matlab手写数字识别_MNIST手写数字识别
项目背景
MNIST 数据集是经典的手写数字识别数据集,每个样本28*28。如图所示 data set download
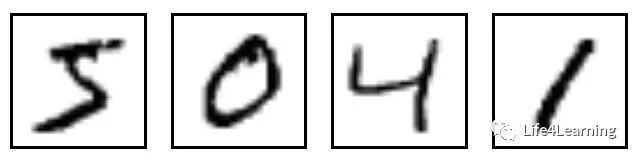 dataset template
dataset template
- 精简版MNIST:一共1797个样本,每个样本
8*8,sklearn自带 - 完整版MNIST:一共6万个样本(5万个训练,1万个测试),每个样本
28*28
数据探查
# -*- coding: utf-8 -*-
from sklearn.datasets import load_digits # 精简版MNIST
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier, export_graphviz
digits = load_digits()
print(type(digits)) # Bunch类是字典的子类,所以继承了字典的方法
print('字典的 key:',digits.keys())
字典的 key: dict_keys(['data', 'target', 'target_names', 'images', 'DESCR'])print('数据集大小:{}\n图片数组:{}\n图片标签:{}\n标签类别:{}'.format(
digits.data.shape,digits.target.shape,digits.images.shape,digits.target_names))
数据集大小:(1797, 64)
图片数组:(1797,)
图片标签:(1797, 8, 8)
标签类别:[0 1 2 3 4 5 6 7 8 9]
digits.images[0]
array([[ 0., 0., 5., 13., 9., 1., 0., 0.],
[ 0., 0., 13., 15., 10., 15., 5., 0.],
[ 0., 3., 15., 2., 0., 11., 8., 0.],
[ 0., 4., 12., 0., 0., 8., 8., 0.],
[ 0., 5., 8., 0., 0., 9., 8., 0.],
[ 0., 4., 11., 0., 1., 12., 7., 0.],
[ 0., 2., 14., 5., 10., 12., 0., 0.],
[ 0., 0., 6., 13., 10., 0., 0., 0.]])
# 为图像数据拉平后数据,每条记录一个图片
digits.data[0]
array([ 0., 0., 5., 13., 9., 1., 0., 0., 0., 0., 13., 15., 10.,
15., 5., 0., 0., 3., 15., 2., 0., 11., 8., 0., 0., 4.,
12., 0., 0., 8., 8., 0., 0., 5., 8., 0., 0., 9., 8.,
0., 0., 4., 11., 0., 1., 12., 7., 0., 0., 2., 14., 5.,
10., 12., 0., 0., 0., 0., 6., 13., 10., 0., 0., 0.])
# 图片查看
import matplotlib.pyplot as plt
n = 1001
plt.imshow(digits.images[n],cmap='gray') # color map:gray cool pink
plt.title('curr digit is:{}'.format(digits.target[n]))
plt.show()
 4
4
数据分割与标准化
# 分割数据,将25%的数据作为测试集,其余作为训练集
x_train,x_test,y_train,y_test = train_test_split(digits.data, digits.target,test_size=0.2,random_state=100)
print('训练样本数:{}\n测试样本数:{}'.format(x_train.shape[0],x_test.shape[0]))
# 采用Z-Score规范化:此处标准化为 按列标准化
ss = preprocessing.StandardScaler()
x_train_ss = ss.fit_transform(x_train)
x_test_ss = ss.transform(x_test)
print('转换前:\n',x_train[0])
print('转换后:\n',x_train_ss[0])
训练样本数:1437
测试样本数:360
转换前:
[ 0. 0. 9. 16. 12. 2. 0. 0. 0. 0. 16. 3. 5. 10. 0. 0. 0. 0.
13. 4. 14. 16. 4. 0. 0. 0. 4. 16. 16. 16. 7. 0. 0. 0. 0. 3.
4. 10. 4. 0. 0. 0. 0. 0. 0. 8. 6. 0. 0. 0. 12. 1. 1. 13.
3. 0. 0. 0. 8. 15. 16. 9. 0. 0.]
转换后:
[ 0. -0.33172432 0.80667633 0.97168683 0.02959097 -0.68759375
-0.4195837 -0.13063238 -0.06609341 -0.62886341 1.02852613 -2.24294429
-1.10644589 0.29086024 -0.52226886 -0.13689693 -0.04573894 -0.73294367
0.54771929 -0.52845753 1.12211786 1.31423416 0.65444395 -0.11633278
-0.02638899 -0.78291337 -0.83062364 1.21017948 0.98303796 1.42744663
1.26776782 -0.0528332 0. -0.66734426 -1.20692862 -0.99259421
-1.08833759 0.21962165 0.32375513 0. -0.06519029 -0.53074071
-1.0416785 -1.12525354 -1.25181187 -0.05506717 0.6019917 -0.09267686
-0.03963009 -0.400891 0.79618512 -1.6263099 -1.6142148 0.69404232
-0.14346643 -0.20781245 -0.02638899 -0.28936833 0.48229981 0.65287562
0.84500216 0.37473485 -0.49973375 -0.19791747]
print('转换前第二列:\n',x_train[:10,2])
print('转换后第二列:\n',x_train_ss[:10,2])
转换前第二列:
[ 9. 0. 0. 1. 2. 13. 11. 5. 14. 13.]
转换后第二列:
[ 0.80667633 -1.10233464 -1.10233464 -0.89022231 -0.67810998 1.65512565
1.23090099 -0.04177299 1.86723798 1.65512565]
LogisticRegression Model
from sklearn.metrics import accuracy_score, classification_report,log_loss, confusion_matrix
def model_eva(model,x_train,y_train,x_test,y_test):
model.fit(x_train,y_train)
print(model)
y_pred = model.predict(x_test)
y_prob = model.predict_proba(x_test)
print('acc:{:.2%}'.format(accuracy_score(y_test,y_pred)))
print('log_loss:{:.4f}'.format(log_loss(y_test,y_prob)))
print('confusion matrix(row is true label):\n',confusion_matrix(y_test, y_pred))
print('classification report:\n',classification_report(y_test,y_pred))
return model
# 创建LR分类器
lr_model = LogisticRegression()
lr_model = model_eva(lr_model,x_train_ss,y_train,x_test_ss,y_test)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
acc:98.06%
log_loss:0.1084
confusion matrix(row is true label):
[[42 0 0 0 0 0 0 0 0 0]
[ 0 31 0 0 0 0 0 0 1 0]
[ 0 0 41 0 0 0 0 0 0 0]
[ 0 0 0 32 0 0 0 0 0 0]
[ 0 0 0 0 35 0 0 0 1 0]
[ 0 0 0 0 0 35 0 0 0 0]
[ 0 0 0 0 0 0 39 0 1 0]
[ 0 0 0 0 0 0 0 38 1 0]
[ 0 1 0 0 0 1 0 0 25 0]
[ 0 0 0 1 0 0 0 0 0 35]]
classification report:
precision recall f1-score support
0 1.00 1.00 1.00 42
1 0.97 0.97 0.97 32
2 1.00 1.00 1.00 41
3 0.97 1.00 0.98 32
4 1.00 0.97 0.99 36
5 0.97 1.00 0.99 35
6 1.00 0.97 0.99 40
7 1.00 0.97 0.99 39
8 0.86 0.93 0.89 27
9 1.00 0.97 0.99 36
accuracy 0.98 360
macro avg 0.98 0.98 0.98 360
weighted avg 0.98 0.98 0.98 360
# 预测评估
y_pred = lr_model.predict(x_test_ss)
y_prob = lr_model.predict_proba(x_test_ss)
print('Top20 real value:{}\nTop20 pred value:{}'.format(y_test[:20],y_pred[:20]))
Top20 real value:[9 9 0 2 4 5 7 4 7 2 4 5 7 5 9 6 1 1 5 2]
Top20 pred value:[9 9 0 2 4 5 7 4 7 2 4 5 7 5 9 6 1 1 5 2]
print('第一个元素{}预测为各个类别的概率:'.format(y_test[0]))
[round(x,2) for x in y_prob[0]]
第一个元素9预测为各个类别的概率:
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.01, 0.99]
DecisionTreeClassifier Model
# DecisionTreeClassifier?
# 创建LR分类器
dt_model = DecisionTreeClassifier(criterion='gini',max_depth=8,min_samples_leaf=3,min_samples_split=5)
dt_model = model_eva(dt_model,x_train_ss,y_train,x_test_ss,y_test)
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=8, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=3, min_samples_split=5,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
acc:86.39%
log_loss:3.0553
confusion matrix(row is true label):
[[40 0 0 0 0 0 0 0 2 0]
[ 0 25 2 1 0 0 0 0 2 2]
[ 1 1 36 0 0 0 0 1 1 1]
[ 0 1 0 29 0 0 0 0 2 0]
[ 1 4 1 0 30 0 0 0 0 0]
[ 0 0 0 0 1 32 0 0 1 1]
[ 0 1 0 0 3 0 35 0 1 0]
[ 0 1 0 0 2 0 0 36 0 0]
[ 0 4 2 1 0 0 0 0 19 1]
[ 2 1 0 0 0 1 0 2 1 29]]
classification report:
precision recall f1-score support
0 0.91 0.95 0.93 42
1 0.66 0.78 0.71 32
2 0.88 0.88 0.88 41
3 0.94 0.91 0.92 32
4 0.83 0.83 0.83 36
5 0.97 0.91 0.94 35
6 1.00 0.88 0.93 40
7 0.92 0.92 0.92 39
8 0.66 0.70 0.68 27
9 0.85 0.81 0.83 36
accuracy 0.86 360
macro avg 0.86 0.86 0.86 360
weighted avg 0.87 0.86 0.87 360
决策树可视化
# method1:模型存入dot文件
export_graphviz(decision_tree=dt_model,out_file='./mnist_cart_tree.dot')
# method2:
import pydotplus
from IPython.display import Image
dot_data = export_graphviz(dt_model, out_file=None,
feature_names=['x{}'.format(i) for i in range(64)],
class_names=[str(x) for x in digits.target_names],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("digits.pdf")
Image(graph.create_png())
 DecisionTreeClassifier
DecisionTreeClassifier
特征重要性
dt_model.feature_importances_
array([0. , 0. , 0.00520327, 0.00785486, 0. ,
0.07855059, 0. , 0. , 0. , 0.01787814,
0. , 0. , 0.01536566, 0.00569116, 0. ,
0. , 0. , 0.00258796, 0.00473143, 0.00675744,
0.04590427, 0.10423992, 0. , 0. , 0. ,
0.0005763 , 0.01340139, 0.07077978, 0. , 0.05632963,
0.00253087, 0. , 0. , 0.05953009, 0.03167467,
0.00831266, 0.07904854, 0.0251513 , 0.00813837, 0. ,
0. , 0. , 0.13156839, 0.05812517, 0.01932968,
0. , 0.00689203, 0. , 0. , 0. ,
0.01151484, 0.00037001, 0. , 0.02079295, 0.02523062,
0. , 0. , 0.00128446, 0. , 0. ,
0.06884966, 0.00333009, 0.00247378, 0. ])
结论
- 模型保存时,需要将标准化的公式保存,然后再保存模型
- LR模型在预测手写数字时,效果非常好;决策树反而较差
补充知识
- logloss = ,其中为的真实值;为示性函数,为样本预测为类的概率
- 当预测越准,logloss 越小
# 热力图
import seaborn as sns
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm,square=True,annot=True) # square 格子是否方形 annot 是否标注数值
 heatmap
heatmap