图像分类任务要点节点简述
目录
1.图像分类任务
2.卷积神经网络
2.1 卷积的特点:
2.2 卷积核使用的一个重要节点:
2.3 卷积架构的'救星'---'res残差'
2.4 卷积带来的参数量:
3.神经结构搜索(neural architecture search):
4.transformer
4.1 特点:
4.2 复杂度问题:
5.convnext(2022)
6.训练中实施的trick
1.图像分类任务
深度学习构建的是这个函数变换,为了合理地得到概率判断
流程的关键:将二维的像素图像 (早期)通过人工设计的算法(计算梯度、统计梯度方向分布) 转换为 特征向量。
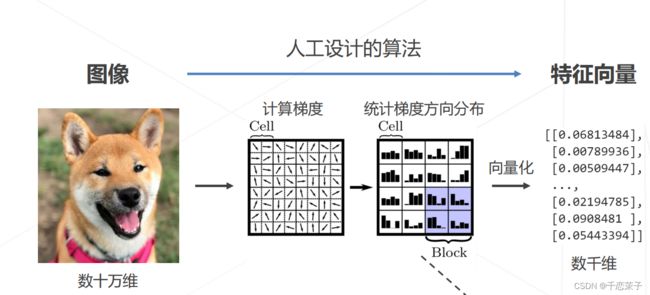 深度学习之前的图像->特征向量
深度学习之前的图像->特征向量
在这个时代中应该提取到的好的特征应该所具有的的:简化数据表达、保留内容信息。
可视化成方向梯度直方图如下,这是从提取的特征向量重塑回的像素图像,可以比较好地看出提取出了大概的狗的样子。

关键突破:深度学习时代,特征“学习” 取代 人工设计的算法;以此引申而出的是如今时代看到的提取特征骨干网络 backbone!
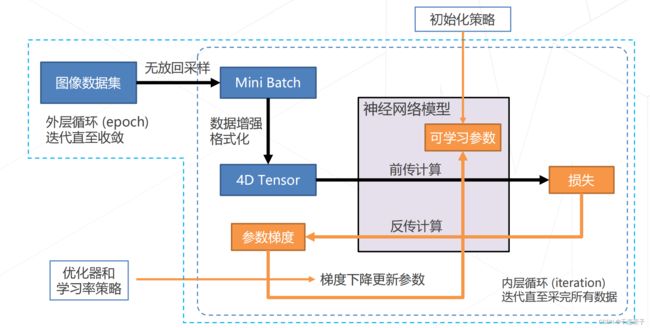
神经网络的具体操作顺序:对神经网络模型进行参数的初始化;使用图像数据集进行无放回地采样、分割成一个个batch,通过数据增强的tirck经过神经网络模型的前向通道计算损失,再由损失经由神经网络的反向计算通道获得参数梯度,参数梯度结合一定的optimizer与lr schedule 进行合理地更新权重参数合理更新可学习参数,并以新的参数开始下一轮的学习。
2.卷积神经网络
2.1 卷积的特点:
- 特征图和图像一样是二维的空间结构;
- 后一层的特征是空间邻域内前一层特征的加权求和。
2.2 卷积核使用的一个重要节点:
从alexnet的5*5 conv 到 vgg的 3*3 conv,并且之后的卷积核使用大多采用了3*3的结构;这也是一种轻量化的措施,vgg将大尺寸的卷积拆解为多层的3*3卷积(2层);获得了相同的感受野,但是具有更少的参数量与更多的层数,并且基于此带来更好的表达能力。
关于更多的轻量化措施与参数量考量见下文2.4节。
2.3 卷积架构的'救星'---'res残差'
卷积层是一个线性变换,因此可能会退化成恒等映射,而成为了恒等映射的网络架构层数将会完全失去意义并且因为一些噪声甚至会失去原本的性能。
在此基础上提出了resnet 的残差结构!残差使得下一个的卷积层将会拟合一个近似恒等映射,可以防止卷积的退化,让更深一层的提取‘更可能’学习到更多意义。
res结构为什么能生效:
- res结构“等同于多模型集成”:本质上来说,增加的残差结构是增加了隐式路径来连接输出与输出。
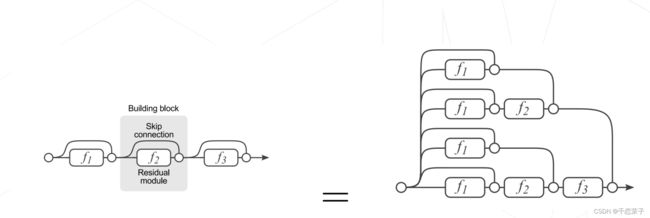
- res结构使得“LOSS surface 更加平滑”,更容易收敛。
resnet也有改进,在残差开始的时候增加conv或者pool等操作(据说pytorch里的res就是‘res B结构’。
2.4 卷积带来的参数量:
 参数的shape的补充
参数的shape的补充
卷积带来的计算量:
乘加次数计算公式:参数量 * 输出特征图的空间分辨率
轻量化:
- 找到影响上述两个公式中平方级别的参数进行缩减: K,C,C' 。
- bottleneck: 使用 1*1 的conv来压缩通道。
- 分组卷积:resnext,将3*3卷积改为分组卷积 ,更详细的描述‘可以看子豪兄b站的mobilenetv1阅读’。
- 可分离卷积:分离卷积是分组卷积的特殊情况,在分组卷积的基础上分组数=通道数。可分离卷积实现依靠 逐层卷积 + 逐点卷积 的架构。
3.神经结构搜索(neural architecture search):
通过强化学习的方法,让算法选择神经网络的结构,并按照一定规则给予激励。
4.transformer
在CV中近来依靠多头注意力代替卷积进行backbone的搭建。
4.1 特点:
注意力机制决定了这个算法不受限于感受野;
用函数权重代替可学习的权重---权重会因为输入改变;
4.2 复杂度问题:
应用于CV内,大分辨率带来的复杂度将会很高;SWIN提出了一种分层结构:将MHA的计算限制在窗口中,虽说这样的行为让transformer一定程度上又有感受野了,但是在更大层面上的注意力机制计算导致了transformer依旧拥有不错的全局视野的一面。并且swin使用shift window更快地连接特征。
5.convnext(2022)
将SWIN 的模型元素迁移到卷积网络中,竟然反超了transformer?!!是提取到了哪些对于CV最重要的东西嘛?
6.训练中实施的trick
重要性:
timm resnet trikes back; torchvision new recipe仅仅是增加了trick能将曾经的resnet50的检测结果提高数个点!
随机初始化的三种方法(使用的框架可能自动默认了一种);或者基于预训练模型的权重初始化;
学习率的设置:从头训练可以使用较大的,而微调训练可以使用较小的学习率;
学习率退火:按照步长或者比率等一定时间段来进行下降;
学习率升温:前几轮不是瞬间到达设定值;
linear scaling rule:batch size 扩大k倍, lr也该扩大k倍;“保证平均每个样本带来的梯度下降步长相同”; 例如8卡的lr,你用1卡想要复现来跑得把lr/8;
自适应梯度算法:认为不同的参数需要不同的学习率,根据梯度的历史变化幅度自动调整;
adam,adamw!!!(很有趣的东西,在书写config文件时曾经遇到过关于它的问题,值得深入看看。)
正则化和权重衰减 weight decay
早停:关注验证集的表现,防止过拟合;
权重平均EMA:以模型在优化默契会在极小值周围“转动”为假设前提,求平均来获得那个最小值;
数据增强:通过简单的变换、组合图像来产生“副本”,扩充训练数据集;
标签平滑:标注可能错误或者不准确,以此为动机让算法不能完全相信标注的数据集。
思考:小目标检测的效果看起来已经足够好了,如今遮挡检测的问题似乎更加严重一些?