三维点云语义分割模型介绍
三维点云语义分割模型介绍
- 1 三维深度学习简介
-
- 1.1 三维数据表达方式
- 2 PointNet
-
- 2.1 点云的属性
-
- 2.1.1 无序性
- 2.1.2 关联性
- 2.1.3 不变性
- 2.2 key modules
-
- 2.2.1 Symmetry Function for Unordered Input
- 2.2.2 Local and Global Information Aggregation
- 2.2.3 Joint Alignment Network
- 2.3 网络结构
- 3 PointNet++
-
- 3.1简介
- 3.2 key modules
-
- 3.2.1 Hierarchical Point Set Feature Learning
- 3.2.2 Robust Feature Learning under Non-Uniform Sampling Density
- 3.2.3 Point Feature Propagation for Set Segmentation
- 3.3 网络结构
- 4 PointSIFT
-
- 4.1 key module
-
- 4.1.1 Orientation-encoding Convolution
- 4.2 网络结构
- 5 Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds
-
- 5.1 简介
- 5.2 key modules
-
- 5.2.1 Input-Level Context
- 5.2.2 Consolidation Units(CU)
- 5.2.3 Recurrent Consolidation Units(RCU)
- 5.3 网络结构
-
- 5.3.1 MS-CU
- 5.3.2 GB-RCU
- 6 模型调试
-
- 6.1 模型训练
-
- 6.1.1模型输入
- 6.1.2 模型输出
- 6.2 模型调用
-
- 6.2.1 数据处理
- 6.2.2 语义分割结果
- 相关链接
-
- PointNet
- PointNet++
- PointSIFT
- 参考博客
1 三维深度学习简介
前段时间调试了上海交大卢策吾教授团队提出的PointSIFT模型,也在此过程中阅读了一些三维点云语义分割的深度学习模型,下面对每个模型进行介绍(在文末会有模型对应的论文),并且展示一下我自己调试的PointSIFT模型的运行结果。
1.1 三维数据表达方式
目前用于深度学习的三维数据有如下几种表达方式:
1) 多视角(multi-view):通过多视角二维图片组合为三维物体,此方法将传统CNN应用于多张二维视角的图片,特征被view pooling procedure聚合起来形成三维物体;
2) 体素(volumetric):通过将物体表现为空间中的体素进行类似于二维的三维卷积(例如,卷积核大小为5 x 5 x 5),是规律化的并且易于类比二维的,但同时因为多了一个维度出来,时间和空间复杂度都非常高,目前已经不是主流的方法了;
3) 点云(point clouds):直接将三维点云抛入网络进行训练,数据量小。主要任务有分类、分割以及大场景下语义分割;
4) 非欧式(manifold graph):在流形或图的结构上进行卷积,三维点云可以表现为mesh结构,可以通过点对之间临接关系表现为图的结构。
2 PointNet
2.1 点云的属性
三维空间中的点云存在下面三个主要的属性,文章根据点云的这三个属性提出了对应的三个模型从而解决了直接利用点云进行深度学习存在的问题。
2.1.1 无序性
点云本质上是一长串点(nx3矩阵,其中n是点数)。在几何上,点的顺序不影响它在空间中对整体形状的表示,相同的点云可以由两个完全不同的矩阵表示,如图2.2.1所示。

而实际情况下,不论点云的输入顺序如何,都希望模型能够提取出相同的特征。
2.1.2 关联性
点云中的每个点不是孤立的,点与点之间存在着关联,相邻的许多点可能组成一个具有重要意义的子集,它包含了点云的局部特征。因此希望模型能够捕捉到点与点之间的关联、点云的局部结构从而提取出点云的局部特征。
2.1.3 不变性
相同的点云在空间中经过一定的刚性变化(旋转或平移),点的坐标会发生变化,但是模型进行分类或者语义分割的结果不会发生变化。
2.2 key modules
2.2.1 Symmetry Function for Unordered Input
如2.1所述,为了使模型对相同点云的不同顺序的输出不变,文章中提出了3种方法:1)将不同输入按一定规则排列成统一的顺序;2)将输入的点云当成是一个序列用来训练循环神经网络(RNN),通过改变顺序来增加训练数据,从而使得RNN的输出结果对顺序不变;3)通过一个形式简单的对称函数聚合每个点的信息。第3种方法为作者提出,经验证,第3种方法效果最好,精度可达87.1%。第三种方法如图2.2.1所示。

第3种方法首先先利用多层神经网络提取每个点的特征(n x c),最后通过对称函数g对C维特征种每一维都选取n个点中对应的最大特征值或特征值总和,这样就可以通过g来解决无序性问题。PointNet采用了max-pooling策略。
2.2.2 Local and Global Information Aggregation
2.2.1中的模型最终输出了一个向量V(维度为1 x C1),它代表输入点云的全局特征,对于分类任务来说,可以采用一个全连接层得出分类结果,但是对于分割任务来说需要结合点云的局部信息和全局信息。
所以在分割任务中,在得到点云的全局特征后,将全局特征和每一个点的特征进行连接,得到一个矩阵(维度为n x(C1+C2)),此时每个点的特征中都包含各自的局部信息和全局信息。
2.2.3 Joint Alignment Network
PointNet通过T-Net这一小型神经网络,通过学习一个C x C的仿射变换矩阵,并在特征提取之前,将这个矩阵和输入进行矩阵运算,将输入变换到一个统一的特征空间中,使得模型的输出结果不会因为点云发生刚性变换后而改变。
2.3 网络结构
PointNet的网络结构如图2.3.1所示。
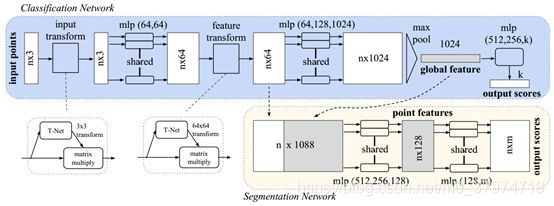
图中蓝色部分是处理分类任务时的网络,网络直接采用原始点云数据作为输入(n x 3),输出是点云在k个类别上的得分。粉色部分是处理分割任务时的额外网络,输出是每个点在各个类别上的得分(n x m)。
其中,mlp是通过共享权重的卷积实现的,第一层卷积核大小是1 x 3(因为每个点的维度是xyz),之后的每一层卷积核大小都是1 x 1。经过两个空间变换网络和两个mlp之后,对每一个点提取1024维特征,经过max pool变成1x1024的全局特征。再经过一个mlp(代码中运用全连接)得到k个score,分类网络最后接的loss是softmax。
T-net与一般的网络类似,由特征提取层、池化层和全连接层组成。T-net在PointNet中应用了2次,第一次是直接对输入的点云数据进行变换,第二次是对提取出的64维特征进行变换。并且PointNet在损失函数中引入了正则化项,使得在第二次应用T-net后习得的特征变换矩阵近似为一正交矩阵,降低了网络优化的复杂程度。
3 PointNet++
3.1简介
PointNet只是简单的将所有点连接起来,只考虑了全局特征,但丢失了每个点的局部信息。因此在提出PointNet之后不久,作者提出了了PointNet++。
PointNet++基本思想就是:首先选取一些比较重要的点作为每一个局部区域的中心点,然后在这些中心点的周围选取k个近邻点(欧式距离)。再将k个近邻点作为一个局部点云采用PointNet网络来提取特征。它本质上是PointNet的分层版本,每个图层都有三个子阶段:采样,分组和特征提取。然后不断重复这个过程。此外,作者还测试了不同层级的一些不同聚合方法,以克服采样密度的差异。
3.2 key modules
3.2.1 Hierarchical Point Set Feature Learning
PointNet使用了一个单独的max pooling作为对称函数用于抽取点集的全局特征。而PointNet++使用了分层抽取特征的思想,把每一次叫做set abstraction(SA),SA分为三部分:采样层(Sampling layer)、分组层(Grouping layer)和特征提取层(PointNet)。
首先来看采样层,从稠密的点云中抽取出一些相对较为重要的中心点,采用最远点采样法(farthest point sampling,FPS),相较于随机采样FPS算法可以更好地覆盖整个点集。采样层的输入是n1 x 3,输出是n2 x 3。
然后是分组层,在上一层提取出的中心点的某个范围内寻找最近个k近邻点组成group,寻找邻近点的方法有球查询算法和K-NN算法。分组层的输入是中心点n2 x 3和上一层点的特征n1 x(3+C),输出是n2 x n_sample x (3+C)。
特征提取层是将这k个点通过小型PointNet网络进行卷积和pooling得到的特征作为此中心点的特征,再送入下一个分层继续。这样每一层得到的中心点都是上一层中心点的子集,并且随着层数加深,中心点的个数越来越少,但是每一个中心点包含的信息越来越多。特征提取层的输入是n2 x n_sample x (3+C),输出是n x C2。
因此在实际训练中,整个SA level的输入为上一层的中心点(B x n1 x 3)和上一层的提取的特征(B x n1 x C1),输出是经过这一层的处理后得到的中心点(B x n2 x 3)和中心点对应局部区域的特征(B x n2 x C2)。
3.2.2 Robust Feature Learning under Non-Uniform Sampling Density
在实际情况中,点云数据很有可能在不同的区域具有不同的密度,这种点集的不均匀性会使模型在密集区域学习到的特征有可能无法推广到稀疏的区域,而针对稀疏区域训练的模型可能无法识别密集区域的局部结构。
在高密度的情况下,希望模型尽可能接近地检查点集,以捕获密集采样区域中最精细的细节。但是在低密度区域,样本缺陷会破坏局部模式,此时我们应该在更大的附近寻找更大规模的模式。所以通过固定范围选取的固定个数的近邻点是不合适的,PointNet++提出了两个解决方案,见图3.2.1。

a)多尺度分组(Multi-scale grouping,MRG)。MRG在每一个分组层都通过多个尺度来确定每一个中心点的邻域范围,并经过Point提取特征之后将多个特征联合起来,得到一个多尺度的新特征。在低尺度下,MRG方法的计算量很大。
b)多分辨率分组(Multi-resolution grouping,MSG)。如图3.2.1(b)所示,新特征通过两部分连接起来。左边特征向量是通过一个SA后得到的,右边特征向量是直接对当前group中所有点进行PointNet卷积得到。当点云密度不均时,可以通过判断当前group的密度对左右两个特征向量给予不同权重:当group中密度很小,左边向量得到的信息就没有对所有group中点提取的特征可信度更高,于是将右特征向量的权重提高。以此达到减少计算量的同时解决密度问题。
3.2.3 Point Feature Propagation for Set Segmentation
SA过程在点集上进行了降采样,而分割任务则需要获取每一个点的特征,PointNet++通过feature propagation层(FP)将点的特征从降采样点传递回原始点集,在FP中通过利用上一层的点集的特征内插出更原始的点集的特征,并且通过skip link将在SA过程中相应的点特征与内插的特征连接起来,构成一个新的特征向量,然后对这个新的特征向量进行数次卷积。最后不断重复FP,直到将特征传递回原始点集。
3.3 网络结构
PointNet++的网络结构如图3.3.1所示。

图中右下部分是处理分类任务时的网络,网络直接采用原始点云数据作为输入(n x 3),输出是点云在k个类别上的得分。右上部分是处理分割任务时的额外网络,输出是每个点在各个类别上的得分(n x m)。
4 PointSIFT
4.1 key module
4.1.1 Orientation-encoding Convolution
为了使模型更好地捕获形状模式,需要编码在不同方向上的形状信息。PointSIFT类比SIFT算法提出了方向编码卷积这一方法:对于一个给定点p,以它为中心的8个卦限代表了8个不同的方向。在每个卦限中,PointSIFT都在搜索半径r内搜索最近的点,以这个最近的点的特征f代表这个卦限。为了捕捉8个方向的特征,PointSIFT进行了3次方向编码卷积,在卷积后每个点的特征都以一个d维的向量来表征。方向编码卷积的示意图如图4.1.1所示。
4.2 网络结构
PointSIFT的网络结构如图4.2.1所示。

PointSIFT网络的输入是原始点云数据(n x 3),对于语义分割任务,输出是每一个在各个类别上的得分(n x m)。
如图4.2.1所示,PointSIFT网络分为两大部分,分别是编码(下采样)和解码(上采样)。PointSIFT首先先通过一个MLP提取点云数据的特征(实际模型中这部分MLP和PointSIFT结合起来了),对每个点都得到一个64维的特征向量(n x 64),然后利用PointNet++的SA module进行了3次下采样,点的数量变化:8192->1024->256->64。对于解码部分,PointSIFT同样利用PointNet++中的FP module进行了3次上采样,点的数量变化:64->256->1024->8192。并且在上采样和下采样的过程中,PointSIFT module是插入在上下两个解码(编码)层之间的。模型的最后接了全连接层,得到每个点的类别得分。
在实验中,通过将PointSIFT module插到两个SA之间可以捕捉到所有的点,从而有效的避免在下采样过程中点的信息损失。
5 Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds
5.1 简介
PointNet是3D点云语义分割方面迈出了一大步,它直接处理非结构化的点云并且取得了较好的语义分割结果。但是,PointNet将输入的点细分为一个个块(个人理解为训练模型时的一个个Batch)并且独立的处理这些Block。在本文中,作者在PointNet的基础上提出了两种扩展模型,增大了模型在3D场景中的感受野,从而使模型可以处理更大尺度的空间场景。
5.2 key modules
5.2.1 Input-Level Context
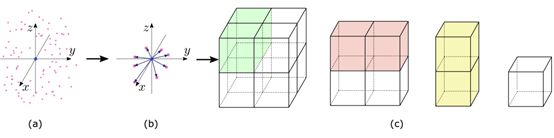
Input-level context是直接对输入的点云进行处理,通过同时考虑一系列Block而不是像PointNet中考虑一个个单独的Block,一组中的Block之间共享上下文信息。Block有两种选取方式,一种是在位置相同,但是尺度不同(Multi-Scale Blocks);另一种是从相邻的格网中选取(Grid Blocks)。
1) Multi-Scale Blocks。通过随机选取一个D维的点作为中心,然后在中心点特定半径内选取N个点,将它们组合成一个Block。通过改变不同的半径从而得到Multi-Scale Blocks,Multi-Scale Blocks如图5.2.1所示。

2) Grid Blocks。Grid blocks是一组2 x 2的格网领域。每个Block位置不同但是尺度相同,如图5.2.2所示。
5.2.2 Consolidation Units(CU)
CU和RCU均是处理Output-level context,它们将合并得到的块特征。先是CU的处理方式:CU先通过MLP将之前阶段得到的特征集映射到更高维的空间,然后应用max-pooling生成公共块特征,然后将该特征与MLP得到的O个高维特征进行连接。

5.2.3 Recurrent Consolidation Units(RCU)
RCU将来自空间邻近块的块特征序列作为输入,并返回更新后的块特征序列。RCU是通过GRU实现的。GRU具有学习远程依赖性的能力,范围可以是时间上的也可以是空间上的,GRU在看到块特征的全部输入序列后才会返回更新的块特征,GRU在其内部存储器中保留有关场景的信息,并根据新的观察结果进行更新,通过这种机制来整合和共享所有输入的信息。

5.3 网络结构
5.3.1 MS-CU
MS-CU网络结构如图5.3.1所示。

网络的输入是三个多尺度的Blocks,每一个Block都含有N个D维的点(不一定是3维的,除了坐标信息外还有可能包括标准化后的坐标以及点的RGB信息等)。通过一个类似PointNet的机制学习每一个Scale下的block的特征(MLP->max-pooling)。然后将块特征(1 x 384)和输入特征进行连接,将连接后的特征作为一系列CU的输入,网络最后接一个MLP输出每一个点在所有类别上的得分(N x M)。
最开始,每个点只能得到它们各自的特征,连接了块特征后,每个点还得到了其相邻点的特征,通过一系列CU后,这种共享特征得到了反复的加强。
5.3.2 GB-RCU
GB-RCU网络结构如图5.3.1所示。
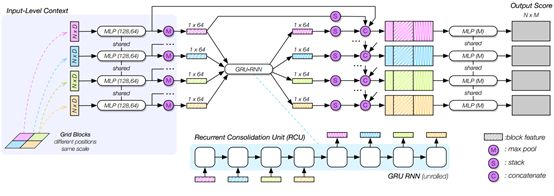
GB-RCU网络的输入是4个来自相邻格网的blocks,每个blocks中都包含由N个D维的点。它通过一个共享权重的MLP和max-pooling学习4个块的特征(4 x 1 x 64,区别于MS-CU),所有的块特征通过一个RCU共享各自的空间上下文,然后RCU返回更新后的块特征。更新后的块特征(1 x 64)和原始块特征(1 x 64)一起附加到输入特征(N x 64)。最后接一个MLP用于计算每一个点在各个类别上的得分(N x M)。
6 模型调试
6.1 模型训练
6.1.1模型输入
调式的模型为PointSIFT,初次调试模型输入的是利用RGB-D相片反演出的点云数据(ScanNet数据集),属于不同类的点具有不同类别的标签,如图6.1.1所示。

6.1.2 模型输出
对于语义分割任务,模型的输出是每个点所属的类别,如图6.1.2所示。

目前训练模型在测试集上的精度为83%(论文中为86%)。
6.2 模型调用
6.2.1 数据处理
利用三维激光扫描仪对室内进行扫描,得到室内点云数据,点云数据量约为30000000,直接用于模型预测过于稠密,因此对点云进行抽稀,并对一些噪声点进行处理,最后得到点296242个。对数据进行剖分,分为3个场景,前两个场景各100000个点,最后一个场景96242个点。室内图见6.2.1。

6.2.2 语义分割结果
调用模型对点云数据进行预测,预测的一些结果如图6.2.2所示,其中红色代表地板;绿色代表墙体;蓝色代表椅子;黄色代表桌子;白色代表剩余的家具;黑色代表未定义。


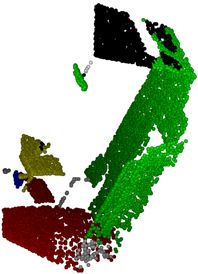

前三张图是利用OpenCV进行可视化的,最后一张室内全景图是利用专业的三维激光点云软件进行显示。
相关链接
PointNet
论文 https://arxiv.org/abs/1612.00593
Github https://github.com/charlesq34/pointnet
PointNet++
论文 https://arxiv.org/abs/1706.02413
Github https://github.com/charlesq34/pointnet2
PointSIFT
论文 https://arxiv.org/abs/1807.00652
Github https://github.com/MVIG-SJTU/pointSIFT
参考博客
https://blog.csdn.net/Felaim/article/details/81088936
https://blog.csdn.net/qq_15332903/article/details/80224387