【个人记录】学习numpy版CNN框架
前言
现成的框架会用,基础的东西也看过,但是始终觉得不够深入不够透彻,恰巧在网上看到一位大佬用numpy实现了简易的CNN框架(代码链接,知乎链接),于是准备跟着学习一波,对自己以前不太懂的内容和知识查漏补缺,有一个更深的理解。
以下内容是个人对大佬代码的分析和个人的理解,部分说明图取自大佬的知乎博客。
自己实现:自己写的程序
修改:对其中一些代码根据自己理解进行了适当的修改
内容
1.Conv
2.relu
3.leaky_relu (自己实现)
4.MaxPooling
5.AvgPooling(修改)
6.FC(修改)
Conv
初始化:standard_normal生成mean=0, stdev=1的随机数组,然后用msra的方法除以相应的weights_scale
weights_scale = math.sqrt(reduce(lambda x, y: x * y, shape) / self.output_channels)
self.weights = np.random.standard_normal(
(ksize, ksize, self.input_channels, self.output_channels)) / weights_scale
self.bias = np.random.standard_normal(self.output_channels) / weights_scale
注:以下初始化在pytorch中常用
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
padding策略:valid表明输出shape变小,same表明输出shape保持不变。下面代码为创建conv输出矩阵。
if method == 'VALID':
self.eta = np.zeros((shape[0], (shape[1] - ksize + 1) // self.stride, (shape[1] - ksize + 1) // self.stride,
self.output_channels))
if method == 'SAME':
self.eta = np.zeros((shape[0], shape[1]//self.stride, shape[2]//self.stride,self.output_channels))
forward:conv内的矩阵乘法需要用im2col方法,也就是将输入矩阵拉伸之后由img成为col_img,同时将权重拉伸,并进行相乘。最终输出为out=x*w+b(x和w都经过im2col方法)。
def im2col(image, ksize, stride):
# image is a 4d tensor([batchsize, width ,height, channel])
image_col = []
for i in range(0, image.shape[1] - ksize + 1, stride):
for j in range(0, image.shape[2] - ksize + 1, stride):
col = image[:, i:i + ksize, j:j + ksize, :].reshape([-1]) #取出每一个卷积块大小区域并进行拉伸
image_col.append(col)
image_col = np.array(image_col)
return image_col
def forward(self, x):
col_weights = self.weights.reshape([-1, self.output_channels])
if self.method == 'SAME':
x = np.pad(x, (
(0, 0), (self.ksize //2, self.ksize // 2), (self.ksize // 2, self.ksize // 2), (0, 0)), 'constant', constant_values=0) #输入进行padding
self.col_image = []
conv_out = np.zeros(self.eta.shape)
for i in range(self.batchsize):
img_i = x[i][np.newaxis, :]
self.col_image_i = im2col(img_i, self.ksize, self.stride) #输入进行im2col
conv_out[i] = np.reshape(np.dot(self.col_image_i, col_weights) + self.bias, self.eta[0].shape) #out=x*w+b
self.col_image.append(self.col_image_i)
self.col_image = np.array(self.col_image)
return conv_out
gradient:计算w的梯度和本层的输出(输出的原理)
def gradient(self, eta):
self.eta = eta
col_eta = np.reshape(eta, [self.batchsize, -1, self.output_channels])
for i in range(self.batchsize):
self.w_gradient += np.dot(self.col_image[i].T, col_eta[i]).reshape(self.weights.shape) #out=x*w+b,由矩阵求导可得w的梯度为xT*上一层传入eta
self.b_gradient += np.sum(col_eta, axis=(0, 1))
# deconv of padded eta with flippd kernel to get next_eta
if self.method == 'VALID':
pad_eta = np.pad(self.eta, (
(0, 0), (self.ksize - 1, self.ksize - 1), (self.ksize - 1, self.ksize - 1), (0, 0)),
'constant', constant_values=0)
if self.method == 'SAME':
pad_eta = np.pad(self.eta, (
(0, 0), (self.ksize // 2, self.ksize // 2), (self.ksize // 2, self.ksize // 2), (0, 0)),
'constant', constant_values=0)
flip_weights = np.flipud(np.fliplr(self.weights))#对w进行上下左右的翻转
flip_weights = flip_weights.swapaxes(2, 3)
col_flip_weights = flip_weights.reshape([-1, self.input_channels])
col_pad_eta = np.array([im2col(pad_eta[i][np.newaxis, :], self.ksize, self.stride) for i in range(self.batchsize)])
next_eta = np.dot(col_pad_eta, col_flip_weights)#上一层传入的padding后的eta与翻转后的卷积核进行卷积,得到本层的输出next_eta
next_eta = np.reshape(next_eta, self.input_shape)
return next_eta
backward:对w和b进行更新
def backward(self, alpha=0.00001, weight_decay=0.0004):
# weight_decay = L2 regularization
self.weights *= (1 - weight_decay)
self.bias *= (1 - weight_decay)
self.weights -= alpha * self.w_gradient
self.bias -= alpha * self.bias
# new_w=(1-decay)(1-alpha*w_grad)*w
self.w_gradient = np.zeros(self.weights.shape)
self.b_gradient = np.zeros(self.bias.shape)
relu
relu函数很简单,大于0的部分等于自身,小于0的部分等于0。
class Relu(object):
def __init__(self, shape):
self.eta = np.zeros(shape)
self.x = np.zeros(shape)
self.output_shape = shape
def forward(self, x):
self.x = x
return np.maximum(x, 0)
def gradient(self, eta):
self.eta = eta #大于0的部分相当于out=x,所以梯度为1,小于0的部分为out=0,梯度为0
self.eta[self.x<0]=0
return self.eta
#relu不需要更新参数,所以没有backward过程
leaky_relu
leaky relu和relu的唯一区别为当x小于0时,out=alpha*x,alpha为一个超参数。
class Leaky_Relu(object):
def __init__(self, shape, alpha=0.2):
self.eta = np.zeros(shape)
self.x = np.zeros(shape)
self.output_shape = shape
self.alpha=alpha
def forward(self, x):
self.x = x
return np.where(x>=0,x,self.alpha*x)
def gradient(self, eta):
self.eta = eta
self.eta[self.x<0] *= self.alpha #相对于relu,计算梯度时,x<0部分梯度不再是0
return self.eta
#leaky relu不需要更新参数,所以没有backward过程
MaxPooling
原理如下图所示:

class MaxPooling(object):
def __init__(self, shape, ksize=2, stride=2):
self.input_shape = shape
self.ksize = ksize
self.stride = stride
self.output_channels = shape[-1]
self.index = np.zeros(shape)#构造和输入相同shape的0矩阵,用于记录每个pooling区域最大值的位置
self.output_shape = [shape[0], shape[1] // self.stride, shape[2] // self.stride, self.output_channels]
def forward(self, x):
out = np.zeros([x.shape[0], x.shape[1] // self.stride, x.shape[2] // self.stride, self.output_channels]) #maxpooling是下采样
for b in range(x.shape[0]):#batch size
for c in range(self.output_channels):#channel
for i in range(0, x.shape[1], self.stride):
for j in range(0, x.shape[2], self.stride):#height和width
out[b, i // self.stride, j // self.stride, c] = np.max(
x[b, i:i + self.ksize, j:j + self.ksize, c])#输出是将一个stride大小的pooling区域内的值全部设为区域内的最大值
index = np.argmax(x[b, i:i + self.ksize, j:j + self.ksize, c])#获取原始区域内最大值的索引,便于之后进行梯度传递
self.index[b, i+index//self.stride, j + index % self.stride, c] = 1
return out
def gradient(self, eta):
return np.repeat(np.repeat(eta, self.stride, axis=1), self.stride, axis=2) * self.index #repeat是将输入eta在height和width上(axis=1,2)进行stride倍数的扩充,例如stride=2时由1扩充为2×2。self.index相当于一个掩膜,x*index之后,只有之前最大值的位置有输出,其余位置全部变为0。
#maxpooing不需要更新参数,所以没有backward过程
AvgPooling
原理如下图所示:
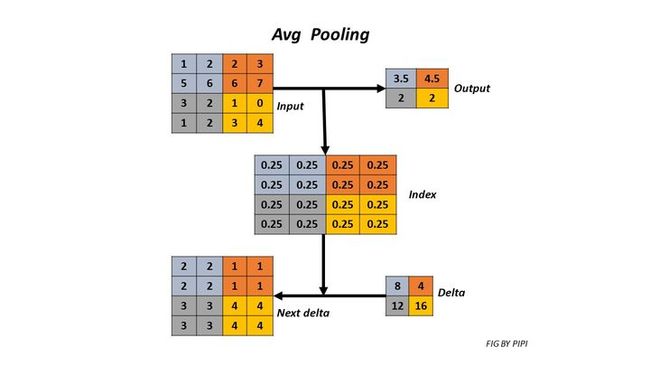
class AvgPooling(object):
def __init__(self, shape, ksize=2, stride=2):
self.input_shape = shape
self.ksize = ksize
self.stride = stride
self.output_channels = shape[-1]
self.integral = np.zeros(shape)
self.output_shape = [shape[0], shape[1] // self.stride, shape[2] // self.stride, self.output_channels]
def gradient(self, eta):
next_eta = np.repeat(eta, self.stride, axis=1)
next_eta = np.repeat(next_eta, self.stride, axis=2)#将输入eta在height和width上(axis=1,2)进行stride倍数的扩充
return next_eta/(self.ksize*self.ksize)
def forward(self, x):
out = np.zeros([x.shape[0], x.shape[1] // self.stride, x.shape[2] // self.stride, self.output_channels])
for b in range(x.shape[0]):#batch size
for c in range(self.output_channels):#channel
for i in range(0, x.shape[1], self.stride):
for j in range(0, x.shape[2], self.stride):#height和width
out[b, i // self.stride, j // self.stride, c] = np.mean(
x[b, i:i + self.ksize, j:j + self.ksize, c])
return out
FC
此处注释掉的部分为大佬的源代码,而我将其中
col_x = self.x[i][:, np.newaxis]
eta_i = eta[i][:, np.newaxis].T
self.w_gradient += np.dot(col_x, eta_i)
修改为
col_x = self.x[i][np.newaxis,:].T
eta_i = eta[i][np.newaxis,:]
self.w_gradient += np.dot(col_x, eta_i)
因为我认为输出out=x*w+b的情况下,根据矩阵求导,在梯度回传的时候应该是x.T*eta而不是x*eta.T。同时不管是我的修改还是大佬的源代码均能正常训练mnist数据集,关于这一点我也在github向大佬请教,如果有结果会更新。
class FullyConnect(object):
def __init__(self, shape, output_num=2):
self.input_shape = shape
self.batchsize = shape[0]
input_len = reduce(lambda x, y: x * y, shape[1:])#除batch size以外,将后面的维度拉平,计算FC的输入的shape。例如[batch,28,28,1]->计算28×28×1
self.weights = np.random.standard_normal((input_len, output_num))/100
self.bias = np.random.standard_normal(output_num)/100
self.output_shape = [self.batchsize, output_num]
self.w_gradient = np.zeros(self.weights.shape)
self.b_gradient = np.zeros(self.bias.shape)
def forward(self, x):
self.x = x.reshape([self.batchsize, -1])
output = np.dot(self.x, self.weights)+self.bias #out=x*w+b
return output
# def gradient(self, eta):
# for i in range(eta.shape[0]):
# col_x = self.x[i][:, np.newaxis]
# eta_i = eta[i][:, np.newaxis].T
# self.w_gradient += np.dot(col_x, eta_i)
# self.b_gradient += eta_i.reshape(self.bias.shape)
# next_eta = np.dot(eta, self.weights.T)
# next_eta = np.reshape(next_eta, self.input_shape)
# return next_eta
def gradient(self, eta):
for i in range(eta.shape[0]):
col_x = self.x[i][np.newaxis,:].T
eta_i = eta[i][np.newaxis,:]
self.w_gradient += np.dot(col_x, eta_i)
self.b_gradient += eta_i.reshape(self.bias.shape)
next_eta = np.dot(eta, self.weights.T)
next_eta = np.reshape(next_eta, self.input_shape)
return next_eta
def backward(self, alpha=0.00001, weight_decay=0.0004):
# weight_decay = L2 regularization
self.weights *= (1 - weight_decay)
self.bias *= (1 - weight_decay)
self.weights -= alpha * self.w_gradient
self.bias -= alpha * self.bias
# zero gradient
self.w_gradient = np.zeros(self.weights.shape)
self.b_gradient = np.zeros(self.bias.shape)