图像分类算法ResNet论文解读
论文名称:Deep Residual Learning for Image Recognition
论文地址:https://arxiv.org/pdf/1512.03385.pdf
代码地址:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/slim/python/slim/nets/resnet_v1.py
ResNet的贡献在于,不直接训练多层卷积层网络H(x),而是训练输入x和输出之间的残差函数F(x)=H(x)−x,解决了梯度弥散问题,训练了更深的网络,模型没有更复杂,但准确率提升。
一、论文理解
1、网络退化问题
随着网络的加深,梯度弥散问题会越来越严重,导致网络很难收敛甚至无法收敛。梯度弥散问题目前有很多的解决办法,包括网络初始标准化,初始数据标准化以及中间层标准化(Batch Normalization)等。但是网络加深还会带来另外一个问题:随着网络加深,出现训练集准确率下降的现象,如下图:
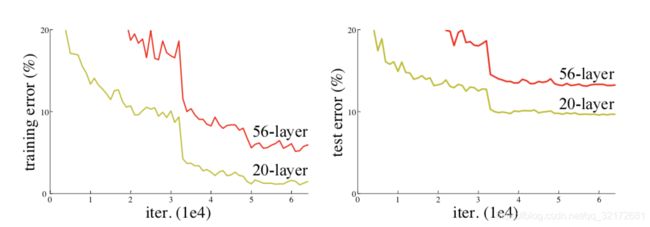
然而,由图知,这并不是由过拟合引起的。
2、ResNet训练更深层次的网络
由于梯度消失/爆炸问题阻止训练的收敛,深层次的网络往往难以训练,ResNet提出了残差学习框架以简化深层的网络训练,为输入层定义残差函数,而不是直接训练卷积神经网络。ResNet训练了深度高达152层的残差网络(比VGG网络深8倍),但仍然具有较低的复杂度,产生的结果也更精确,在2015年的ILSVRC分类任务中获得第一名。
3、残差表示
ResNet 的出发点是,在一个浅层的网络模型上进行改造,将新的模型与原来的浅层模型相比较,改造后的模型至少不应该比原来的模型表现要差,极端情况下,新加层的结果为 0,这样它就等同于原来的模型了。
假设现在有一个由2个卷积层堆叠的卷积栈,将这个栈的输入/输出之间的原始映射称为 underlying mapping,ResNet 用 residual mapping 去替换underlying mapping。将 underlying mapping 标记为 H(x) ,将经过堆叠的非线性层产生的 mapping 标记为 F(x)=H(x)−x ,最原始的映射就被强制转换成 F(x)+x,这种恒等映射学习起来更容易。
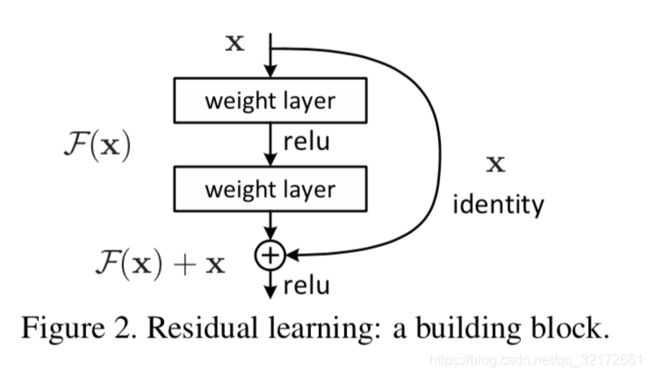
4、正向传播与反向传播
假设卷积栈的输入为x,则输出可以定义为:
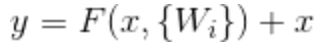
设![]() 为卷积栈的输入,
为卷积栈的输入,![]() 为卷积栈的输出,则残差网络正向传播公式为,加和是指第l层和L-1层之间的残差F(x):
为卷积栈的输出,则残差网络正向传播公式为,加和是指第l层和L-1层之间的残差F(x):
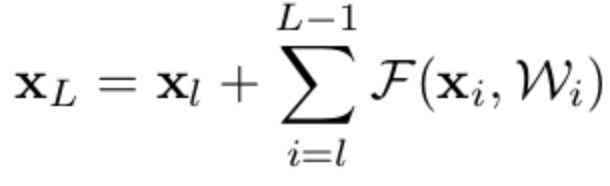
ε 代表的是 loss 方程,由链式求导法得:
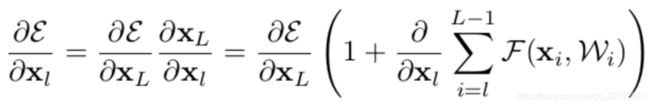
由上式知,梯度刚好是 1 加上某个值,只要这个值为 -1,梯度就不会为 0,就不会发生梯度消失现象,网络就可以继续训练下去。
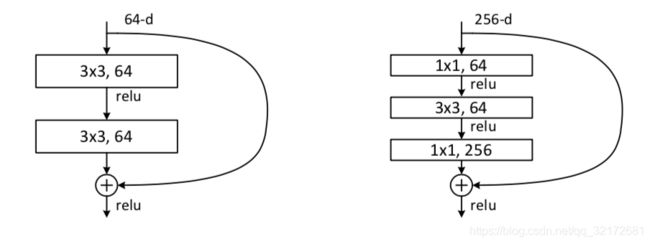
5、瓶颈结构
对于每个残差函数 f,使用3个层叠层,分别为1×1、3×3和1×1卷积,其中1×1层负责减小/增加尺寸,3×3层为瓶颈层。如右图:
6、网络结构
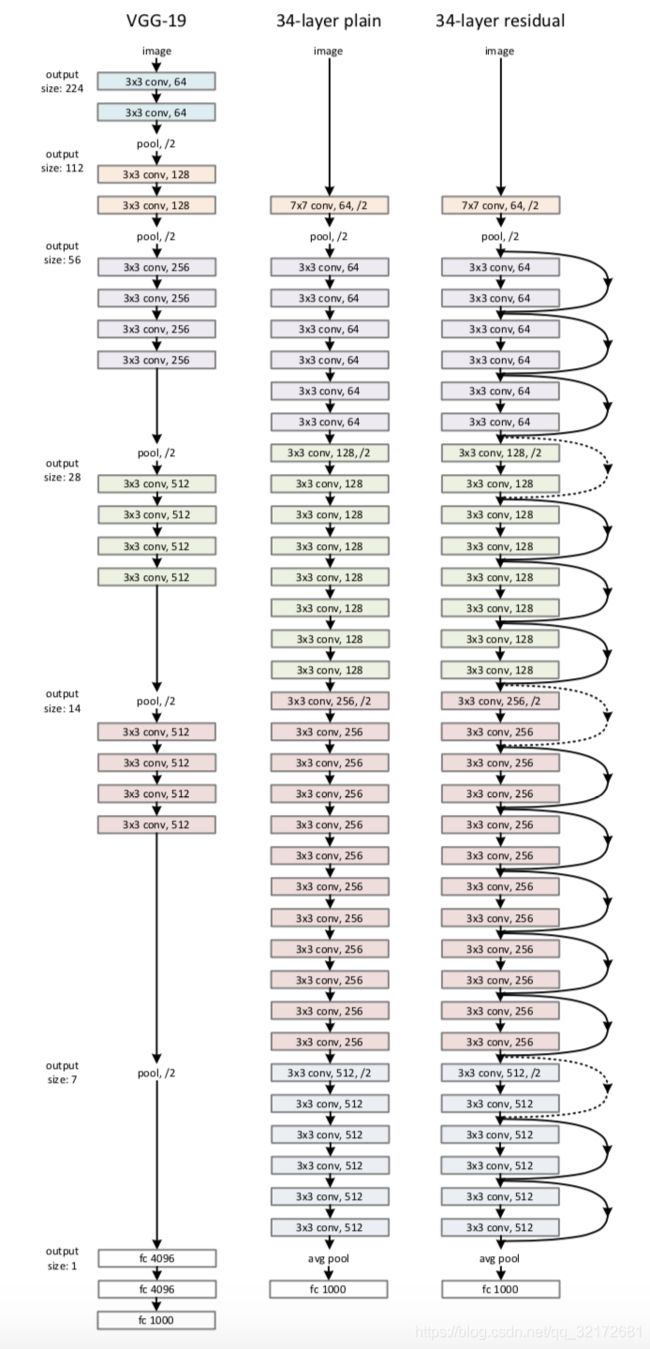
(1)普通链式网络
和vgg一样,卷积层主要由3*3滤波器组成,有2个简单的设计规则:
- 对于相同大小的输出特征图,各层具有相同的通道数
- 如果特征图大小减半,则通道数加倍,以保持每层的时间复杂度
通过步幅为2的卷积层进行降采样,网络以一个全局平均池层和一个1000路的SoftMax全连接层结束。
(2)残差网络
基于上述普通网络,插入短连接(shortcut connections),将网络转换为对应的残差版本。
- 当输入和输出尺寸相同时,可以直接使用短连接
- 当维度增加时,用1*1卷积层,改变通道数
当短连接跨越两种尺寸的特征图时,stride=2。
7、VGG、普通网络、残差网络 对比图
8、训练过程
将图像缩放,最短边调整到224,裁剪出224*224的图像,进行去均值预处理。在每次卷积之后和激活之前采用批标准化,将权重初始化,并从头开始训练所有普通/残差网络。使用最小批量大小为256的SGD,学习率从0.1开始,当误差达到最大值时除以10,模型的训练周期可达60×104次,使用0.0001的权重衰减和0.9的动量,不使用dropout。采用全卷积形式,并在多个尺度上对分数进行平均(调整图像的大小,使较短的边在224,256,384,480,640中)。
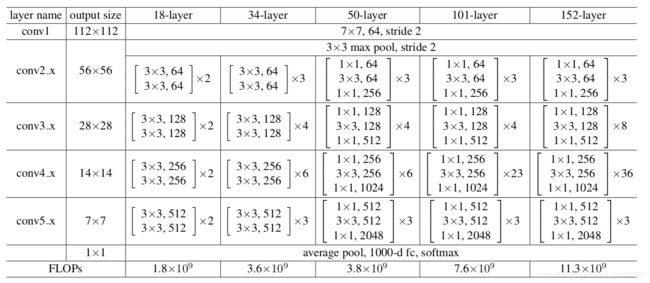
9、论文中提出5种残差网络
二、代码理解
1、resnet代码已被封装到slim中,被用于分类/分割,用法如下:

2、bottleneck结构
def bottleneck(inputs,
depth,
depth_bottleneck,
stride,
rate=1,
outputs_collections=None,
scope=None):
"""Bottleneck residual unit variant with BN after convolutions.
This is the original residual unit proposed in [1]. See Fig. 1(a) of [2] for
its definition. Note that we use here the bottleneck variant which has an
extra bottleneck layer.
When putting together two consecutive ResNet blocks that use this unit, one
should use stride = 2 in the last unit of the first block.
Args:
inputs: A tensor of size [batch, height, width, channels].
depth: The depth of the ResNet unit output.
depth_bottleneck: The depth of the bottleneck layers.
stride: The ResNet unit's stride. Determines the amount of downsampling of
the units output compared to its input.
rate: An integer, rate for atrous convolution.
outputs_collections: Collection to add the ResNet unit output.
scope: Optional variable_scope.
Returns:
The ResNet unit's output.
"""
with variable_scope.variable_scope(scope, 'bottleneck_v1', [inputs]) as sc:
depth_in = utils.last_dimension(inputs.get_shape(), min_rank=4)
if depth == depth_in:
shortcut = resnet_utils.subsample(inputs, stride, 'shortcut')
else:
shortcut = layers.conv2d(
inputs,
depth, [1, 1],
stride=stride,
activation_fn=None,
scope='shortcut')
residual = layers.conv2d(
inputs, depth_bottleneck, [1, 1], stride=1, scope='conv1')
residual = resnet_utils.conv2d_same(
residual, depth_bottleneck, 3, stride, rate=rate, scope='conv2')
residual = layers.conv2d(
residual, depth, [1, 1], stride=1, activation_fn=None, scope='conv3')
output = nn_ops.relu(shortcut + residual)
return utils.collect_named_outputs(outputs_collections, sc.name, output)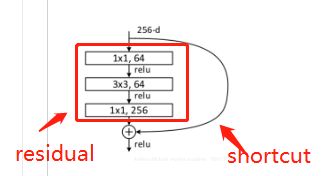
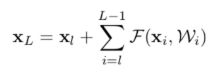
- 输入是x;
- F(x)相当于residual,它只是普通神经网络的正向传播;
- 输出是这两部分的加和H(x) = F(x)(就是residual) + x(就是shortcut,此代码shortcut部分做了一次卷积,也可以不做);
之所以可以避免梯度消失问题,是因为反向传播时,ε 代表的是 loss 方程,由链式求导法得:
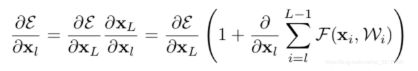
可以看出,反向传播的梯度由2项组成的:
- 对x的直接映射,梯度为1;
- 通过多层普通神经网络映射结果为:
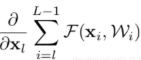 ;
;
即使新增的多层神经网络的梯度为0,那么输出结果也不会比传播前的x更差。同时也避免了梯度消失问题。
3、resnet101(resnet50、resnet152省略)
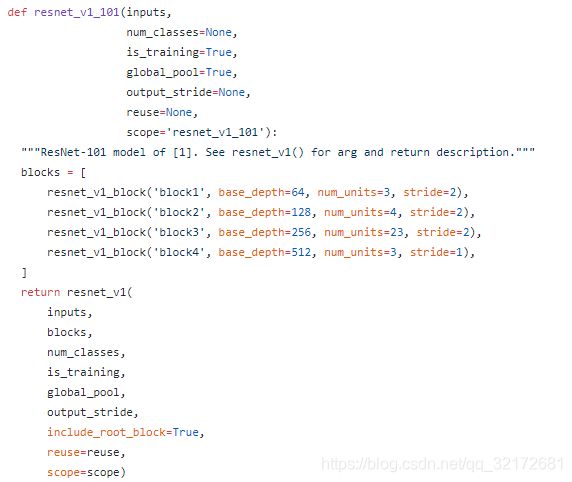
其中resnet_v1代码如下:
def resnet_v1(inputs,
blocks,
num_classes=None,
is_training=True,
global_pool=True,
output_stride=None,
include_root_block=True,
reuse=None,
scope=None):
"""Generator for v1 ResNet models.
This function generates a family of ResNet v1 models. See the resnet_v1_*()
methods for specific model instantiations, obtained by selecting different
block instantiations that produce ResNets of various depths.
Training for image classification on Imagenet is usually done with [224, 224]
inputs, resulting in [7, 7] feature maps at the output of the last ResNet
block for the ResNets defined in [1] that have nominal stride equal to 32.
However, for dense prediction tasks we advise that one uses inputs with
spatial dimensions that are multiples of 32 plus 1, e.g., [321, 321]. In
this case the feature maps at the ResNet output will have spatial shape
[(height - 1) / output_stride + 1, (width - 1) / output_stride + 1]
and corners exactly aligned with the input image corners, which greatly
facilitates alignment of the features to the image. Using as input [225, 225]
images results in [8, 8] feature maps at the output of the last ResNet block.
For dense prediction tasks, the ResNet needs to run in fully-convolutional
(FCN) mode and global_pool needs to be set to False. The ResNets in [1, 2] all
have nominal stride equal to 32 and a good choice in FCN mode is to use
output_stride=16 in order to increase the density of the computed features at
small computational and memory overhead, cf. http://arxiv.org/abs/1606.00915.
Args:
inputs: A tensor of size [batch, height_in, width_in, channels].
blocks: A list of length equal to the number of ResNet blocks. Each element
is a resnet_utils.Block object describing the units in the block.
num_classes: Number of predicted classes for classification tasks. If None
we return the features before the logit layer.
is_training: whether batch_norm layers are in training mode.
global_pool: If True, we perform global average pooling before computing the
logits. Set to True for image classification, False for dense prediction.
output_stride: If None, then the output will be computed at the nominal
network stride. If output_stride is not None, it specifies the requested
ratio of input to output spatial resolution.
include_root_block: If True, include the initial convolution followed by
max-pooling, if False excludes it.
reuse: whether or not the network and its variables should be reused. To be
able to reuse 'scope' must be given.
scope: Optional variable_scope.
Returns:
net: A rank-4 tensor of size [batch, height_out, width_out, channels_out].
If global_pool is False, then height_out and width_out are reduced by a
factor of output_stride compared to the respective height_in and width_in,
else both height_out and width_out equal one. If num_classes is None, then
net is the output of the last ResNet block, potentially after global
average pooling. If num_classes is not None, net contains the pre-softmax
activations.
end_points: A dictionary from components of the network to the corresponding
activation.
Raises:
ValueError: If the target output_stride is not valid.
"""
with variable_scope.variable_scope(
scope, 'resnet_v1', [inputs], reuse=reuse) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
with arg_scope(
[layers.conv2d, bottleneck, resnet_utils.stack_blocks_dense],
outputs_collections=end_points_collection):
with arg_scope([layers.batch_norm], is_training=is_training):
net = inputs
if include_root_block:
if output_stride is not None:
if output_stride % 4 != 0:
raise ValueError('The output_stride needs to be a multiple of 4.')
output_stride /= 4
net = resnet_utils.conv2d_same(net, 64, 7, stride=2, scope='conv1')
net = layers_lib.max_pool2d(net, [3, 3], stride=2, scope='pool1')
net = resnet_utils.stack_blocks_dense(net, blocks, output_stride)
if global_pool:
# Global average pooling.
net = math_ops.reduce_mean(net, [1, 2], name='pool5', keepdims=True)
if num_classes is not None:
net = layers.conv2d(
net,
num_classes, [1, 1],
activation_fn=None,
normalizer_fn=None,
scope='logits')
# Convert end_points_collection into a dictionary of end_points.
end_points = utils.convert_collection_to_dict(end_points_collection)
if num_classes is not None:
end_points['predictions'] = layers_lib.softmax(
net, scope='predictions')
return net, end_points
resnet_v1.default_image_size = 224
参考文章:
https://blog.csdn.net/briblue/article/details/83544381