二维目标检测sota---TOOD任务对齐的一阶目标检测算法
代码链接
paper链接
个人博客
问题
本文首先提出了一个目前一阶目标检测器存在的普遍问题就是在head部分将分类和定位这两个任务并行的来做了。这样的话就存在两个任务之间不对齐的问题。因为两个任务是的目标不一样。分类任务更加关注目标的显著的,关键的特征。而定位任务更加关注图像的边界特征。这就导致当使用两个独立的分支来进行预测的时候,会导致一定程度上的结果的不能对齐。

如上图所示,第一张中的result列,绿色和红色的方块表示的是在定位任务和分类任务中生成的最有的anchor,白色箭头表明的是最优的anchor相对目标中心偏移。从上述中我们可以看出,第一行中的分类任务红色anchor的最优的anchor虽然分类出了dining table,但是其最优的anchor确是在piza上。而最优的定位任务的anchor,其分类的分数又很低。这就是两个任务没有对齐的表现。就是说分类性能好的anchor,其定位的精度差。定位精度高的anchor,其分类性能差。
此外,目前对于anchor的分配策略也是任务无关的。例如上图中的,由于最优的定位anchor不位于目标的中心点,因此他很难和最优的分类的anchor进行绑定。这就造成一个精确的bbox在NMS的过程中可能会被一个不太精确的bbox抑制住。
作者还分析了一些启发式的规则的缺点
解决方法
为了解决上述问题,作者提出了一个任务对齐的一阶目标检测头。其主要做了两方面的工作,一个是设计了一个任务对齐的head,另一方面是设计了一个任务对齐的学习方法,后者主要表现为设计了一种任务对齐的分配策略和任务对齐有关的损失函数。
任务对齐的head
不同于传统的单阶段的目标检测的网络。作者通过两个方面来改进不同任务之间相关独立的问题。首先是增加两个任务之间的交互,另一个提高检测头学习对齐的能力。其中检测头分为T-head部分和TAP部分。其具体结构如下图所示:

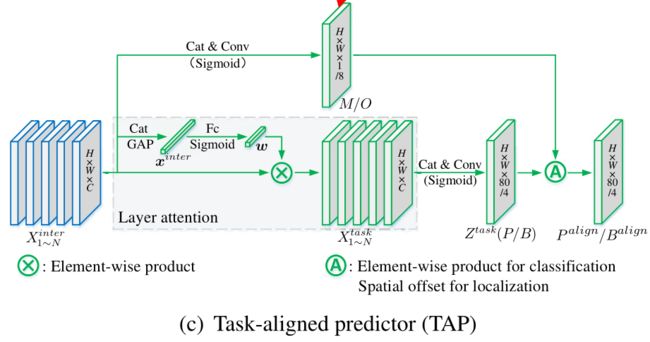
其中TAP的结构非常简单,就是在RPN的特征图上使用了几个卷积层,并分别保存各个卷积层的输出,作者把这部分特征图称为 两个任务之间的交互特征。然后分别使用TAP这个子网络在交互特征上进行分类和定位任务的预测。到这里,我理解的还是和普通的分两个分支进行预测的任务是没什么区别的,只是多了几个卷积层。重点在这个TAP部分。
由于两个任务的预测都是基于这个交互特征来完成的,但是两个任务对于特征的需求肯定是不一样的,因为作者设计了一个layer attention来为每个任务单独的调整一下特征,这个部分的结构也很简单,可以理解为是一个channel-wise的注意力机制。这样的话,我们就得到了对于每个任务单独的特征 X 1 N t a s k X_{1~N}^{task} X1 Ntask然后再利用这些特征生成我们所需要的类别或者定位的特征图。
在生成预测结果之后,作者为了能够更加深入的对其两个任务,显式的调整了两个预测的空间分布。不同于以往的网络利用一个无中心的,或者IoU分支,根据分类特征和定位特征来调整分类的预测。本文通过计算的任务交互特征(上图中的蓝色部分)来同时考虑两个任务。如上图TAP的结构图中可以看出,作者计算了从交互特征中计算了一个大小为 H × W × 1 H \times W \times 1 H×W×1的空间概率图 M M M,这个概率图被用于调整分类的预测输出 P P P.其调整方法如下图公式所示:
P a l i g n = P × M P^{align}=\sqrt{{P \times M}} Palign=P×M
这里可以理解为 M M M是用来评价这个位置两个任务的对齐的程度。
上面是对于分类损失任务的调整,此外,作者还计算了对于定位任务部分的偏移。其首先利用交互特征计算了关于空间偏移图,大小为 O ∈ R H × W × 8 O \in R^{H \times W \times 8} O∈RH×W×8。然后使用这个来调整关于定位任务的输出。其计算方法如下所示:
B a l i g n ( i , j , c ) = B ( i + O ( i + O ( i , j , 2 × c ) , j + O ( i , j , 2 × c + 1 ) ) , c ) B^{align}(i,j,c)=B(i + O(i + O(i, j, 2\times c), j + O(i, j , 2 \times c + 1)), c) Balign(i,j,c)=B(i+O(i+O(i,j,2×c),j+O(i,j,2×c+1)),c)
上述的意思就是,我针对每个位置的anchor,都使用交互特征计算了一个偏移,告诉他最好的anchor是位于什么位置。但是这些偏移肯定都是不是整数,因此这部分使用的是线性插值的方法来完成的。此外,值得注意的是,这部分是对每个通道单独去做的。这意味着每个边界都有计算自己的偏移,这能够带来更加精度的预测,因为每个边界都能从其周围最精确的anchor中学习到信息。
至此,我们就介绍完了文中关于T-head部分结构的描述。从这个自网络的结构中可以看出,其任务对齐主要是通过三个方面来完成的,一个是任务交互的特征,然后是逐个任务的特征,最后利用交互特征来对任务特征的预测输出来学习偏移,使得两个任务能够更好的交互。
任务对齐的学习
为了能够更好的知道前面的T-head网络能够进行任务对齐的预测,作者还介绍了一种任务对齐的学习方法TAL.这个方法主要包含两个方面的内容,一个是能够根据涉及的指标动态的选择高质量的anchor,另一方面,他同时考虑了anchor划分和权重。这部分主要通过一个简单的anchor划分策略和特别涉及的损失函数来实现两任务的对齐。首先是任务对齐的anchor划分策略,就是选择哪些anchor为positive,哪些anchor是positive。另一方面是涉及了一个任务对其的损失函数。
任务对齐的分配策略
为了能够应付NMS,一个好的分配策略应该能够满足一下规则:
- 一个对齐的好的anchor应能够预测较高的分类分数同时还有精确的定位框。
- 一个没有对齐的anchor应该具有较低的分类分数同时被抑制。
为了能够实现上述目标,作者设计了一个用于评价anchor对齐指标的值,这里将其记为 t t t.其计算方法如下:
t = s α × u β t = s^{\alpha} \times u^{\beta} t=sα×uβ
其中 s s s表示预测类别的置信度, u u u表示预测的边界框的IoU. α \alpha α和 β \beta β用来控制两个任务对于对齐指标的影响。值得注意的是, t t t在两个任务共同对齐优化中起着非常重要的作用,他鼓励网络去动态的关注任务对齐的anchor。
有了上述评价指标之后,我们就根据 t t t来选择 k k k个最大的anchor作为positive,其余的都是negative的。
任务对齐的损失
在分类对象方面,为了能够显示的增加对齐的anchor的分类分数,同时,减少没有对齐的anchor的分类分数,文中在训练过程中使用 t t t来代替positive的二值标签。但是作者发现,随着 α \alpha α和 β \beta β的增大, t t t变得非常小,这导致网络没办法收敛。因此作者对 t t t进行了归一化,记为 t ^ \hat t t^,并用他来代替positive的二值标签。
其中 t ^ \hat t t^应具有以下两个性质:
- 应能够保证困难目标的高效的学习。困难目标就是对于所有与之对应的positive anchor的 t t t都很小
- 需要根据预测的边界框的精度保持实例之间的顺序。
因此,作者设计了一个实例级别的归一化来调整 t ^ \hat t t^的范围,作者将 t ^ \hat t t^的最大值设置为实例之间的最大IoU.也就是计算 t t t的式子中的 u u u的值,至于其余的是怎么变化的需要去看一下代码。这样的话,我们就将分类损失设计为一下形式:

在定位方面,为了使得网络能够更好的关注对齐的网络,作者使用上面提出的对齐的衡量指标 t ^ \hat t t^来作为回归损失的权重。就是说,如果这个anchor越是任务对齐的,即 t ^ \hat t t^就越大,那么这个anchor的GIoU损失在整个损失函数中所占的比重就越大,我们可以理解为网络就更加的关注这些anchor。如果 t ^ \hat t t^的值小的话,作用刚好相反。因此就有了一下损失函数的设计。
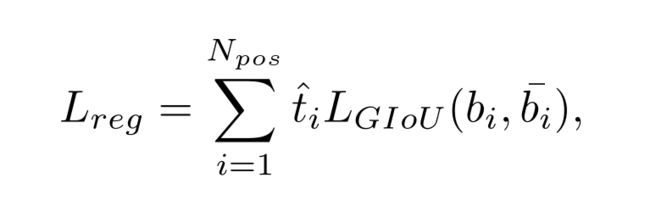
所以,总的损失函数就是由上述两个损失组成。
解决效果
作者在MS COCO数据集上去了AP 51.1的成绩。
消融实验
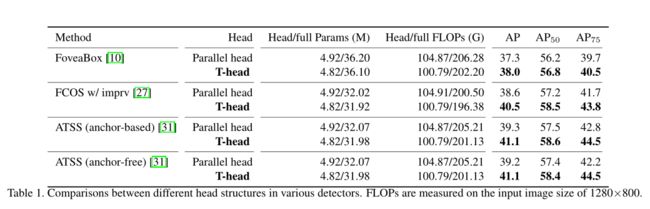
T-Head和其他并行结构的头的对比。
TAL的anchor选择方法和其他anchor选择方法的对比。

anchor-based的TOOD的anchor-free的TOOD的性能的区别:
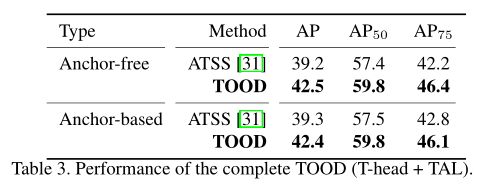
从上表可以看出,anchor-free和anchor-based这两个TOOD的性能相差不是很大。
关于 t t t的计算过程中, α \alpha α和 β \beta β不同的值对于模型性能的影响。

从上表可以看出,这个超参数对于模型性能的影响并不是很大。