《从0开始学大数据》之流式计算的代表
前面介绍的大数据技术主要是处理、计算存储介质上的大规模数据,这类计算也叫大数据批处理计算。顾名思义,数据是以批为单位进行计算,比如一天的访问日志、历史上所有的订单数据等。这些数据通常通过 HDFS 存储在磁盘上,使用 MapReduce 或者 Spark 这样的批处理大数据计算框架进行计算,一般完成一次计算需要花费几分钟到几小时的时间。
此外,还有一种大数据技术,针对实时产生的大规模数据进行即时计算处理,我们比较熟悉的有摄像头采集的实时视频数据、淘宝实时产生的订单数据等。像上海这样的一线城市,公共场所的摄像头规模在数百万级,即使只有重要场所的视频数据需要即时处理,可能也会涉及几十万个摄像头,如果想实时发现视频中出现的通缉犯或者违章车辆,就需要对这些摄像头产生的数据进行实时处理。实时处理最大的不同就是这类数据跟存储在 HDFS 上的数据不同,是实时传输过来的,或者形象地说是流过来的,所以针对这类大数据的实时处理系统也叫大数据流计算系统。目前业内比较知名的大数据流计算框架有 Storm、Spark Streaming、Flink。
Storm
诞生背景
用于替代消息队列实现大数据实时处理
运行机制

有了 Storm 后,开发者无需再关注数据的流转、消息的处理和消费,只要编程开发好数据处理的逻辑 bolt 和数据源的逻辑 spout,以及它们之间的拓扑逻辑关系 toplogy,提交到 Storm 上运行就可以了。
Storm架构
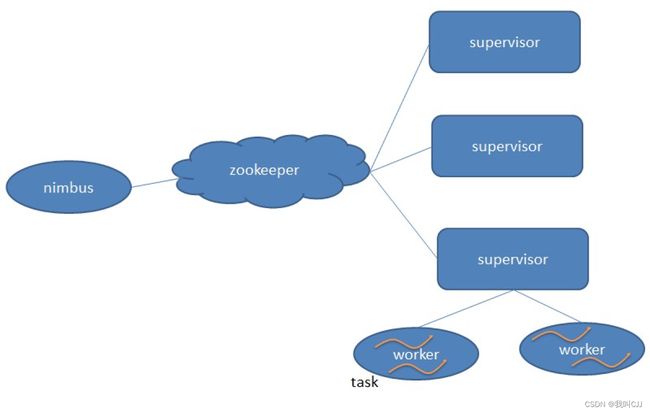
nimbus 是集群的 Master,负责集群管理、任务分配等。supervisor 是 Slave,是真正完成计算的地方,每个 supervisor 启动多个 worker 进程,每个 worker 上运行多个 task,而 task 就是 spout 或者 bolt。supervisor 和 nimbus 通过 ZooKeeper 完成任务分配、心跳检测等操作。
Hadoop、Storm 的设计理念,其实是一样的,就是把和具体业务逻辑无关的东西抽离出来,形成一个框架,比如大数据的分片处理、数据的流转、任务的部署与执行等,开发者只需要按照框架的约束,开发业务逻辑代码,提交给框架执行就可以了。
Spark Streaming
Spark Streaming 巧妙地利用了 Spark 的分片和快速计算的特性,将实时传输进来的数据按照时间进行分段,把一段时间传输进来的数据合并在一起,当作一批数据,再去交给 Spark 去处理。下图这张图描述了 Spark Streaming 将数据分段、分批的过程。

如果时间段分得足够小,每一段的数据量就会比较小,再加上 Spark 引擎的处理速度又足够快,这样看起来好像数据是被实时处理的一样,这就是 Spark Streaming 实时流计算的奥妙。
Spark Streaming 主要负责将流数据转换成小的批数据,剩下的就可以交给 Spark 去做了。
Flink
前面说 Spark Streaming 是将实时数据流按时间分段后,当作小的批处理数据去计算。那么 Flink 则相反,一开始就是按照流处理计算去设计的。当把从文件系统(HDFS)中读入的数据也当做数据流看待,他就变成批处理系统了。
为什么 Flink 既可以流处理又可以批处理呢?
如果要进行流计算,Flink 会初始化一个流执行环境 StreamExecutionEnvironment,然后利用这个执行环境构建数据流 DataStream。
如果要进行批处理计算,Flink 会初始化一个批处理执行环境 ExecutionEnvironment,然后利用这个环境构建数据集 DataSet。
然后在 DataStream 或者 DataSet 上执行各种数据转换操作(transformation),这点很像 Spark。不管是流处理还是批处理,Flink 运行时的执行引擎是相同的,只是数据源不同而已。
Flink 处理实时数据流的方式跟 Spark Streaming 也很相似,也是将流数据分段后,一小批一小批地处理。流处理算是 Flink 里的“一等公民”,Flink 对流处理的支持也更加完善,它可以对数据流执行 window 操作,将数据流切分到一个一个的 window 里,进而进行计算。
Flink架构

Flink 的架构和 Hadoop 1 或者 Yarn 看起来也很像,JobManager 是 Flink 集群的管理者,Flink 程序提交给 JobManager 后,JobManager 检查集群中所有 TaskManager 的资源利用状况,如果有空闲 TaskSlot(任务槽),就将计算任务分配给它执行。
小结
回到流计算,固然我们可以用各种分布式技术实现大规模数据的实时流处理,但是我们更希望只要针对小数据量进行业务开发,然后丢到一个大规模服务器集群上,就可以对大规模实时数据进行流计算处理。也就是业务实现和大数据流处理技术分离,业务不需要关注技术,于是各种大数据流计算技术应运而生。
其实,我们再看看互联网应用开发,也是逐渐向业务和技术分离的方向发展。比如,云计算以云服务的方式将各种分布式解决方案提供给开发者,使开发者无需关注分布式基础设施的部署和维护。目前比较热门的微服务、容器、服务编排、Serverless 等技术方案,它们则更进一步,使开发者只关注业务开发,将业务流程、资源调度和服务管理等技术方案分离开来。而物联网领域时髦的 FaaS,意思是函数即服务,就是开发者只要开发好函数,提交后就可以自动部署到整个物联网集群运行起来。
总之,流计算就是将大规模实时计算的资源管理和数据流转都统一管理起来,开发者只要开发针对小数据量的数据处理逻辑,然后部署到流计算平台上,就可以对大规模数据进行流式计算了。
思考题
流计算架构方案也逐渐对互联网在线业务开发产生影响,目前流行的微服务架构虽然将业务逻辑拆分得很细,但是服务之间的调用还是依赖接口,这依然是一种比较强的耦合关系。淘宝等互联网企业已经在尝试一种类似流计算的、异步的、基于消息的服务调用与依赖架构,据说淘宝的部分核心业务功能已经使用这种架构方案进行系统重构,并应用到今年的“双十一”大促,利用这种架构特有的回压设计对高并发系统进行自动限流与降级,取得很好的效果。
你对这种架构方案有什么想法,是否认为这样的架构方案代表了未来的互联网应用开发的方向?
来自极客时间的精选留言
大神1
数据流是久经考验的典型思路,在网络协议(如TCP)、数据平台这样场景,早就应用多年习以为常了。淘宝业务的应用架构升级可以认为是把这样思路应用到了业务系统开发中,把『流』作为业务表达上的一等概念和手段,并在业务架构/系统能力优化提升。
简单地说,因为业务面向数据流来编写,一方面业务逻辑表达可以自然接近业务流程;另一方面逻辑运行可以是全异步有很好的性能提升,一核心后端应用在双11线上,单机QPS提升30%,RT下降40%。流程的表达与异步/同步执行方式是分离的(如果了解过像RxJava,这句会容易理解:)。
另外,『流』也为业务系统的保护提供新的一些方法,在思路上其实和流计算平台是一样的,这对业务大型系统的稳定性来非常重要。
当然,业务的流式架构,在业务编写上有些FP风格(简单地说比如充分使用了Lambda),平时我们大家业务上主要是用命令式顺序平铺方式来表达,会有要个熟悉过程,虽然不见得有多难
大神2
1面向数据流的编程在java里逐渐展露头角,之前rxjava更多的是用于android,直到hystrix才算是后端一个大规模应用的案例(也和场景有关吧,后端的大多业务都是短事物处理去构建一条数据流水线反倒显得累赘),reactor是响应式编程的另一个实现,直到spring5全面拥抱以后,才完全进入人们视野(所以技术落地离不开大厂的支持),单纯的业务层处理构造一条很短的数据流意义不大(因为数据源可能还是需要返回所有数据),spring webflux结合springdata从持久层到业务层构建了自下而上的数据流(前提是持久层驱动是非阻塞的),并利用reactor-netty(支持网络背压),理想情况下将构建一个全链路的按需处理数据流
2 数据流编程,有点类似当年面向函数->面向对象,更多的是思考方式的改变,异步和数据流都是为了正确的构建数据流间的关系而存在,不过目前貌似不支持对数据流分片并行处理
该笔记摘录自极客时间课程
《从0开始学大数据》