【目标检测】keras-yolo3-tiny训练自己的数据集(目标:人&车辆)
相关内容:【目标检测】基于YOLOv3的海上船舶目标检测分类(Tensorflow/keras)
目录
- 一、环境配置
-
- 1.1 配置GPU环境。
- 1.2 虚拟环境与依赖
- 二、数据集制作
-
- 2.1 数据集制作
- 2.2 生成ImageSets
- 三、代码
-
- 3.1 下载源码
- 3.2 修改yolov3-tiny.cfg
- 3.3 转换权重文件
- 3.4 修改voc_annotation
- 3.5 修改yolo.py
- 3.6 修改train.py
- 四、测试
-
- 4.1 测试集检测
- 4.2 计算mAP
一、环境配置
1.1 配置GPU环境。
使用GPU环境加快训练速度。
【TensorFlow】Window10搭建GPU环境(CUDA、cuDNN)
1.2 虚拟环境与依赖
使用Anaconda创建虚拟环境,并安装相关依赖。
Anaconda Prompt 常用命令
计算机环境:Win10 + Python3.5 + cuda10.2
主要依赖:
tensorflow-gpu 1.10.0
keras-gpu 2.2.2
opencv
pillow
numpy
matplotlib
二、数据集制作
2.1 数据集制作
由于收集数据集并标准过于麻烦,所以采用现有数据集进行训练。
使用Visual Object Classes Challenge 2012 (VOC2012)中的部分类别作为项目的数据集。
共包含20类目标,总计17125张图片。
该项目包含以下三个类别:person、car、bus。
关于数据集的制作、提取:【python】数据集修改:移除和修改xml类别
2.2 生成ImageSets
制作好的数据集放在如下目录内:
jpg文件在JPEGImages中;
xml文件在Annotations中;
ImageSets文件夹内新建Main备用。
使用代码make_main_txt.py在ImgeSets/Main目录下生成train.txt, trainval.txt, val.txt, test.txt。
该代码存放的目录如下图,make_main_txt.py与ImageSets同级。
# -*- coding:utf-8 -*-
import os
import random
trainval_percent = 0.2 # test和val所占的比例,(1-trainval_percent)是训练集的比例
train_percent = 0.8 # 其中在train时使用的test所占的比例
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml) # 图片数量
list = range(num)
tv = int(num * trainval_percent) # trainval的数量
tr = int(tv * train_percent) # trainval中train的数量
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
三、代码
3.1 下载源码
源码:https://github.com/qqwweee/keras-yolo3
3.2 修改yolov3-tiny.cfg
修改以下四部分:
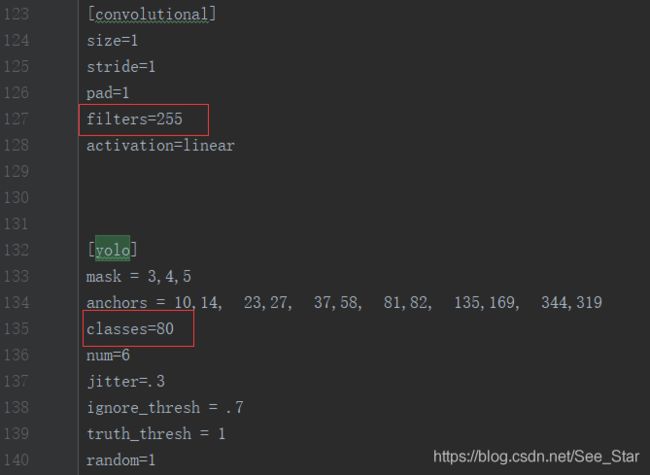
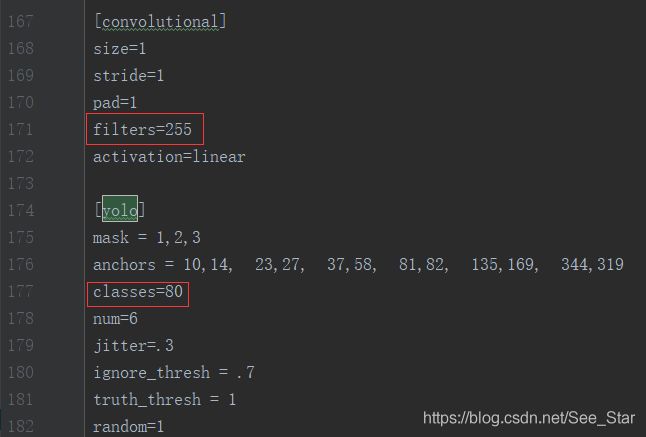
filters = 3*(类别数+5)
classes = 类别数
当类别数量为2时,filters=21,classes=2
yolov3-tiny.cfg 注释参考:https://blog.csdn.net/weixin_44152895/article/details/106570976
3.3 转换权重文件
在YOLOv3下载yolov3-tiny.weights。
使用命令python convert.py yolov3-tiny.cfg yolov3-tiny.weights model_data/tiny_yolo_weights.h5将.weigth文件转换为.h5文件。
3.4 修改voc_annotation
# -*- coding:utf-8 -*-
import xml.etree.ElementTree as ET
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["person", "vehicle"]
def convert_annotation(image_id, list_file):
print(image_id)
in_file = open('dataset/Annotations/%s.xml' % image_id,encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = getcwd()
for image_set in sets:
image_ids = open('dataset/ImageSets/Main/%s.txt' % image_set).read().strip().split()
print(image_ids)
list_file = open('dataset/%s.txt' % image_set, 'w')
for image_id in image_ids:
list_file.write('dataset/JPEGImages/%s.jpg' % image_id)
convert_annotation(image_id, list_file)
list_file.write('\n')
list_file.close()
运行代码将生产以下三个文件:

3.5 修改yolo.py
修改yolo.py的默认项设置。
class YOLO(object):
_defaults = {
"model_path": 'model_data/tiny_yolo_weights.h5',
"anchors_path": 'model_data/tiny_yolo_anchors.txt',
"classes_path": 'model_data/my_classes.txt',
"score" : 0.3,
"iou" : 0.45,
"model_image_size" : (416, 416),
"gpu_num" : 1,
}
3.6 修改train.py
17-20行的路径设置:
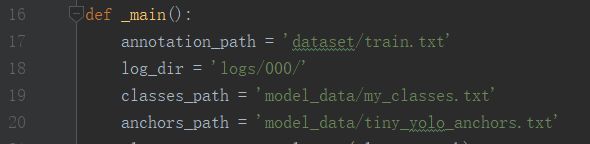
52行的if True改成if False,因为这部分的训练效果不好,使用下一部分的训练。也就是从70行开始。
修改batch_size、epochs。
显存较小就讲bathsize设置的小一点。
最后,运行main.py。
四、测试
4.1 测试集检测
创建main_yolo.py,依照yolo.py进行修改。修改目录信息即可运行。可生成result文件夹,里面包含对测试集的检测结果。
main_yolo.py
# -*- coding: utf-8 -*-
"""
Class definition of YOLO_v3 style detection model on image and video
"""
import colorsys
import os
import time
from timeit import default_timer as timer
import numpy as np
from keras import backend as K
from keras.models import load_model
from keras.layers import Input
from PIL import Image, ImageFont, ImageDraw
from yolo3.model import yolo_eval, yolo_body, tiny_yolo_body
from yolo3.utils import letterbox_image
import os
from keras.utils import multi_gpu_model
dir_project = os.getcwd() # 获取当前目录
# 创建创建一个存储检测结果的dir
result_path = './result'
if not os.path.exists(result_path):
os.makedirs(result_path)
# result如果之前存放的有文件,全部清除
for i in os.listdir(result_path):
path_file = os.path.join(result_path, i)
if os.path.isfile(path_file):
os.remove(path_file)
# 创建一个记录检测结果的文件
txt_path = result_path + '/result.txt'
file = open(txt_path, 'w')
class YOLO(object):
_defaults = {
"model_path": 'logs/000/trained_weights_final.h5',
"anchors_path": 'model_data/tiny_yolo_anchors.txt',
"classes_path": 'model_data/my_classes.txt',
"score" : 0.3,
"iou" : 0.45,
"model_image_size" : (416, 416),
"gpu_num" : 1,
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
def __init__(self, **kwargs):
self.__dict__.update(self._defaults) # set up default values
self.__dict__.update(kwargs) # and update with user overrides
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate()
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.'
# Load model, or construct model and load weights.
num_anchors = len(self.anchors)
num_classes = len(self.class_names)
is_tiny_version = num_anchors==6 # default setting
try:
self.yolo_model = load_model(model_path, compile=False)
except:
self.yolo_model = tiny_yolo_body(Input(shape=(None,None,3)), num_anchors//2, num_classes) \
if is_tiny_version else yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes)
self.yolo_model.load_weights(self.model_path) # make sure model, anchors and classes match
else:
assert self.yolo_model.layers[-1].output_shape[-1] == \
num_anchors/len(self.yolo_model.output) * (num_classes + 5), \
'Mismatch between model and given anchor and class sizes'
print('{} model, anchors, and classes loaded.'.format(model_path))
# Generate colors for drawing bounding boxes.
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
np.random.seed(10101) # Fixed seed for consistent colors across runs.
np.random.shuffle(self.colors) # Shuffle colors to decorrelate adjacent classes.
np.random.seed(None) # Reset seed to default.
# Generate output tensor targets for filtered bounding boxes.
self.input_image_shape = K.placeholder(shape=(2, ))
if self.gpu_num>=2:
self.yolo_model = multi_gpu_model(self.yolo_model, gpus=self.gpu_num)
boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors,
len(self.class_names), self.input_image_shape,
score_threshold=self.score, iou_threshold=self.iou)
return boxes, scores, classes
def detect_image(self, image):
start = timer()
if self.model_image_size != (None, None):
assert self.model_image_size[0]%32 == 0, 'Multiples of 32 required'
assert self.model_image_size[1]%32 == 0, 'Multiples of 32 required'
boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size)))
else:
new_image_size = (image.width - (image.width % 32),
image.height - (image.height % 32))
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
print(image_data.shape)
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})
print('Found {} boxes for {}'.format(len(out_boxes), 'img'))
font = ImageFont.truetype(font='font/FiraMono-Medium.otf',
size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 300
# # 保存框检测出的框的个数 (添加)
# file.write('find ' + str(len(out_boxes)) + ' target(s) \n')
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
# # 写入检测位置(添加)
# file.write(
# predicted_class + ' score: ' + str(score) + ' \nlocation: top: ' + str(top) + '、 bottom: ' + str(
# bottom) + '、 left: ' + str(left) + '、 right: ' + str(right) + '\n')
file.write(predicted_class + ' ' + str(score) + ' ' + str(left) + ' ' + str(top) + ' ' + str(right) + ' ' + str(bottom) + ';')
print(label, (left, top), (right, bottom))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
# My kingdom for a good redistributable image drawing library.
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[c])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[c])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw
end = timer()
print(end - start)
return image
def close_session(self):
self.sess.close()
def detect_video(yolo, video_path, output_path=""):
import cv2
vid = cv2.VideoCapture(video_path)
if not vid.isOpened():
raise IOError("Couldn't open webcam or video")
video_FourCC = int(vid.get(cv2.CAP_PROP_FOURCC)) # 获得视频编码MPEG4/H264
video_fps = vid.get(cv2.CAP_PROP_FPS)
video_size = (int(vid.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT)))
isOutput = True if output_path != "" else False
if isOutput:
print("!!! TYPE:", type(output_path), type(video_FourCC), type(video_fps), type(video_size))
out = cv2.VideoWriter(output_path, video_FourCC, video_fps, video_size)
accum_time = 0
curr_fps = 0
fps = "FPS: ??"
prev_time = timer()
while True:
return_value, frame = vid.read()
image = Image.fromarray(frame) # 从array转换成image
image = yolo.detect_image(image)
result = np.asarray(image)
curr_time = timer()
exec_time = curr_time - prev_time
prev_time = curr_time
accum_time = accum_time + exec_time
curr_fps = curr_fps + 1
if accum_time > 1:
accum_time = accum_time - 1
fps = "FPS: " + str(curr_fps)
curr_fps = 0
cv2.putText(result, text=fps, org=(3, 15), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.50, color=(255, 0, 0), thickness=2)
cv2.namedWindow("result", cv2.WINDOW_NORMAL)
cv2.imshow("result", result)
if isOutput:
out.write(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
yolo.close_session()
# 批量处理文件
if __name__ == '__main__':
if True:
# 读取test文件
with open("dataset/ImageSets/Main/test.txt", 'r') as f: # 打开文件
test_list = f.readlines() # 读取文件
test_list = [x.strip() for x in test_list if x.strip() != ''] # 去除/n
# print(test_list)
t1 = time.time()
yolo = YOLO()
for filename in test_list:
image_path = 'dataset/JPEGImages/'+filename+'.jpg'
portion = os.path.split(image_path)
# file.write(portion[1]+' detect_result:\n')
file.write(image_path + ' ')
image = Image.open(image_path)
image_mAP_save_path = dir_project + '/mAP/input/images-optional/'
image.save(image_mAP_save_path + filename + '.jpg')
r_image = yolo.detect_image(image)
file.write('\n')
#r_image.show() 显示检测结果
image_save_path = './result/result_'+portion[1]
print('detect result save to....:'+image_save_path)
r_image.save(image_save_path)
time_sum = time.time() - t1
# file.write('time sum: '+str(time_sum)+'s')
print('time sum:',time_sum)
file.close()
yolo.close_session()
if False:
img_path = 'dataset/JPEGImages_resize'
result_path = 'dataset/image_result'
for file in os.listdir(img_path):
file_path = os.path.join(img_path, file)
image = Image.open(file_path)
r_image = yolo.detect_image(image)
image_save_path = os.path.join(result_path, file)
print('detect result save to: ' + image_save_path)
r_image.save(image_save_path)
4.2 计算mAP
mAP计算:【目标检测】kera-yolo3模型计算mAP
mAP源码:https://github.com/Cartucho/mAP
修改mAP源码,针对keras-yolov3的检测结果计算mAP。