PyTorch框架:(6)图像识别实战常用模块解读
1、TorchVision
官网:torchvision — Torchvision 0.10.0 documentation
在torchvision这个模块当中,包含了很多后续需要的功能:
需要自己安装这个模块pip install torchvision。安装完之后我们就可以使用这里边的三大核心模块了。
(1)torchvision.datasets里边不止封装了我们常用的数据集,可以下载和使用的;并且还定义了一些方法,比如数据该如何存放,然后让我们分类模型构建的更方便一些。
(2)models模块里边包含了很多经典网络架构的实现,还可以拿到他们预训练的模型(训练好的权重和偏置),要这些权重和偏置的作用(在我们训练网络模型的时候我们得对权重和偏置自己初始化,接下来去训练,不断的调解w和b,但是可能会存在一个问题,我们自己训练的模型可能收敛的比较慢,收敛程度可能也不是很好,人家训练的模型有一个好处,人家训练的模型任务可能跟我们差不多,他们训练好的卷积层和池化层跟我们现在要用的卷积和全连接带参数的这些也是类似的,那么用他们的权重参数帮我们初始化会使得训练更容易一些,之后会给大家演示如何做迁移学习(拿人家的权重当做我们的初始化)这件事)
(3)torchvision.transforms模块:当我们读进来数据比如一个图像数据,我们可以对这个图像数据做一个预处理,比如说一些resize操作,去均值,标准化,然后再做一些data Augmentation数据增强(样本数据能够变换的更多一些)操作,这些在transforms中都有,人家都帮我们实现好了,所以图像预处理操作,transforms里边都有,我们直接用就好了。
2、分类任务数据集定义预配置


2.1、数据文件夹的定义:

3、花朵分类任务 实战
3.1、导入模块

3.2、数据读取与预处理
3.2.1、数据读取

3.2.2、数据预处理

数据增强:
比如说我现在有了一张猫的图像,但是我就一张图像,我能不能让这张图像更多一些呢?所以可以直接把这张图像做一个翻转,就是另外的一个图像,就把一张图像变成两张图像,这只是其中一种方法(所以其中一个功能就是我们原始的输入数据可能没有那么多,那我得想办法让数据量更多起来);还可以对猫做旋转,他还是一个猫,只不过是图像里边的像素点全变了,这个图像矩阵全变了,这就是我们得到了新的数据,这是旋转也是比较常见的;对猫进行放大和缩小,可能爪子没了只剩下脸了,但是还是一个猫,我就得到了另外的一个图像了;也可以旋转翻转缩放组合起来使用。只要我们对数据做了一个图像当中的变化,就可以得到另外的一些数据;数据增强要做的其中一件事就是这个,扩大数据量。一张图像只利用了一次太浪费了,可以变换一下多利用几次。

PS:torchvision模块里边给我们提供了data Augmentation里边常用的一些方法,这个模块里边提供好了,这样就不用再使用opencv去做了,torchvision里边几行代码就搞定了。
数据增强在代码中的实现:
第一步:指定一个data_transforms,data_transforms是这样的我先按照流水线的模式去写一写,一旦图像来了之后,他的一个变化换都先经过哪个变换,然后再经过哪个变换,再经过哪个变换,按照顺序去写;
对数据做一个角度的旋转:transforms.RandomRotation(45)这里的45并不是说只旋转45度,而是在+45或者-45之间随机的选择一个角度进行旋转。(我们要做数据增强,一般都会强调随机)
裁剪:我们拿到的数据可能有的大有的小规格不一,先需要做一个resize操作,一般先将图像resize成256x256的,然后再裁剪;这里CenterCop(224)以中心进行裁剪,就留下一个224x224的区域;也可以进行随机裁剪,这样随机裁剪的话224x224的区域就会很多了。
反转:水平翻转、竖直反转;RandomHorizontalFilp和RandomVerticalFilp,做一个镜面变换,原来猫在左边,变到右边的过程;传进来p是概率表示一张图像当去执行我们这样的流水线的时候,执行翻转到这一步的时候,他会选择随机的概率,他有50%的概率会去执行这个翻转,50%他是不动的;
图像中的基本变换:亮度、对比度、饱和度、可以传进来一些参数来做变换;ColorJitter();
灰度图:此处的概率比较小,只有2.5%的可能性,把我当前的图像再转化成灰度图(如果说原来他就是彩色图的时候,转灰度图保留的也是3通道,只不过说R=G=B都是一样的)。
transforms.ToTensor做完变换之后把数据转化成tensor的格式。
做标准化操作,一会会拿别人训练好的模型去做,比如使用VGG或者Resnet都可以,人家在训练的时候,比如说在Imagenet上训练,人家减了个均值除以人家的标准差,做了个标准化操作,为了做迁移学习效果更好,把我们的数据跟人家的越类似越好,人家怎么做的我们就怎么做,他们做了个标准化处理,我们也做一个但是这里我们减的均值和标准差都是人家计算好的(也得拿人家的去做),不能使用自己的。
----------------上述是在训练集上去做。
验证集不需要做数据增强,验证集就是我现在训练好一个模型之后,我看一下模型效果好不好,把验证效果往里边一丢看一下效果就好了。
多了一个resize操作,防止拿的数据非常大,先resize一下,再裁剪成224大小,再转成tensor的格式,然后再转化成标准化操作。
PS:在我们做数据的时候,你训练集是怎么做预处理的,你测试集也得怎么做预处理。
3.3、构建训练的数据集

第一步: 指定batch_size。
第二步:把数据结构读进来。使用的是datasets里边的ImageFolder模块。(文件夹中数据已经放好了,只用告诉我他当前的一个路径就好了)
打印查看构建的数据:
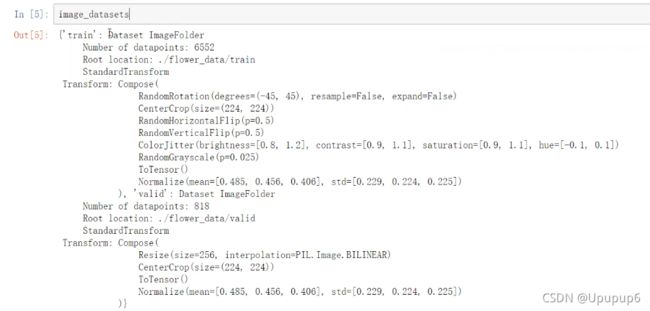

----------------------------------至此把数据全部的构建好了--------------
在数据中还提供了一个json文件:表示的是每一个花它对应的标签,因为之后在预测的时候我们需要得到的是一个类别值,其实正常情况下先得到他类别的概率值,然后在概率值当中选择最大的一个,找到当前的概率值对应的是哪个类别,但是我们得到的是类别的编号,比如说23,这里编号对应的是他实际类别的名字,

展示数据:
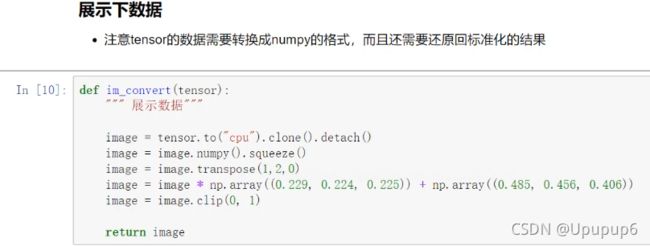
在我们构建好的数据当中,可以把数据读进来看一看这个数据实际长什么样子,PS:现在我们做好的tensor做好的数据当中,他都是已经预处理完的数据了,如果说你需要把这个数据拿出来做展示的话,你需要把这些处理过的数据还原回去,还原步骤:
- 正常情况下我们的数据是
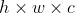 的,但是在torch当中它的颜色通道是不太一样的,他是把颜色通道放到了第一个,所以需要执行一个image.transpose操作把这个还原回去。
的,但是在torch当中它的颜色通道是不太一样的,他是把颜色通道放到了第一个,所以需要执行一个image.transpose操作把这个还原回去。 - 把做的标准化还原回去,先乘再加。

只要是迭代一次那就是取了一个batch数据,把这个batch数据拿到手,把数据展示一下,标签显示在他的上边就可以了。
3.4、加载训练好的网络模型


在model中加载人家已经提供的模型,比如说VGG,并且还要用人家已经训练好的权重来当作我们初始化的参数;
把网络加载进来,这里使用的是resnet152层网络来做的。现在model当中,把这个模型给加载进来,再打印这个模型,看一下一步步人家这个模型是怎么去做的。


看一下最后一个全连接层是2048x1000人家的网络是1000分类的,所以我们需要根据自己的任务需求将1000分类改成我们自己的分类数。拿到别人的模型后,但是别人的模型跟我们的任务可能不太一样,我们需要改一改。
3.5、初始化模型(参考pytorch官网例子)

参数:模型的名字model_name, 类别个数num_classes;
第一步:加载进来模型,此处添加了一个参数就是pretrained=use_pretrained意思就是要不要把人家的模型也下载下来,模型的网络架构就是代码,在代码当中给他生成就好了;如果要下载别人的预训练模型必须要有一个下载的操作,如果把pretrained指定为true值,他会自动的帮大家进行下载。
第二步:有选择性的冻住一些层(把这些层指定为false就是不做训练,不做更新,即在迁移学习中指定哪些层进行训练)
第三步:重新的做全连接层,model_ft.fc();
如何去构建一个网络:第一步把网络模型拿过来,并且指定pretrained model等于true,相当于用别人训练好的我们去做;第二步:我们指定要不要把某些层给他冻住,在上边可以指定,在进行梯度更新时给他指定为False,(即param.requires_grad=False)相当于给他冻住。第三步:需要把最后的全连接层给他修改一下与自己任务一致。
3.6、设置哪些层需要训练
我们上边写了一个函数def initalize_model(),但是还没有去做,把这个函数实际执行一下,
参数:model_name选择模型resnet传进行;实际的分类结果102;选择要不要去冻住某些层feature_extract;是否使用别人的pretrained model即use_pretrained=True;

3.7、优化器设置

学习率一开始指定为lr并没有特别小,因为下边有一个学习率衰减的策略,让他随着我们的学习慢慢的变小。利用衰减函数optim.lr_scheduler.StepLR()在optim中有一个lr_scheduler学习率衰减的策略StepLR,可以随着你迭代的step进行一个衰减的,参数是把你的优化器传进去,然后告诉我一个step_size,迭代多少个epoch之后,学习率衰减多少;gamma就是你衰减的比率;
3.8、训练模块

参数:model是模型;定义的一个batch,一个batch取数据dateloaders;损失函数criterion;优化器optimizer;训练多少个epoch,num_epoch;后边参数可以不用去管,表示要不要去用一些其他的网络,is_inception;
best_acc表示保存一个最好的准确率,因为在迭代过程当中我要保存模型,我可能不是所有模型都进行保存的,我可能是每一个epoch都要做一个验证,哪个epoch验证集效果要好,我把当前这个模型保存下来比较合适,不是保存最后一个而是保存哪个最好。
best_model表示:在学习的过程当中我们要把他学习的结果给他拿到手,在迭代的过程中要进行一个实时的更新,model当中他当前的这个模型或者说权重参数每次更新她都会变,我希望把最好的那次给拿过来保存。
最后加载一个最好的模型当作我们的训练结果;
3.9、开始训练

上述训练只改变了最后一层,前边都是保持不变的,再继续训练所有的层,训练全部的网络(parameter.requires_grad=True)

之前已经保存了一个最好的结果了,接下来再训练的时候, 把这个模型读进来在此基础上进行训练,(filename就是保存了之前训练的较好的模型)

3.10、测试

所谓测试就是走一遍网络的前向传播,传进来一张图像,再把model传进去;先把模型加载进来,

进行测试:




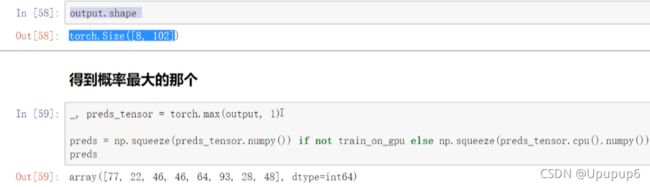


绿色的表示预测对了,红色的标识预测错了;