《Python机器学习基础教程》学习笔记系列-1-基本库的安装与基本使用以及初步了解区分鸢尾花种类的机器学习模型
实验环境
阿里云 + Centos7 + Python3.5.2
需要用到的库:
- NumPy #科学计算库;
- SciPy #科学计算库;
- Scikit-learn #机器学习工具,依赖于NumPy和SciPy;
- matplotlib #科学绘图库;
- pandas #处理和分析数据的库;
- mglearn #为《Python机器学习基础教程》这本书编写的实用函数库,用于快速美化绘图;
- IPython #比默认的python shell更好的交互式shell;
- Jupyter Notebook #在浏览器中运行代码的交互环境;
库的安装使用
Jupyter Notebook 的安装使用
Jupyter Notebook 是可以在浏览器中运行代码的交互环境。用Jupyter Notebook 整合代码、文本和图像非常方便。
安装Jupyter Notebook
pip install --upgrade pip #更新pip到最新版本
pip install jupyter #安装Jupyter Notebook
jupyter notebook --generate-config #生成配置文件
设置Jupyter登录密码
ipython #启动ipython
from notebook.auth import passwd
passwd() #生成密码
输入两次密码后,密码转换为哈希值,编辑jupyter配置文件
vim ~/.jupyter/jupyter_notebook_config.py
新增内容如下:
c.NotebookApp.ip='*'
c.NotebookApp.password = u'把上面的哈希值粘贴到这里'
c.NotebookApp.open_browser = False
c.NotebookApp.port =8888
启动 jupyter 服务
jupyter notebook
后台启动 jupyter 服务
nohup jupyter notebook &
远程访问
打开本地浏览器输入ip:8888,输入密码即可登录
另外在阿里云上部署的Jupyter服务,需要开启安全组的8888 TCP 端口。
参考链接
https://yq.aliyun.com/articles/441132
安装scipy、matplotlib、scikit-learn、pandas、mglearn
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scipy matplotlib scikit-learn pandas mglearn
Jupyter Notebook 初步使用
在服务器端输入“jupyter notebook &”启动 jupyter 服务,在本地浏览器输入“阿里云服务器ip:8888” 即可访问。
点击“New”→“Python3”,即可生成一个交互式的编程环境,在“IN [ ] :” 右边的方框中输入代码,点运行即可。测试代码如下(每个功能部分可分开输入并运行):
【第6-9页】
# 创建数组
import numpy as np
x = np.array([[1,2,3],[4,5,6]])
print("x:\n{}".format(x))
#创建稀疏矩阵
from scipy import sparse
eye = np.eye(4)
print("NumPy array:\n{}".format(eye))
#把NumPy数组转换为CSR格式的SciPy稀疏矩阵
sparse_matrix = sparse.csr_matrix(eye)
print("\nSciPy sparse CSR matrix:\n{}".format(sparse_matrix))
#转换为COO格式的稀疏矩阵
data = np.ones(4)
row_indices = np.arange(4)
col_indices = np.arange(4)
eye_coo = sparse.coo_matrix((data,(row_indices,col_indices)))
print("COO representation:\n{}".format(eye_coo))
#画函数图
%matplotlib inline
import matplotlib.pyplot as plt
x = np.linspace(-10,10,100)
y = np.sin(x)
plt.plot(x,y,marker="x")
#画表格
import pandas as pd
from IPython.display import display
data = {'Name':["John","Anna","Peter","Linda"],
'Location':["New York","Paris","Berlin","London"],
'Age':[24,13,53,33]
}
data_pandas = pd.DataFrame(data)
display(data_pandas)
鸢尾花实例练习
查看对象的参数属性
【第12-14页】
#查看关键字
from sklearn.datasets import load_iris
iris_dataset = load_iris()
print("iris数据集关键字:\n{}".format(iris_dataset.keys()))
print(iris_dataset['DESCR'])
print("花的种类:\n{}".format(iris_dataset['target_names']))
print("花的特征:\n{}".format(iris_dataset['feature_names']))
print("数据:\n{}".format(iris_dataset['data']))
print("数据的类型:\n{}".format(type(iris_dataset['data'])))
print("数据形状:\n{}".format(iris_dataset['data'].shape))
print("目标:\n{}".format(iris_dataset['target']))
print("目标的形状:\n{}".format(iris_dataset['target'].shape))
配置训练集
【第14-15页】
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris_dataset = load_iris()
X_train,X_test,y_train,y_test = train_test_split(
iris_dataset['data'],iris_dataset['target'],random_state=0)
print("X_train shape:{}".format(X_train.shape))
print("y_train shape:{}".format(y_train.shape))
print("X_test shape:{}".format(X_test.shape))
print("y_test shape:{}".format(y_test.shape))
生成 Iris 数据集的散点图矩阵
【第16页】
iris_dataframe = pd.DataFrame(X_train,columns=iris_dataset.feature_names)
grr = pd.plotting.scatter_matrix(iris_dataframe,c=y_train,figsize=(15,15),marker='o',
hist_kwds={'bins':20},s=60,alpha=0.8,cmap=mglearn.cm3)
注意:此处代码和书上的有个小区别,书上源代码是“grr = pd.scatter_matrix”,运行报错,查资料得知现在的调用格式为“grr = pd.plotting.scatter_matrix”。
另外,用pip安装的mglearn在运行“import mglearn”语句时报错,不能成功运行。先把服务器上已经安装的mglearn库卸载掉,在 “https://github.com/amueller/introduction_to_ml_with_python” 下有个mglearn文件夹,把这个文件夹下载到服务器的“~/.virtualenvs/Machine_learning/lib/python3.5/site-packages”目录下,此时在运行“import mglearn”时还会有告警:
DeprecationWarning: The module is deprecated in version 0.21 and will be removed in version 0.23 since we've dropped support for Python 2.7. Please rely on the official version of six (https://pypi.org/project/six/).
"(https://pypi.org/project/six/).", DeprecationWarning)
不过不影响代码正常运行。生成 Iris 数据集的散点图矩阵如下:
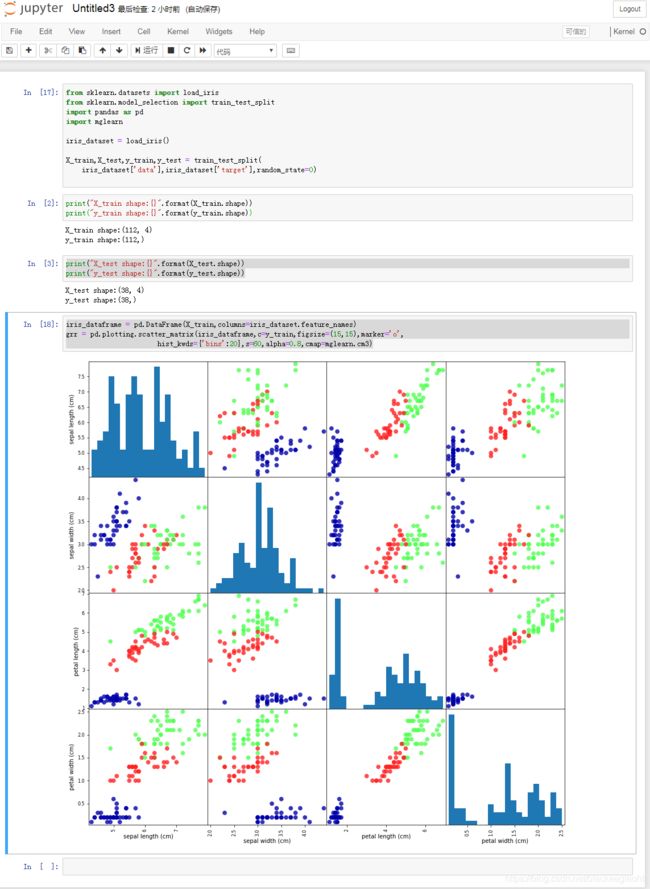
各参数说明:
- c:散点的颜色,属性值有’r '/‘g’/‘y’/‘w’/'k’等;
- figsize:图片的大小,(宽,高);
- marker:散点的形状,属性值有’.’(点)/‘o’(圆)/‘v’(倒三角形)/’*’(星星)/‘s’(正方形);
- hist_kwds{}:直方图中柱子的数量;
- s:散点的大小;
- alpha:颜色透明度,数值在0-1之间的实数;
- cmap:colormap,颜色版:‘accent’,‘blues’,‘bugn’,'oranges等;
另外本例中未涉及到的参数:
- linewidths:线的宽度;
- linestyle: 线的风格,’–’(虚线)/ ‘-’ (直线) / ‘-.’(间隔虚线)/ ': '(全为点)等;
散点图参数参考链接:python画散点图以及矩阵散点图plt.scatter()和pd.scatter_matrix()详解
散点图分析
注意:以下这段文字是通过查资料后得到的理解,有可能有误。
这个图总共有16个方格,横坐标从左到右依次是“sepal length”、“sepal width”、“petal length”、“petal width”,即花萼长度、花萼宽度、花瓣长度、花瓣宽度,单位都是厘米。纵坐标从上到下依次是“sepal length”、“sepal width”、“petal length”、“petal width”,即花萼长度、花萼宽度、花瓣长度、花瓣宽度,单位都是厘米。这四个参数的刻度都不一样,例如花萼长度的刻度有“5”、“6”、“7”,花萼宽度的刻度有“2.0”、“2.5”、“3.0”、“3.5”、“4.0”。
(此段可能有误)先看对角线上的四个直方图。以左上角第一个直方图为例,总共有20个柱子,高低参差不齐,表示横坐标所在刻度值出现的频率大小,例如最高的柱子横坐标大概是在6.5cm,表示6.5cm的花萼长度出现的概率最高(此时纵坐标的刻度不表示概率)。
对角线以外的12个图是散点图,表示花萼长度、花萼宽度、花瓣长度、花瓣宽度这四个参数两两之间的关系图。每个图中有红、绿、蓝三种圆点,一个圆点表示一个样本,三种颜色指的是三个鸢尾花的种类,即“setosa”、“versicolor”、“virginica”。以第一行第三列的图为例,蓝色圆点代表的这种花的花瓣长度集中在1cm左右,花萼长度在4cm~5.5cm之间;红色圆点代表的这种花的花萼长度与花瓣长度成正相关的线性关系,绿色圆点代表的花的花萼长度与花瓣长度也是正相关的线性关系,但是绿色的花萼长度与花瓣长度的比值要比红色的稍小一些。其他的图也有能看出线性关系的,也有看起来比较散乱的,但是都能看出来红、绿、蓝这三种圆点的分布区域分隔得比较明显,说明用花萼长度、花萼宽度、花瓣长度、花瓣宽度这4个参数基本可以分辨花的种类,也就是说根据这4个参数设计的机器学习模型应该能学会区分这三种花。