OpenMMLab 实战营打卡 - 第 二 课
目录
(二)计算机视觉之图像分类算法基础
课程链接: 计算机视觉之图像分类算法基础
一、图像分类与基础视觉模型
1.超越规则,让机器从数据中学习
2.AlexNet的诞生&深度学习时代的开始
神经结构搜索Neural Architecture Search(2016+)
Vision Transformers (2020)
ConvNeXt(2022)
二、模型学习
1.模型学习范式
三、MMClassification
(二)计算机视觉之图像分类算法基础
课程链接: 计算机视觉之图像分类算法基础
一、图像分类与基础视觉模型
什么是图像分类?给定一张图片,识别图像中的物体。图像是像素构成的数组,对类别进行编号得到一个K类集合,图像分类问题就是构建一个可计算实现的函数且预测结果符合人类认知。图像的内容是像素整体呈现出的结果,和个别像素值没有直接关联,难以遵循具体的规则设计算法。

1.超越规则,让机器从数据中学习
收集数据-->定义模型-->训练-->预测(对于新图像,用训练好的模型预测其类别)
机器学习存在局限性,机器学习算法善于处理低维、分布相对简单的数据。图像数据在几十万维的空间中以复杂的方“缠绕”在一起,常规的机器学习算法难以处理这种复杂数据分布。

传统算法:设计图像特征(1990s~2000s)。 如下图所示,算法虽然保留了部分信息,但也丢失了许多信息。受限于人类的智慧,手工设计特征更多局限在像素层面的计算,丢失信息过多,在视觉任务上的性能达到瓶颈。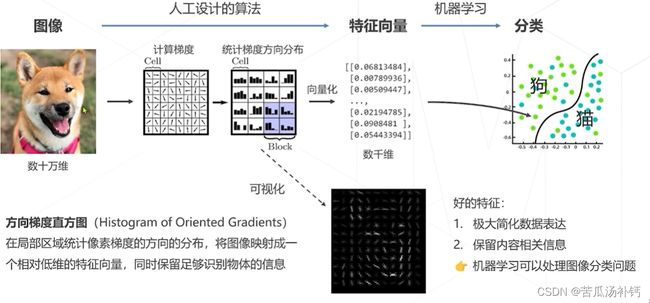
层次化特征的实现方式:不仅让算法学习去分类,还要让算法学习特征提取,一步一步形成最终分类,体现深度学习的基本思想。
卷积实现一步特征提取-->卷积神经网络。(1)特征和图像一样具有二维空间结构;(2)后层特征为空间领域内前层特征的加权求和。
多头注意力,实现一步特征提取-->Transformer
2.AlexNet的诞生&深度学习时代的开始
在2012年的竞赛中,来自多伦多大学的团队首次使用深度学习方法,一举将错误率降低至15.3%,而传统视觉算法的性能已经达到瓶颈。2015年,卷积网络的性能超越人类。

模型设计:设计适合图像的算法(1)卷积神经网络(2)轻量化卷积神经网络(3)神经结构搜索(4)Transformer
模型学习:求解一组好的参数(1)监督学习:基于数据标注学习(损失函数、随机梯度下降算法、视觉模型常用训练技巧)(2)自监督学习:基于无标注的数据学习。
(1)卷积神经网络
AlexNet(2012)第一个成功实现大规模图像的模型,在lmageNet数据集上达到~85%的 top-5准确率;5个卷积层,3个全连接层,共有60M个可学习参数;使用ReLU激活函数,大幅提高收敛速度;实现并开源了cuda-convnet,在GPU上训练大规模神经网络在工程上成为可能。

Going Deeper(2012~2014):VGG(2014)将大尺寸的卷积拆解为多层3x3的卷积,相同的感受野、更少的参数量、更多的层数和表达能力,不同层次的特征在尺寸上有简单的比例关系,方便在位置敏感的下游任务中使用,如检测、分割等;GoogleNet(Inception v1,2014)使用Inception模块堆叠形成,22个可学习层,最后的分类仅使用单层全连接层,可节省大量参数仅7M权重参数(AlexNet 60M、VGG 138M)。
精度退化问题出现,模型层数增加到一定程度后,分类正确率不增反降。卷积退化为恒等映射时,深层网络与浅层网络相同所以,深层网络应具备不差于浅层网络的分类精度。
猜想:虽然深层网络有潜力达到更高的精度,但常规的优化算法难以找到这个更优的模型即,让新增加的卷积层拟合一个近似恒等映射,恰好可以让浅层网络变好一点。

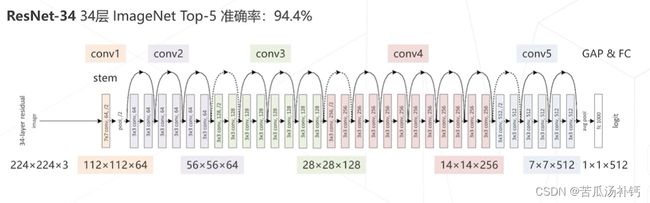
残差网络ResNet(2015),以VGG为基础,保持多级结构、增加层数,增加跨层连接。深度残差网络 ResNet 家族在各种特征提取应用广泛。ResNet 致力于处理有深层神经网络由于网络层的叠加导致性能降低的问题,是视觉领域影响力最大、使用最广泛的模型结构,获得CVPR 2016最佳论文奖。
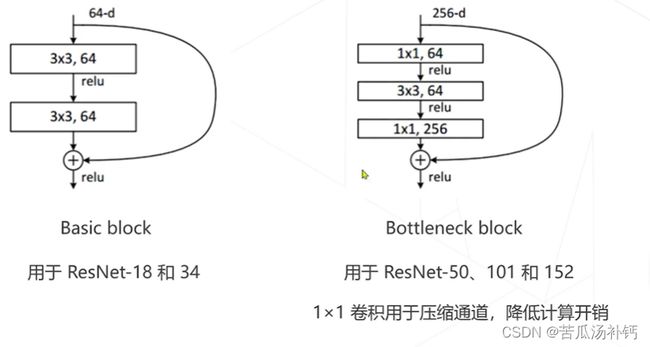
由于层数增加带来了计算问题,所以ResNet将basic block即残差模块更换为Bottleneck block。
(2)更强的图像分类模型
神经结构搜索Neural Architecture Search(2016+)
基本思路:借助强化学习等方法搜索表现最佳的网络。
代表工作:NASNet (2017)、MnasNet (2018)、EfficientNet (2019)、RegNet (2020)等。

Vision Transformers (2020)
使用Transformer替代卷积网络实现图像分类,使用更大的数据集训练,达到超越卷积网络的精度。
代表工作:Vision Transformer (2020),Swin-Transformer(2021 ICCV最佳论文)。

ConvNeXt(2022)
将Swin Transformer的模型元素迁移到卷积网络中,性能反超Transformer。

图像分类&视觉基础模型的发展如下图所示。

后续课程内容为降低模型参数、计算量的方法以及各种模型设计、轻量化设计等等。
二、模型学习
1.模型学习范式
目标:确定模型的具体形式后,找寻最有参数,使得模型给出准确的分类结果。

监督学习存在的问题:互联网数据是海量的,但数据标注是昂贵的。所以开始采用无需标注的自监督学习。
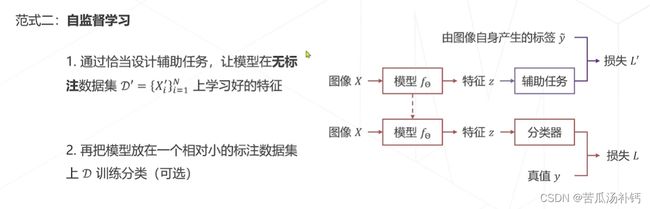
自监督学习常见的类型:基于代理任务、基于对比学习、基于掩码学习。
Relative Location(ICCV 2015),基本假设:模型只有很好地理解到图片内容,才能够预测图像块之间的关系。Masked autoencoders (MAE, CVPR 2022)基本假设:模型只有理解图片内容、掌握图片的上下文信息,才能恢复出图片中被随机遮挡的内容。
三、MMClassification
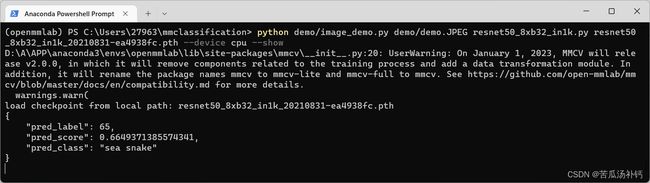
安装及环境配置
根据官方教程,所得测试结果如下: