图文匹配 + 图像分类 = 统一多模态对比学习框架
每天给你送来NLP技术干货!
来自:圆圆的算法笔记
目前CV领域中包括两种典型的训练模式,第一种是传统的图像分类训练,以离散的label为目标,人工标注、收集干净、大量的训练数据,训练图像识别模型。第二种方法是最近比较火的基于对比学习的图文匹配训练方法,利用图像和其对应的文本描述,采用对比学习的方法训练模型。这两种方法各有优劣,前者可以达到非常高的图像识别精度、比较强的迁移能力,但是依赖人工标注数据;后者可以利用海量噪声可能较大的图像文本对作为训练数据,在few-shot learning、zero-shot learning上取得很好的效果,但是判别能力相比用干净label训练的方法较弱。今天给大家介绍一篇CVPR 2022微软发表的工作,融合两种数据的一个大一统对比学习框架。

论文题目:Unified Contrastive Learning in Image-Text-Label Space
下载地址:https://arxiv.org/pdf/2204.03610.pdf
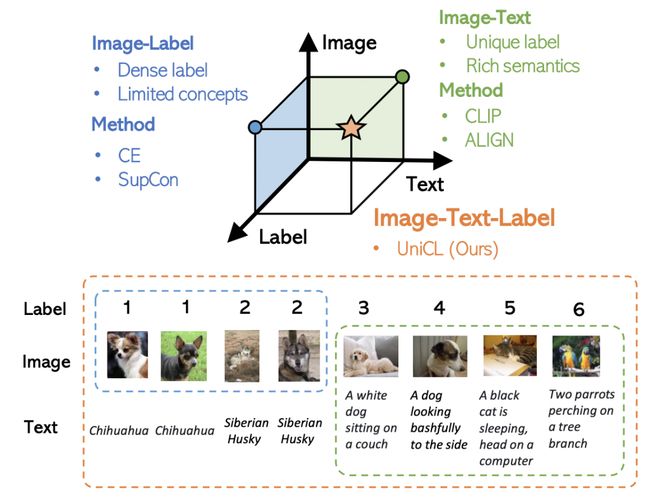
CVPR 2022微软发表的这篇工作,希望同时利用图像、文本、label三者的信息,构建一个统一的对比学习框架,同时利用两种训练模式的优势。下图反映了两种训练模式的差异,Image-Label以离散label为目标,将相同概念的图像视为一组,完全忽视文本信息;而Image-Text以图文对匹配为目标,每一对图文可以视作一个单独的label,文本侧引入丰富的语义信息。
1
两种数据的融合
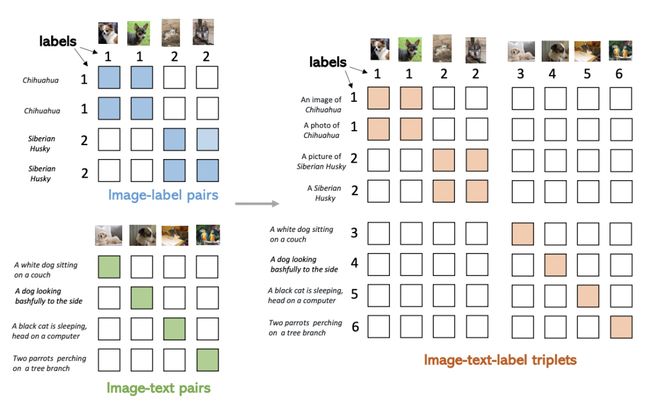
上面所说的Image-Label和Image-Text两种数据,可以表示成一个统一的形式:(图像,文本,label)三元组。其中,对于Image-Lable数据,文本是每个label对应的类别名称,label对应的每个类别的离散标签;对于Image-Text数据,文本是每个图像的文本描述,label对于每对匹配的图文对都是不同的。将两种数据融合到一起,如下图右侧所示,可以形成一个矩阵,填充部分为正样本,其他为负样本。Image-Label数据中,对应类别的图文为正样本;Image-Text中对角线为正样本。
2
损失函数
在上述矩阵的基础上,可以利用对比学习的思路构建融合Image-Label和Image-Text两种数据优化函数。对于一个batch内的所有样本,分别使用图像Encoder和文本Encoder得到图像和文本的表示,并进行归一化,然后计算图像文本之间的相似度,和CLIP类似。其中Image-to-Text损失函数可以表示为:

以样本i(文本)为中心,k表示当前batch内,和样本i的label相同的图像,j表示batch内所有其他样本。也就是说,对于每个文本,损失函数的分子是和该文本匹配的图像,分母是batch内所有图像。Text-to-Image损失函数也类似。最终BiC loss是二者之和:
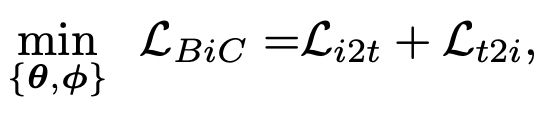
3
与其他损失函数的对比
BiC loss和交叉熵、Supervised Contrast以及CLIP三种方法的损失函数差别如下图所示,这几种损失函数之间存在着一定的联系。
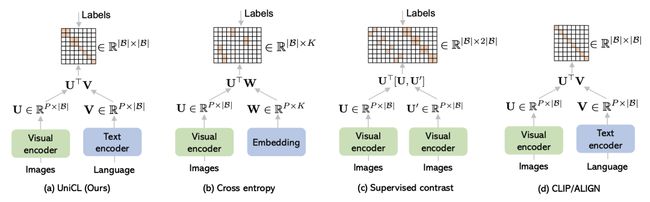
与交叉熵损失的关系:如果text encoder只是一个普通的全连接,并且batch size相比类别数量足够大,以至于一个batch内所有类别的样本都出现过,那么BiC和交叉熵等价。因此BiC相比交叉熵更具一般性,BiC让具有相似文本描述的图像表示形成类簇,不具有相似文本描述的图像被拉远。文本侧也更加灵活,能够使用任意种类的文本输入,结合更丰富的文本Encoder联合学习。
与SupCon的关系:SupCon是图像对比学习,训练数据每对pair都是图像,共用一个Encoder;而BiC针对的是跨模态对比学习,图片和文本跨模态对齐。但是两者的核心思路都是根据有label数据,将batch内出现样本更多置为正样本。
与CLIP的关系:和CLIP的主要差别在于,利用label信息将一部分非对角线上的元素视为正样本。如果这里不使用Image-Label数据,那么就和CLIP相同。
4
实验效果
图像分类效果对比:相比使用交叉熵损失和有监督对比学习,文中提出的UniCL在多个模型和数据集上取得较好的效果。尤其是在小数据集上训练时,UniCL比交叉熵训练效果提升更明显,因为引入的图文匹配方式让具有相似语义图像聚集在一起,缓解了过拟合问题。

文本Encoder和损失函数对比:文中也对比了文本Encoder是否引入的效果,如果将Transformer替换成线性层,效果有所下降,表明文本Encoder的引入能够帮助模型学习到1000多个类别之间的关系文本语义关系,有助于提升图像分类效果。同时,如果去掉i2t的loss只保留t2i的loss,会导致效果大幅下降。

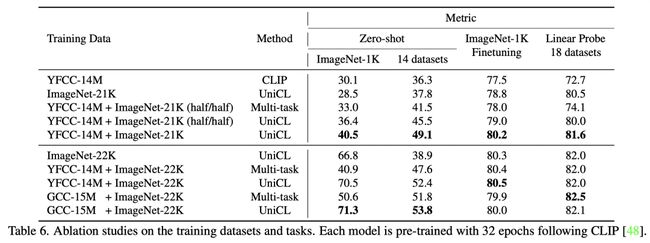
Image-Text引入对Image-Label效果提升:对于上面3行和下面3行,下面3行引入额外Image-Text数据的图像分类效果要显著优于只使用图像分类数据的效果。
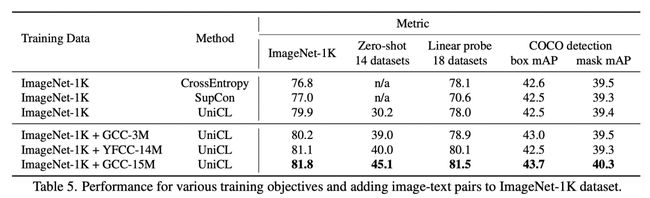
Image-Label引入对Image-Text效果提升:通过下面实验对比,引入Image-Label对Image-Text效果有一定提升作用。
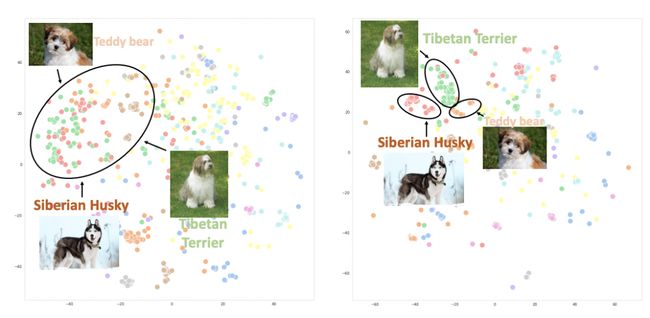
下图绘制了使用CLIP(左)和UniCL(右)两种方法训练的图像embedding的t-sne图。可以看到,使用CLIP训练的模型,不同类别的图像表示混在一起;而使用UniCL训练的模型,不同类别的图像表示能够比较好的区分。
5
总结
本文介绍了融合Image-Text和Image-Label两种数据的的多模态训练新方式,充分利用了不同的图像-文本数据,信息相互补充,相比单独使用一个数据取得非常好的效果。Label的引入也让对比学习的正负样本构造更加科学。
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型
阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果
ACL'22 | 快手+中科院提出一种数据增强方法:Text Smoothing
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!