从零开始的数模(十三)主成分分析
目录
一、概念
1.1线代知识补充
1.3主成分的命名与解释
1.4原理
1.5应用
编辑 二、基于python的主成分分析
2.1主要步骤
2.2.部分说明
2.3代码
完整代码
完整代码2
三、基于MATLAB的主成分分析
3.1算法步骤
编辑 3.2代码
完整代码
一、概念
1.1线代知识补充

 1.2基本流程
1.2基本流程


具体
去除平均值
计算协方差矩阵
计算协方差矩阵的特征值和特征向量
将特征值排序
保留前N个最大的特征值对应的特征向量
将原始特征转换到上面得到的N个特征向量构建的新空间中(最后两步,实现了特征压缩)
第一步:对所有特征进行中心化:去均值

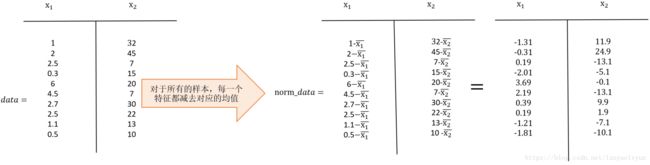 经过去均值处理之后,原始特征的值就变成了新的值,在这个新的norm_data的基础上,进行下面的操作。
经过去均值处理之后,原始特征的值就变成了新的值,在这个新的norm_data的基础上,进行下面的操作。
第二步:求协方差矩阵C
 第三步:求协方差矩阵C的特征值和相对应的特征向量
第三步:求协方差矩阵C的特征值和相对应的特征向量

第四步:将原始特征投影到选取的特征向量上,得到降维后的新K维特征

1.3主成分的命名与解释

1.4原理
主成分分析是利用降维的思想,在损失很少信息的前提下把多个指标转化为几个综合指标的多元统计方法。通常把转化生成的综合指标称之为主成分,其中每个主成分都是原始变量的线性组合,且各个主成分之间互不相关,这就使得主成分比原始变量具有某些更优越的性能。这样在研究复杂问题时就可以只考虑少数几个主成分而不至于损失太多信息,从而更容易抓住主要矛盾,揭示事物内部变量之间的规律性,同时使问题得到简化,提高分析效率。
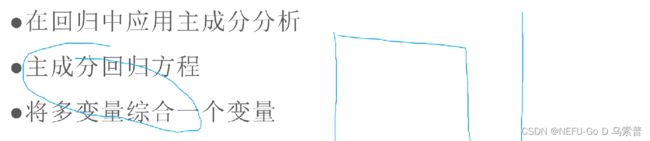
1.5应用

 二、基于python的主成分分析
二、基于python的主成分分析
2.1主要步骤
1.根据研究问题选取初始分析变量;
2.根据初始变量特性判断由协方差阵求主成分还是由相关阵求主成分(数据标准化的话需要用系数相关矩阵,数据未标准化则用协方差阵);
3.求协差阵或相关阵的特征根与相应标准特征向量;
4.判断是否存在明显的多重共线性,若存在,则回到第一步;
5.主成分分析的适合性检验
6.得到主成分的表达式并确定主成分个数,选取主成分;
7.结合主成分对研究问题进行分析并深入研究。
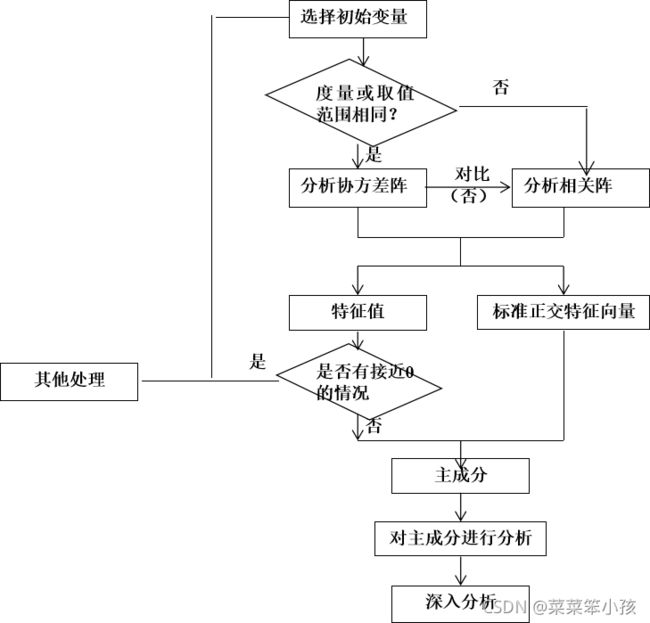
2.2.部分说明

2.3代码
1.导入库
# 数据处理
import pandas as pd
import numpy as np
# 绘图
import seaborn as sns
import matplotlib.pyplot as plt2.读取数据集
df = pd.read_csv(r"D:\桌面\aa.csv", encoding='gbk', index_col=0).reset_index(drop=True)
df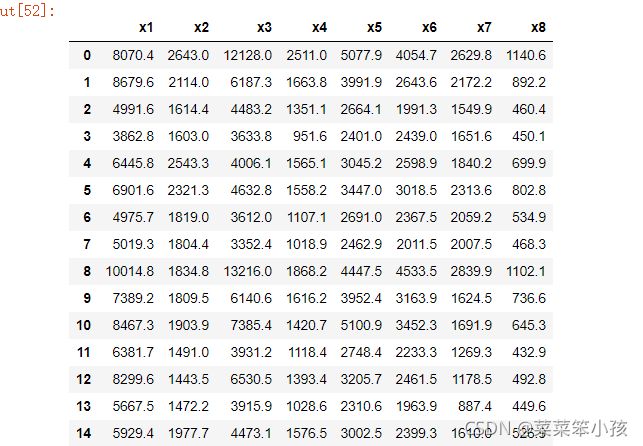
3. 进行球状检验
检验总体变量的相关矩阵是否是单位阵(相关系数矩阵对角线的所有元素均为1,所有非对角线上的元素均为零);即检验各个变量是否各自独立。
# Bartlett's球状检验
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
chi_square_value, p_value = calculate_bartlett_sphericity(df)
print(chi_square_value, p_value)
4.KMO检验
检查变量间的相关性和偏相关性,取值在0-1之间;KOM统计量越接近1,变量间的相关性越强,偏相关性越弱,因子分析的效果越好。
# KMO检验
# 检查变量间的相关性和偏相关性,取值在0-1之间;KOM统计量越接近1,变量间的相关性越强,偏相关性越弱,因子分析的效果越好。
# 通常取值从0.6开始进行因子分析
from factor_analyzer.factor_analyzer import calculate_kmo
kmo_all, kmo_model = calculate_kmo(df)
print(kmo_all)
5.求相关矩阵
(1)数据标准化做法
1.进行标准化
用到了 preprocessing 库
from sklearn import preprocessing标准化代码:
df = preprocessing.scale(df)
df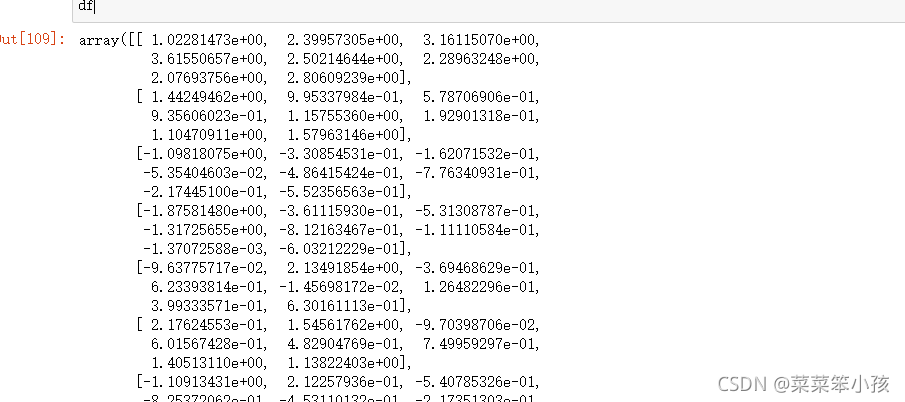
2.求相关系数矩阵
covX = np.around(np.corrcoef(df.T),decimals=3)
covX
3.求解特征值和特征向量
featValue, featVec= np.linalg.eig(covX.T) #求解系数相关矩阵的特征值和特征向量
featValue, featVec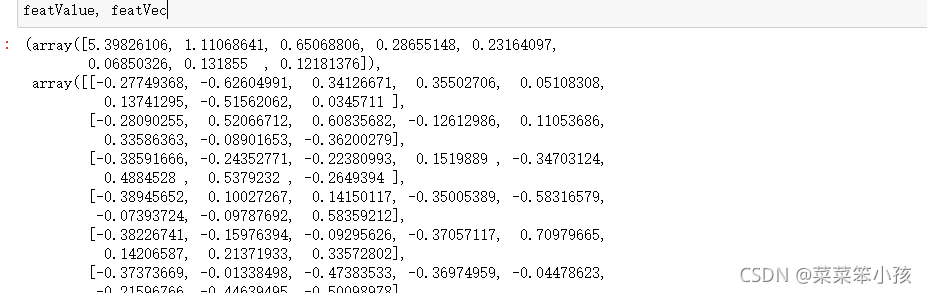
(2)数据不标准化做法
1.求均值
def meanX(dataX):
return np.mean(dataX,axis=0)#axis=0表示依照列来求均值。假设输入list,则axis=1
average = meanX(df)
average
2.查看列数和行数
m, n = np.shape(df)
m,n
3.写出同数据集一样的均值矩阵
data_adjust = []
avgs = np.tile(average, (m, 1))
avgs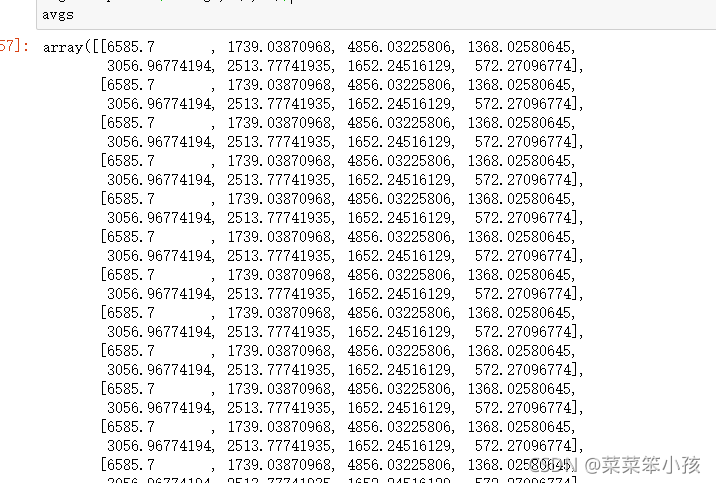 4.对数据集进行去中心化
4.对数据集进行去中心化
data_adjust = df - avgs
data_adjust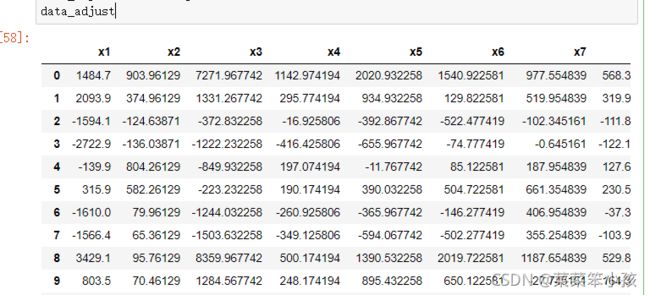
5.计算协方差阵
covX = np.cov(data_adjust.T) #计算协方差矩阵
covX
6.计算协方差阵的特征值和特征向量
featValue, featVec= np.linalg.eig(covX) #求解协方差矩阵的特征值和特征向量
featValue, featVec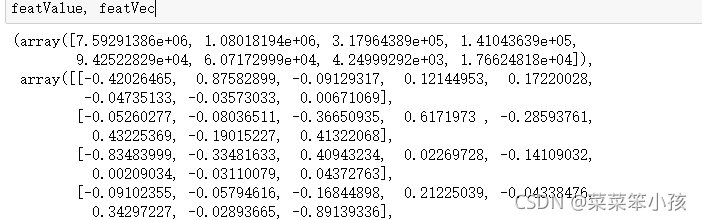
下面的做法不再区分标不标准化了,你上面用哪种都行
在这里仅拿为标准化做法的数据进行下面操作!!!
7.对特征值进行排序并输出 降序
featValue = sorted(featValue)[::-1]
featValue
8.绘制散点图和折线图
# 同样的数据绘制散点图和折线图
plt.scatter(range(1, df.shape[1] + 1), featValue)
plt.plot(range(1, df.shape[1] + 1), featValue)
# 显示图的标题和xy轴的名字
# 最好使用英文,中文可能乱码
plt.title("Scree Plot")
plt.xlabel("Factors")
plt.ylabel("Eigenvalue")
plt.grid() # 显示网格
plt.show() # 显示图形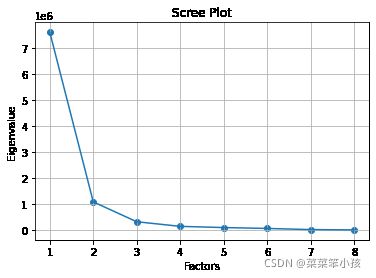
9.求特征值的贡献度
gx = featValue/np.sum(featValue)
gx
10.求特征值的累计贡献度
lg = np.cumsum(gx)
lg
11.选出主成分
#选出主成分
k=[i for i in range(len(lg)) if lg[i]<0.85]
k = list(k)
print(k)12.选出主成分对应的特征向量矩阵
selectVec = np.matrix(featVec.T[k]).T
selectVe=selectVec*(-1)
selectVec
13.求主成分得分
finalData = np.dot(data_adjust,selectVec)
finalData
14.绘制热力图
# 绘图
plt.figure(figsize = (14,14))
ax = sns.heatmap(selectVec, annot=True, cmap="BuPu")
# 设置y轴字体大小
ax.yaxis.set_tick_params(labelsize=15)
plt.title("Factor Analysis", fontsize="xx-large")
# 设置y轴标签
plt.ylabel("Sepal Width", fontsize="xx-large")
# 显示图片
plt.show()
# 保存图片
# plt.savefig("factorAnalysis", dpi=500)
完整代码
# 数据处理
import pandas as pd
import numpy as np
# 绘图
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv(r"D:\桌面\aa.csv", encoding='gbk', index_col=0).reset_index(drop=True)
print(df)
# Bartlett's球状检验
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
chi_square_value, p_value = calculate_bartlett_sphericity(df)
print(chi_square_value, p_value)
# KMO检验
# 检查变量间的相关性和偏相关性,取值在0-1之间;KOM统计量越接近1,变量间的相关性越强,偏相关性越弱,因子分析的效果越好。
# 通常取值从0.6开始进行因子分析
from factor_analyzer.factor_analyzer import calculate_kmo
kmo_all, kmo_model = calculate_kmo(df)
print(kmo_all)
# #标准化
# #所需库
# from sklearn import preprocessing
# #进行标准化
# df = preprocessing.scale(df)
# print(df)
# #求解系数相关矩阵
# covX = np.around(np.corrcoef(df.T),decimals=3)
# print(covX)
# #求解特征值和特征向量
# featValue, featVec= np.linalg.eig(covX.T) #求解系数相关矩阵的特征值和特征向量
# print(featValue, featVec)
#不标准化
#均值
def meanX(dataX):
return np.mean(dataX,axis=0)#axis=0表示依照列来求均值。假设输入list,则axis=1
average = meanX(df)
print(average)
#查看列数和行数
m, n = np.shape(df)
print(m,n)
#均值矩阵
data_adjust = []
avgs = np.tile(average, (m, 1))
print(avgs)
#去中心化
data_adjust = df - avgs
print(data_adjust)
#协方差阵
covX = np.cov(data_adjust.T) #计算协方差矩阵
print(covX)
#计算协方差阵的特征值和特征向量
featValue, featVec= np.linalg.eig(covX) #求解协方差矩阵的特征值和特征向量
print(featValue, featVec)
####下面没有区分#######
#对特征值进行排序并输出 降序
featValue = sorted(featValue)[::-1]
print(featValue)
#绘制散点图和折线图
# 同样的数据绘制散点图和折线图
plt.scatter(range(1, df.shape[1] + 1), featValue)
plt.plot(range(1, df.shape[1] + 1), featValue)
# 显示图的标题和xy轴的名字
# 最好使用英文,中文可能乱码
plt.title("Scree Plot")
plt.xlabel("Factors")
plt.ylabel("Eigenvalue")
plt.grid() # 显示网格
plt.show() # 显示图形
#求特征值的贡献度
gx = featValue/np.sum(featValue)
print(gx)
#求特征值的累计贡献度
lg = np.cumsum(gx)
print(lg)
#选出主成分
k=[i for i in range(len(lg)) if lg[i]<0.85]
k = list(k)
print(k)
#选出主成分对应的特征向量矩阵
selectVec = np.matrix(featVec.T[k]).T
selectVe=selectVec*(-1)
print(selectVec)
#主成分得分
finalData = np.dot(data_adjust,selectVec)
print(finalData)
#绘制热力图
plt.figure(figsize = (14,14))
ax = sns.heatmap(selectVec, annot=True, cmap="BuPu")
# 设置y轴字体大小
ax.yaxis.set_tick_params(labelsize=15)
plt.title("Factor Analysis", fontsize="xx-large")
# 设置y轴标签
plt.ylabel("Sepal Width", fontsize="xx-large")
# 显示图片
plt.show()
# 保存图片
# plt.savefig("factorAnalysis", dpi=500)完整代码2
import matplotlib.pyplot as plt
import sklearn.decomposition as dp
from sklearn.datasets import load_iris
x,y=load_iris(return_X_y=True) #加载数据,x表示数据集中的属性数据,y表示数据标签
pca=dp.PCA(n_components=0.99) #加载pca算法,设置降维后主成分数目为2
reduced_x=pca.fit_transform(x,y) #对原始数据进行降维,保存在reduced_x中
red_x,red_y=[],[]
blue_x,blue_y=[],[]
green_x,green_y=[],[]
for i in range(len(reduced_x)): #按鸢尾花的类别将降维后的数据点保存在不同的表表中
if y[i]==0:
red_x.append(reduced_x[i][0])
red_y.append(reduced_x[i][1])
elif y[i]==1:
blue_x.append(reduced_x[i][0])
blue_y.append(reduced_x[i][1])
else:
green_x.append(reduced_x[i][0])
green_y.append(reduced_x[i][1])
plt.scatter(red_x,red_y,c='r',marker='x')
plt.scatter(blue_x,blue_y,c='b',marker='D')
plt.scatter(green_x,green_y,c='g',marker='.')
plt.show()
三、基于MATLAB的主成分分析
3.1算法步骤

 3.2代码
3.2代码
1.读取数据
此为读取csv数据,括号内1,0;表示从第一行第一列读取,matlab默认以0行,0列开始读取
X= csvread('文件路径',1,0); %读取数据文件,第一行不读取在此举例一个数据 data 下面都是用此数据进行做:
data = [1,-0.2,0.3,0.8,-0.5
-0.2,1,0.6,-0.7,0.2
0.3,0.6,1,0.5,-0.3
0.8,-0.7,0.5,1,0.7
-0.5,0.2,-0.3,0.7,1]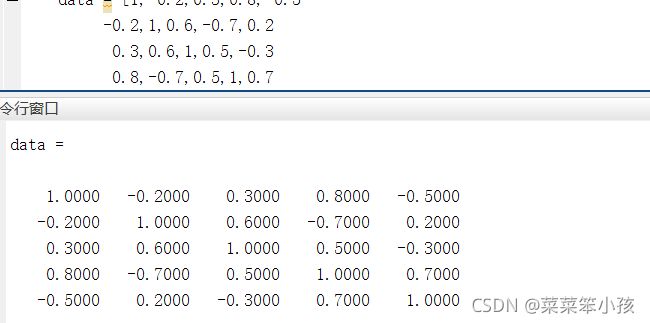
2.得到相关矩阵
(1)数据标准化做法
进行标准化
z =zscore(data)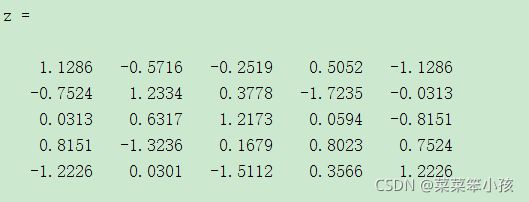
计算相关系数矩阵
C = corr(z,'type','Pearson')
(2)数据未标准化做法
计算均值:
mapping.mean = mean(data, 1) %计算均值
进行中心化不会改变协方差阵的值,中心化不是标准化哦!!
data = data - repmat(mapping.mean, [size(data, 1) 1])%去均值
计算协方差阵:
C = cov(data) %协方差矩阵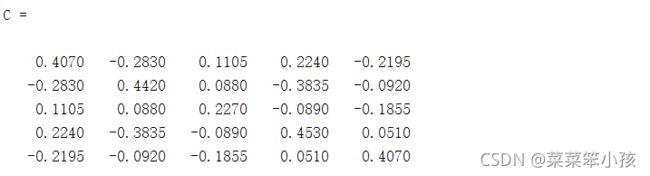
3.求相关矩阵的特征值和相对应的特征向量(在此以协方差阵为例)
[M, lambda] = eig(C) %求C矩阵特征向量及特征值 
取出协方差阵所求的对角线上的特征值,这只是其中一种做法,下面还有第二种
y = diag(lambda) %取出特征值矩阵中的特征值 
1时计算得到行数,2时计算得到列数,一个补充小知识点,嘻嘻嘻!!
size(data,2) %读取数据文件中的列数 
4.画散点图和折线图
这里求得是x轴的值,上面取出的特征值即为y轴的值!!!
x = [size(data,2):-1:1] %表示变量个数并倒写出它们作为x轴 如 4,3,2,1

先画的散点图,x,y的值上面介绍了哦!!
plot(x,y,'o') %绘制散点图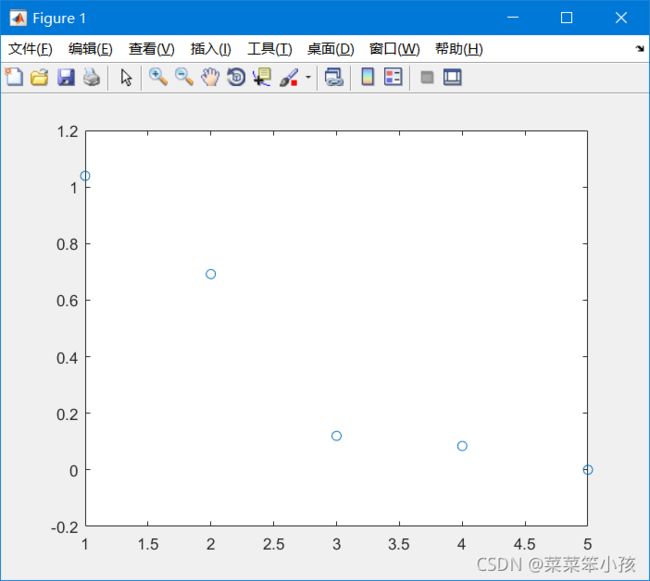
显示上图中的格格线为 grid on ;关闭为 grid off
grid on; %显示格线
因为我想在同一张图上画散点图和折线图,所以调用 hold on
hold on; %不换画布继续在这张画布上绘制给坐标轴取名 ,你随意,哈哈哈哈!!!
xlabel('x'); %x轴名称
ylabel('y'); %y轴名称
绘制折线图,颜色为红(’r‘) ,'lineWidth':线粗
plot(x,y,'-','Color','r','lineWidth',1) %绘制折线图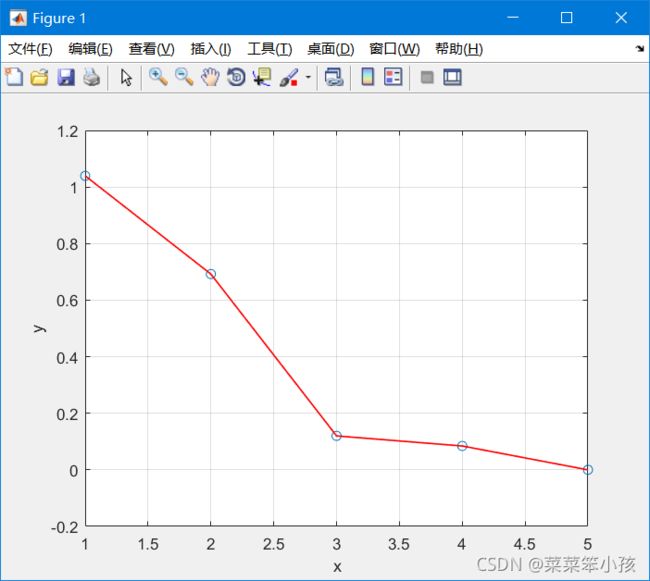
5.对特征值排序
在此求出的 lambda 即为上方的 x,ind 即为 上方的 y;descend 为降序,默认升序
[lambda, ind] = sort(diag(lambda), 'descend') %排序
6.求每个特征值的贡献度
即为每个特征值除以所有特征值的和,即占比
lambda=lambda./sum(lambda) %特征值的贡献度
7.累计贡献度
计算累计贡献度
lambda=cumsum(lambda) %累计贡献度
选出累计贡献度小于 85%之前的指标
为什么要选>85%呢?是为了方便后面的索引
k=find(lambda>0.85) %选出贡献率达到85的指标前K个 
让我们看一下k(1)等于多少???

那 1:k(1) 呢,又是多少???
1:k(1) 
但我们看上面累计贡献度时符合条件<85%的只有一个,所以我们下方选主成分应该有有变化
8.选出主成分,并得出相对应的矩阵
选出前K列的特征向量矩阵
M = M(:,ind(1:k(1)-1) %%取前k列
M = (-1)*M得到降维后的X
mappedX = data * M %降维后的X
9.画色块矩阵图
通过此可以再次确定,下面画图需要设置的x,y的行数
mapping.M = M %映射的基
设置色块矩阵图x,y轴所标注的名称
XVarNames={'A'}; %个数等于上面基的列数
YVarNames={'A','B','C','D','E'}; %个数等于上面基的行数数值矩阵图代码:
matrixplot(M,'FillStyle','nofill','XVarNames',XVarNames,'YVarNames',YVarNames)
%色块颜色表示
matrixplot(M,'XVarNames',XVarNames,'YVarNames',YVarNames,'DisplayOpt','off','FigSize','Auto','ColorBar','on'); 
完整代码
data = [1,-0.2,0.3,0.8,-0.5
-0.2,1,0.6,-0.7,0.2
0.3,0.6,1,0.5,-0.3
0.8,-0.7,0.5,1,0.7
-0.5,0.2,-0.3,0.7,1]
% z =zscore(data)
% C = corr(z,'type','Pearson')
mapping.mean = mean(data, 1) %计算均值
data = data - repmat(mapping.mean, [size(data, 1) 1])%去均值
C = cov(data) %协方差矩阵
[M, lambda] = eig(C) %求C矩阵特征向量及特征值
y = diag(lambda) %取出特征值矩阵中的特征值
size(data,2) %读取数据文件中的列数
x = [size(data,2):-1:1] %表示变量个数并倒写出它们作为x轴 如 4,3,2,1
plot(x,y,'o') %绘制散点图
grid on %显示格线
hold on; %不换画布继续在这张画布上绘制
xlabel('x'); %x轴名称
ylabel('y'); %y轴名称
plot(x,y,'-','Color','r','lineWidth',1); %绘制折线图
[lambda, ind] = sort(diag(lambda), 'descend') %排序
lambda=lambda./sum(lambda)
lambda=cumsum(lambda)
k=find(lambda>0.85) %选出贡献率达到95的指标前K个
M = M(:,ind(1:k(1)-1) %%取前k列
M = (-1)*M
mappedX = data * M %降维后的X
mapping.M = M %映射的基
XVarNames={'A'};
YVarNames={'A','B','C','D','E'};
matrixplot(M,'FillStyle','nofill','XVarNames',XVarNames,'YVarNames',YVarNames);
matrixplot(M,'XVarNames',XVarNames,'YVarNames',YVarNames,'DisplayOpt','off','FigSize','Auto','ColorBar','on');