NLP之LDA及情感分析实现——Matlab Text Analysis Toolbox 工具箱例程:官方文档中文解释在2020美赛C题的应用
引言:该篇文章由笔者于2022年1月15日至19日做美赛赛前训练,2020年C题的亚马逊平台评论分析中实操总结记录。
一、自然语言处理(NLP)及其matlab实现
自然语言处理(NLP,Natural Language Processing) 是研究人与计算机交互的语言问题的一门学科。按照技术实现难度的不同,这类系统可以分成简单匹配式、模糊匹配式和段落理解式三种类型。(来自百度),简单来说就是通过算法(机器学习)实现将文本转化成数学语言或者计算机语言,用可度量的方式实现聚类、评价、计算情感得分、构建网络等。
1.Data Cleaning
一些电商平台往往为了避免一些客户长时间不进行评论,会设置一道程序,如果用户超过规定的时间仍然没有做出评论,系统会自动替客户做出评论,这类数据显然没有任何分析价值。因此我们删除完全重复部分,以确保尽可能保留有用的文本评论信息,并做了如下的更多处理
Erase punctuation.
Lower all letters.
Tokenize the text.
Change word into standard noun or adjective
Remove a list of stop words.
Remove words with 2 or fewer characters, and words with 15 or more characters.
最后利用matlab的Text Analytics Toolbox进行分词处理得到如下结果。

2.LDA Topic Model
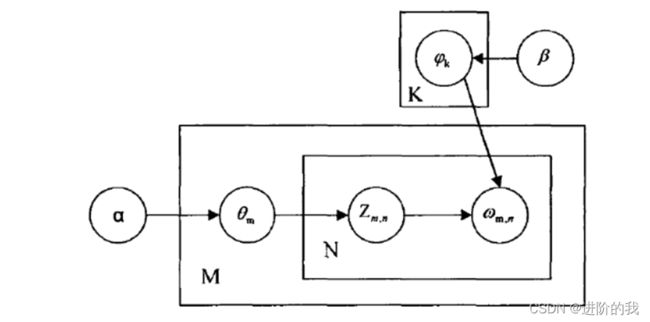
论文中我们引用LDA主题模型,它是一种无监督式学习,其主要功能是生成文档主题,也被称为三层贝叶斯模型。模型中包含评论-主题-词三层结构。评论-主题和主题-词之间的关系服从多项式概率分布。LDA主题模型结构图如图所示。
我们利用LDA主题模型来生成评论的主题,将文档中每一个词都标记属于一个固定的主题。一篇评论中包含多个主题,其分布服从参数为α的狄利克雷分布。而每个主题上的词分布服从参数为β的狄利克雷分布。
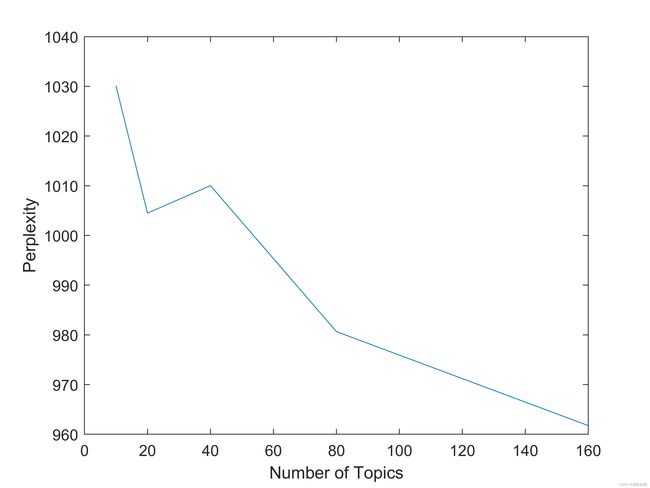
在评论网络情感分类的基础上,我们对不同情感倾向下的潜在主题分别进行挖掘,从而得到了亚马逊用户对不同方面的反应情况。首先分别计算三种产品对应的困惑度曲线,确定出LDA模型中的分类个数。从曲线中可以确定出三种产品均在分类个数n=20的时候困惑度达到极小值,此时我们认为该分类个数最为合适。
困惑度计算公式
![]()
![]()
其中,p(w)是指的测试集中出现的每一个词的概率,具体到LDA的模型中就是 p ( w ) = z,d分别指训练过的主题和测试集的各篇文档。分母的N是测试集中出现的所有词。
微波炉的Topic分类结果如下:
可以简单做一个分析:Topic1表示消费者关注微波炉的外观与材质;Topic2表示消费者关注微波炉的空间;Topic3表示消费者关注微波炉的功能性;Topic4表示消费者关注微波炉的耐用持久性。进而我们做出了不同Topic的引用率的分布图如下。

通过LDA topic model,得到了各产品对于不同主题每条评论的reference rate。我们将其汇总绘制出reference rate的分布直方图。该直方图的总面积展现了Topic在所有评论中的提及总量。而图中的虚线是reference rate的平均水平,表示了消费者对于该Topic的关心比例的平均水平。该图展示了pacifier中Topic4与Topic20在不同权重中的对比。可以看出,消费者对于这两个主题评论的总量大体相同,但对于Topic4的关心比例几乎是Topic20的两倍。我们根据该指标给出了消费者对于产品不同Topic的关注度排名,从而为亚马逊商家更好地提供商品改进策略。
| Hair_dryer |
Microwave |
Pacifier |
| functional |
power |
easy_clean |
| durability |
durability |
fit_bag |
| convenience |
size |
easy_hold |
| power |
look |
cute |
| look |
simplicity |
gift |
表 三种产品的改进方向排名
3.VADER计算文本情感得分
词嵌入(word embedding)
词嵌入就是把一段文本转换成数值形式。它将单词从原先所属的空间映射到新的多维空间中。我们利用word2vec对文本进行转换。Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,通过学习文本来用词向量的方式表征词的语义信息,使得语义上相似的单词在该空间内距离很近。神经网络构建如下图所示。

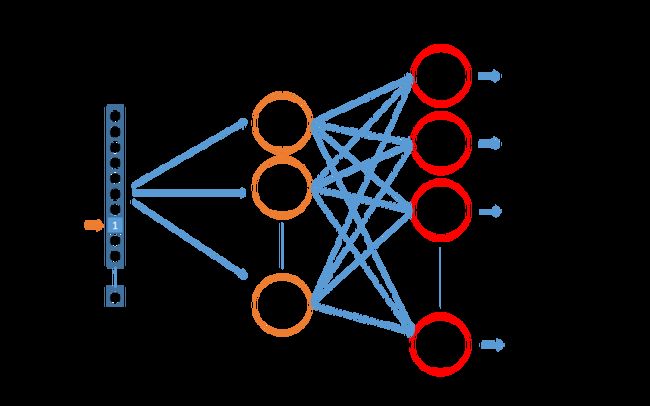
在word2vec中,我们利用Skip-Gram实现给定input word来预测上下文。首先建立模型,神经网络基于训练评论数据将输出一个概率分布,代表着我们的词典中的每个词是output word的可能性。再通过模型获取嵌入词向量,确定保留词的概率如下所示。
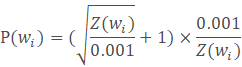
具体理论可查阅更多机器学习的内容,本文为记录应用过程(还不太懂)不予更多讨论。
在matlab工具箱中,利用了VADER算法,需要我们输入数据集的同时,首先给出情感词库种子来生成情感词库,具体论文理论可见text analysis工具箱官方文档;同时给出程度副词以及否定副词的词典,最终通过VADER算法给出每句话的情感得分。这一过程实现了将文本数据转化为一维的数字度量,以用于我们的后续建模。具体结果不予展示了,大家可以去尝试。
二、matlab官方文档例程
目前对于不同语言的NLP的实现已经有很多的集成化软件以及工具箱供初学者使用,对于中文的分析在github上也有很多开源项目,而对于美赛这样的“极速四天画图速成建模”,我们选择了可视化更好更加便捷的matlab工具箱。本人使用matlab版本是2021,内含Text Analysis Toolbox,通过matlab官方网站的例程进行了2020年美赛C题的评论文本分析。考虑到csdn上没有相关的展示和介绍,我将实现过程搬移至此。主要过程有数据采集、数据清洗、文本挖掘分析、可视化分析等。
Text Analytics ToolboxDocumentation- MathWorks 中国Text Analytics Toolbox provides algorithms and visualizations for preprocessing, analyzing, and modeling text data. https://ww2.mathworks.cn/help/textanalytics/index.html?s_tid=srchtitle_text_5
https://ww2.mathworks.cn/help/textanalytics/index.html?s_tid=srchtitle_text_5
首先我们先看一下matlab的Text Analysis工具箱的解释,工具箱提供了预处理功能、分析建模的算法以及最重要的可视化。有需要的同学希望大家能够去跟着例程一步一步调试修改,实现很容易。在官方文档的最后reference中有模型理论,论文有需求可以参考。
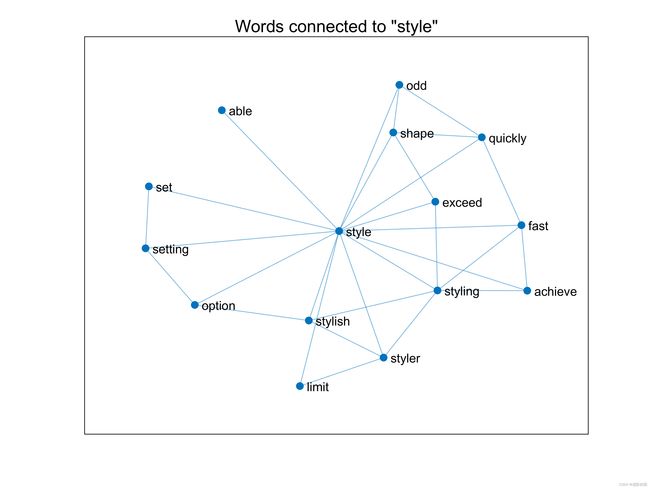
展示一下我们做题的可视化结果: