根据服务名拉取服务列表,实现负载均衡。
网关路由的流程图

网关搭建步骤:
- 创建项目,引入nacos服务发现和gateway依赖
- 配置application.yml,包括服务基本信息、nacos地址、路由
路由配置包括:
- 路由id:路由的唯一标示
- 路由目标(uri):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
- 路由断言(predicates):判断路由的规则,
- 路由过滤器(filters):对请求或响应做处理
断言工厂

过滤器分类
1.路由过滤器
Spring提供了31种不同的路由过滤器工厂。例如:
2.请求头过滤器
下面我们以AddRequestHeader 为例来讲解。
需求:给所有进入userservice的请求添加一个请求头:Truth=itcast is freaking awesome!
只需要修改gateway服务的application.yml文件,添加路由过滤即可
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
filters: # 过滤器
- AddRequestHeader=Truth, tledu is freaking awesome! # 添加请求头
![]()
4.默认过滤器DefaultFilter
如果要对所有的路由都生效,则可以将过滤器工厂写到default下。格式如下
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
default-filters: # 默认过滤项
- AddRequestHeader=Truth, tledu is freaking awesome!
5.全局过滤器GlobalFilter
1.全局过滤器作用
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的;而GlobalFilter的逻辑需要自己写代码实现。
在filter中编写自定义逻辑,可以实现下列功能:
- 登录状态判断
- 权限校验
- 请求限流等
过滤器执行顺序
请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:
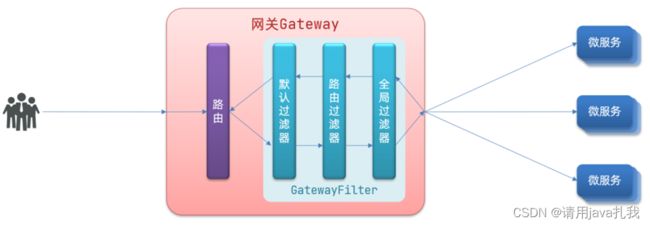
排序的规则是什么呢?
- order值越小,优先级越高,执行顺序越靠前。
- GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
- 路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。
- 当过滤器的order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行。
总结
过滤器的作用是什么?
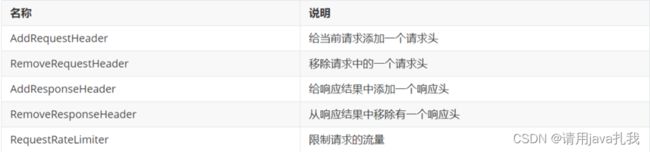
① 对路由的请求或响应做加工处理,比如添加请求头
② 配置在路由下的过滤器只对当前路由的请求生效