php 正则表达式获取html标签内容_爬虫系列第三篇 使用requests与正则表达式爬取豆瓣电影Top250...
在本篇中,我们将使用requests库与正则表达式实现我们的第一个爬虫---爬取豆瓣电影Top250。写一个爬虫前,首先应该分析网页结构,然后明确自己想要爬取的信息,最后才是写爬虫。
一、网页分析
我们要抓取的网页url为https://movie.douban.com/top250,打开之后即可看到榜单信息,如图所示。
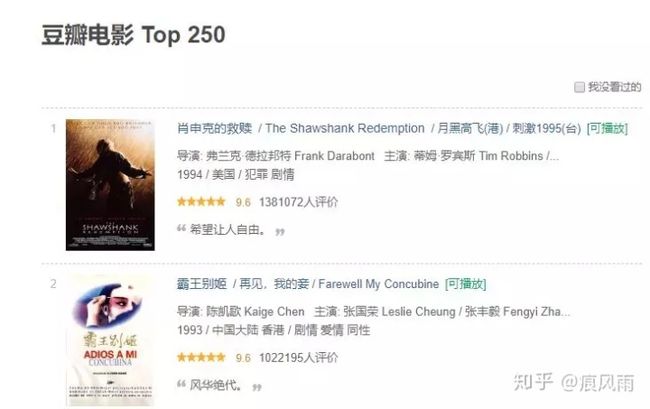
可以看到每一个电影显示的信息有排名、电影名、导演与主演、上映时间/地点/类型、评分及评价人数、推荐语,所以我们可以将上述信息全部爬取下来。
将网页拉到最下方,可以看到有10页分页列表,每页25条电影信息,如图

我们点击每一个页面,观察其url的变化规律,第二页的url为https://movie.douban.com/top250?start=25&filter=,第三页url为https://movie.douban.com/top250?start=50&filter=,第四页url为https://movie.douban.com/top250?start=75&filter=,至此,已经能够观察到url的变化规律了,每一页以25递增,现在我们将第一页的url改为https://movie.douban.com/top250?start=0&filter=也能成功请求。所以,我们可以将10页的url放入一个列表,然后就可以循环请求,得到网页源代码后,再用正则表达式提取信息。
二、本例目标
爬取每一个电影的排名、电影名、导演与主演、上映时间/地点/类型、评分及评价人数、推荐语。
OK,No BB,show your code!
三、写爬虫
为了呈现写爬虫的思路,我就不贴整个代码了,而是一步步的实现。首先,对于这种分页的网站,我们可以首先尝试爬取首页的信息,如果首页成功爬取的话,再加一个循环即可爬取所有页面。
- 爬取豆瓣首页
回忆一下前面介绍的爬虫流程,首先是请求网页,然后是解析提取所需信息,最后是将爬取的信息保存下来。接下来我们用代码一步步实现。
(1)请求网页,获取网页源代码
import requests
def get_html(url):
'''Request a web page and get the source code'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
}
try:
html = requests.get(url,headers=headers)
return html.text
except requests.exceptions.RequestException:
print(url,'请求失败')
if __name__ == '__main__':
url = 'https://movie.douban.com/top250?start=0&filter='
print(get_html(url))在这段代码中,我们将对网页的请求封装为函数get_html(),并要求传入要请求的url。在get_html()中,构造并向get()传入了headers参数进行伪装,防止反爬,并且我们加入了异常处理,保证爬虫的健壮性。
最后我们使用
if __name__=='__main__':
来对整个程序进行调度,这一部分代码可以简单理解为通常的main()函数的功能。这段代码的运行结果如图,可见成功获取了源代码。

(2)解析HTML,提取所需信息
接下来我们使用正则表达式提取所需信息,首先在豆瓣Top250首页第一个电影旁右键检查打开开发者模式
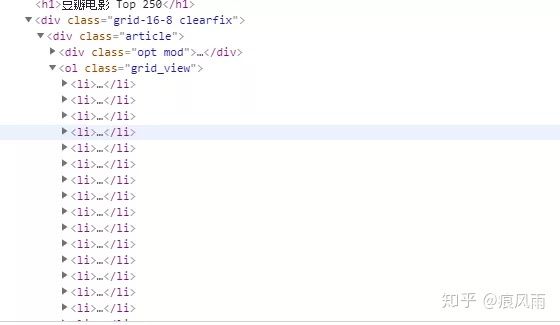
可以看到有很多的
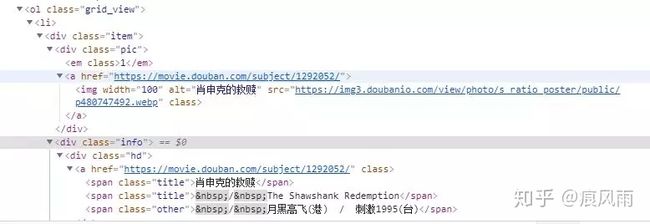
我们首先尝试提取各个电影的名字,代码如下
import requests
import re
def get_html(url):
'''Request a web page and get the source code'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
}
try:
html = requests.get(url,headers=headers)
return html.text
except requests.exceptions.RequestException:
print(url,'请求失败')
def parse_html(html):
'''Parse the HTML and extract the information you need'''
title = re.findall('(.*?).*?"> ',html,re.S)
return title
if __name__ == '__main__':
url = 'https://movie.douban.com/top250?start=0&filter='
html = get_html(url)
print(parse_html(html))输出结果为
为了解析HTML,我们定义了一个函数parse_html(),传入参数为HTML源代码。为了提取电影名,我们首先关注源代码中包含电影名的部分,如下图所示:
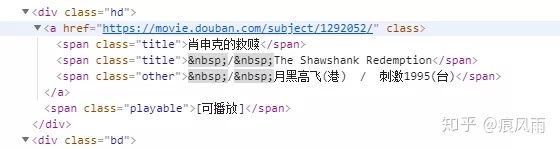
可以看到电影名称很多,不仅有我们熟悉的名字,还有很多别名,这里我们只提取熟悉的名称,我们的正则表达式从开始匹配,然后括号里是我们需要的信息,本来以结束即可,但是可以看到这会将其它的别名也提取出来,所以我们的正则表达式会多匹配一些内容,直到 结束。理解了电影名称的提取后,接下来我们一次性提取所有信息,下面只贴parse_html()的代码。
def parse_html(html):
'''Parse the HTML and extract the information you need'''
pattern = '''.*?(.*?).*?(.*?).*?(.*?)
.*?.*?property="v:average">(.*?).*?(.*?).*?(.*?).*?'''
information = re.findall(pattern,html,re.S)
return information
运行结果

可以看到,信息是提取出来了,但是太过杂乱,所以我们需要进行适当的处理。这里先说一下上面代码中那个长长的正则表达式,这里建议一个信息一个信息的加,而不是像这样子一下子将全部信息的正则表达式写下来,这样子一般会出错。什么意思呢?就是说你先写提取排名的正则表达式,如果成功提取了再往后添加提取电影名称的正则表达式,这样依次添加。接下来我们将刚提取的信息整理一下:
def parse_html(html):
'''Parse the HTML and extract the information you need'''
pattern = '''.*?(.*?).*?(.*?).*?(.*?)
.*?.*?property="v:average">(.*?).*?(.*?).*?(.*?).*?'''
informations = re.findall(pattern,html,re.S)
datas = []
for information in informations:
info = re.sub('s','',information[2])
info = re.sub(' ','',info)
info = re.sub('...
','',info)
infos = info.split('/')
if len(infos) == 3:
infos.append(infos[2])
infos[2] = infos[1]
infos[1] = re.sub('D','',infos[1])
if infos[1]=='':
infos[1] = infos[0][-4:-1]+infos[0][-1]
infos[0] = re.sub('d','',infos[0])
while(len(infos)>4):
del infos[1]
data = {
'电影排名' : information[0],
'电影名称' : information[1],
'导演及主演':infos[0],
'上映时间': infos[1],
'上映地点':infos[2],
'电影类型':infos[3],
'评分' : information[3],
'评价人数' : information[4],
'推荐语':information[5]
}
datas.append(data)
return datas
上述代码中,由于informations列表中的的第二个元素包含很多信息同时最为杂乱,所以我将其单独拿出来进行处理,通过一系列的替换、拆分将其变为包含导演及主演、上映时间、上映地点、电影类型的列表,最后将所有信息整合为一个字典的列表,其中每一个字典为一部电影的信息。然后我们将获得的datas字典有序的打印出来:
if __name__ == '__main__':
url = 'https://movie.douban.com/top250?start=0&filter='
html = get_html(url)
datas = parse_html(html)
for data in datas:
for key,value in zip(data.keys(),data.values()):
print(key+':'+value)
print('n')
输出结果如下:

(3)将提取的信息写入txt文件中
我们爬取的信息是为了进行使用的,为了以后方便使用,我们一般要对爬取的信息进行保存,这里将爬取的信息保存为TXT文本。
def save_to_file(datas):
with open('C:/Users/asus/Desktop/豆瓣电影Top250.txt','a',encoding='utf-8') as f:
f.write(json.dumps(datas,ensure_ascii=False)+'n'
这里,我们使用json的dumps()方法将有序输出到txt文本中,需要注意的是,这里需要导入json库,并且设置dumps()方法的ensure_ascii参数为False,从而保证输出的为中文而不是Unicode码。保存结果如下

至此,我们便已经完成了第一页的数据爬取和保存工作,接下来,我们整个豆瓣电影Top250的信息爬取下来。
- 爬取整个豆瓣Top250
由于我们已经将网页请求、HTML解析和数据保存都封装为函数,所以我们仅仅需要对每个url调用相应函数即可。我们首先应该先构造10页的url列表,前面网页分析得到每页的url以25递增,所以我们只需要改变url中的start=的值即可,然后将每一个url加进列表,然后循环即可,代码如下:
if __name__ == '__main__':
urls = ['https://movie.douban.com/top250?start={}&filter='.format(i*25) for i in range(0,10)]
for url in urls:
html = get_html(url)
datas = parse_html(html)
save_to_file(datas)
for data in datas:
for key,value in zip(data.keys(),data.values()):
print(key+':'+value)
print('n')
sleep(1) #为了防止请求频率过快被反爬,加入延时
运行结果如下:

可见我们已将250部电影的信息爬取下来,大功告成!
四、全部代码
import requests
import re
import json
def get_html(url):
'''Request a web page and get the source code'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
}
try:
html = requests.get(url,headers=headers)
return html.text
except requests.exceptions.RequestException:
print(url,'请求失败')
def parse_html(html):
'''Parse the HTML and extract the information you need'''
pattern = '''.*?(.*?).*?(.*?).*?(.*?)
.*?.*?property="v:average">(.*?).*?(.*?).*?(.*?).*?'''
informations = re.findall(pattern,html,re.S)
datas = []
for information in informations:
info = re.sub('s','',information[2])
info = re.sub(' ','',info)
info = re.sub('...
','',info)
infos = info.split('/')
if len(infos) == 3:
infos.append(infos[2])
infos[2] = infos[1]
infos[1] = re.sub('D','',infos[1])
if infos[1]=='':
infos[1] = infos[0][-4:-1]+infos[0][-1]
infos[0] = re.sub('d','',infos[0])
while(len(infos)>4):
del infos[1]
data = {
'电影排名' : information[0],
'电影名称' : information[1],
'导演及主演':infos[0],
'上映时间': infos[1],
'上映地点':infos[2],
'电影类型':infos[3],
'评分' : information[3],
'评价人数' : information[4],
'推荐语':information[5]
}
datas.append(data)
return datas
def save_to_file(datas):
with open('C:/Users/asus/Desktop/豆瓣电影Top250.txt','a',encoding='utf-8') as f:
f.write(json.dumps(datas,ensure_ascii=False)+'n')
if __name__ == '__main__':
urls = ['https://movie.douban.com/top250?start={}&filter='.format(i*25) for i in range(0,10)]
for url in urls:
html = get_html(url)
datas = parse_html(html)
save_to_file(datas)
for data in datas:
for key,value in zip(data.keys(),data.values()):
print(key+':'+value)
print('n')
五、总结
通过本篇实例,读者应掌握的重点为:
- 对目标网站的分析和确认目标信息
- 爬虫的流程以及将各部分封装为函数
- requests和正则表达式的使用