40、CUDA学习笔记
一、CUDA安装
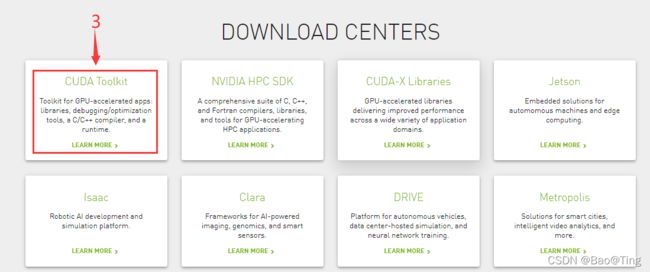
1.1、CUDA的下载






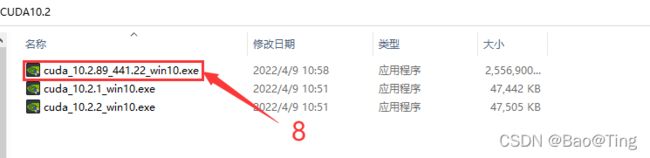
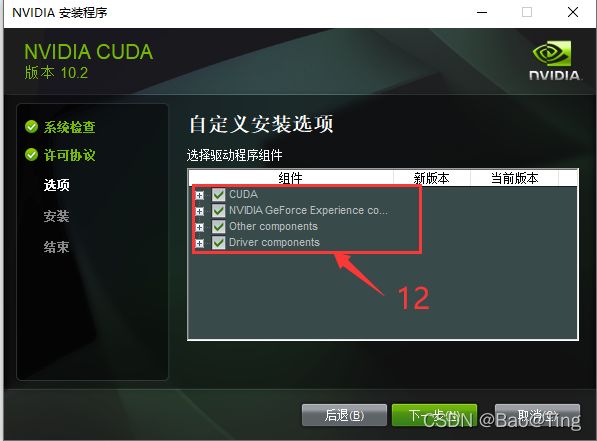
1.2、CUDA的安装


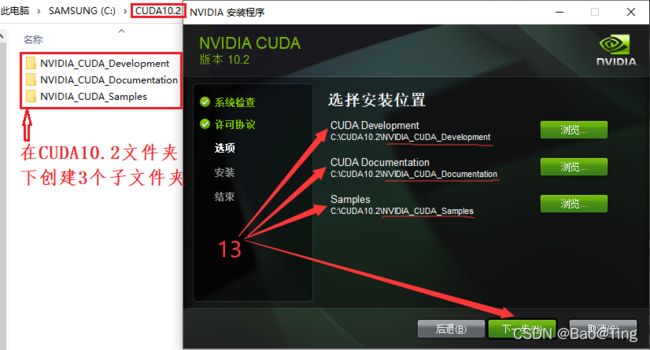
1.3、更新补丁的安装
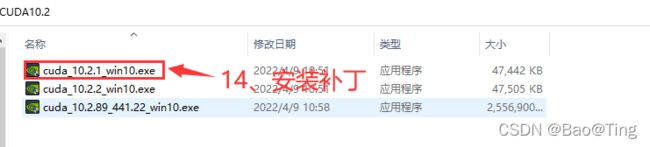
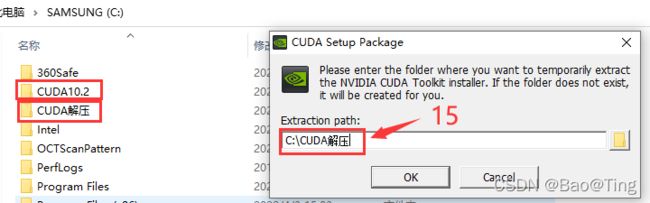
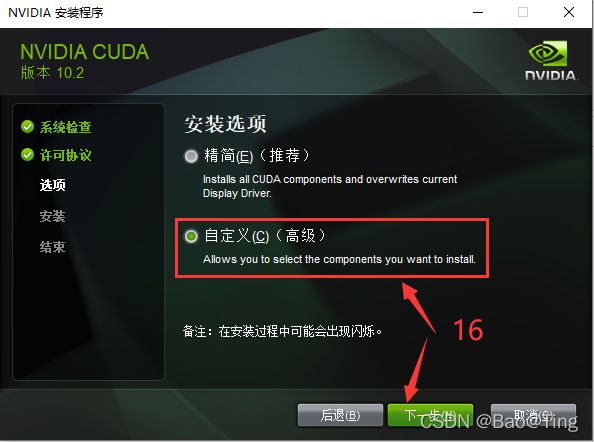

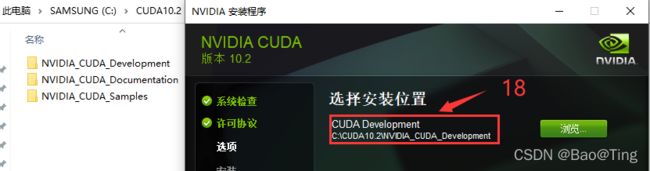


CUDA10.2子目录介绍:
NVIDIA_CUDA_Development: CUDA 开发环境
NVIDIA_CUDA_Documentation:CUDA 开发文档
NVIDIA_CUDA_Samples: CUDA示例程序
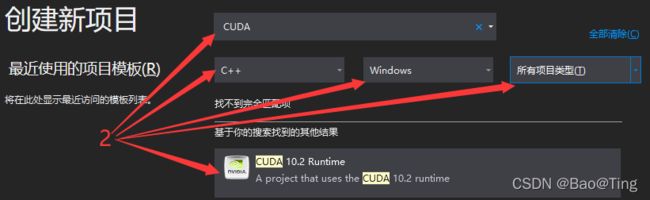
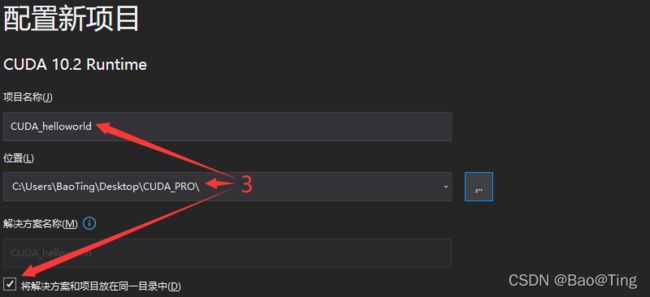
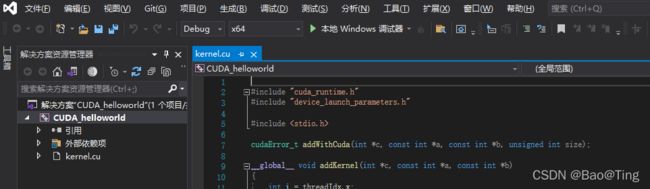
二、VS工程创建

三、GPU开发前言
CUDA是一个API库,这个库的作用是让CPU能以某种编程框架控制GPU运行程序,学习CUDA编程时你要明确GPU的地位,它就是一个从机,CPU通过PCIE总线控制GPU,所以既然是从机,对CPU来讲就会出现从机无响应、超时响应的情况,当不使用GPU的时候,不需要GPU来响应,但是当你把一段程序送到GPU执行,则必须设置超时时间,否则如果GPU一直不相应,那这个程序不就乱了。所以CUDA核函数被启动后,在规定的时间不能执行完毕,则会出现超时错误cudaErrorLaunchTimeout。这个超时时间是可以设置的,设置方式如下:
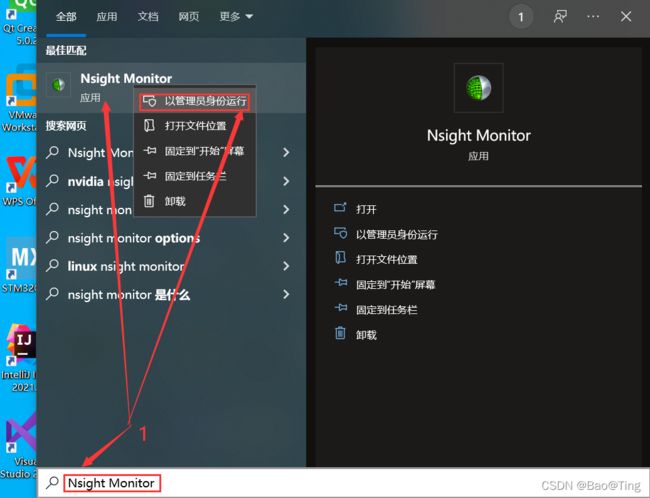

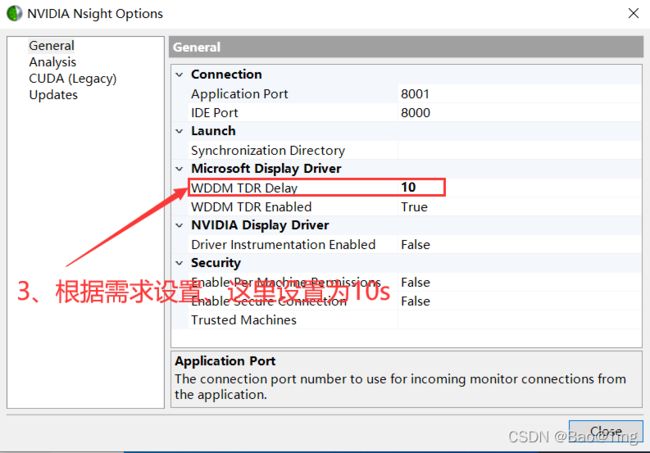
最后重启电脑即可。
四、CUDA C教程
4.1、线程束(warp)
SIMT(Signle Instruction Multiple Thread):单指令多线程,CUDA的执行模型。
SIMD(Signle Instruction Multiple Data):单指令对数据,多在CPU的流指令集使用。
SIMT:一个指令,多个线程执行,每个线程操作应不同的数据。
SIMD:一个指令,同时操作多个数据。(控制能力很强)。
线程束:SM所控制的核,SM分发指令给所有核,即使开启一个线程,也会分发指令给所有的核。
一个线程占用也会占用一个SM,但也只有一个核在活跃态,另外的核处于不活跃态。
4.2、主机上的两种内存分配
虚拟内存 = RAM + 硬盘,系统会把优先级低不常用代码暂时从RAM置换到硬盘中。
可置换页内存:(new、malloc) => 可发生物理置换,不可直接被GPU访问。
页锁定内存:(cudaMallocHost、cudaHostAlloc) => 不可发生物理置换,可直接被GPU访问。
GPU使用可置换页内存的过程:可置换页 => 页锁定内存 => GPU。(先复制一份,使用复制的)
页锁定内存本质还是在主机上,虽然比可置换内存块,而且不用拷贝到GPU就可以直接使用,但由于PcIe总线的问题,GPU访问其效率还是很低的,远不及GPU的Global Memory。
适合一次性读写,大数据传输中间存储,比如整体拷贝到GPU上,或者GPU拷贝到内存上。
注意:页锁定内存 由cudaFreeHost释放。cudaHostAlloc有多个模式。
4.3、CUDA统一内存申请
由cudaMallocManaged分配,cudaFree释放。其分配的内存可能在主机上,也可能在GPU的全局内存上,CPU和GPU内存统一,编址统一。
4.4、CUDA常量内存
常量内存在GPU上,速度很快。和函数中只能读,不能修改的变量。
使用方式一:
__constant__ float warp_matrix[6] = {1,2,3,4,5,6}; //定义直接初始化
使用方式二:
__constant__ float warp_matrix[6] = {1,2,3,4,5,6}; //定义直接初始化
int main(){
float host_warp_matrix[6] = {6,5,4,3,2,1};
cudaMemcpyToSymbol(warp_matrix,host_warp_matrix,sizeof(host_warp_matrix));
//覆盖掉warp_matrix的初始化定义
test_kernel<<<1,6>>>();
}
4.5、VS CUDA项目之矩阵求和
矩阵求和比较简单,这里不在赘述。
4.6、VS CUDA项目之规约求和
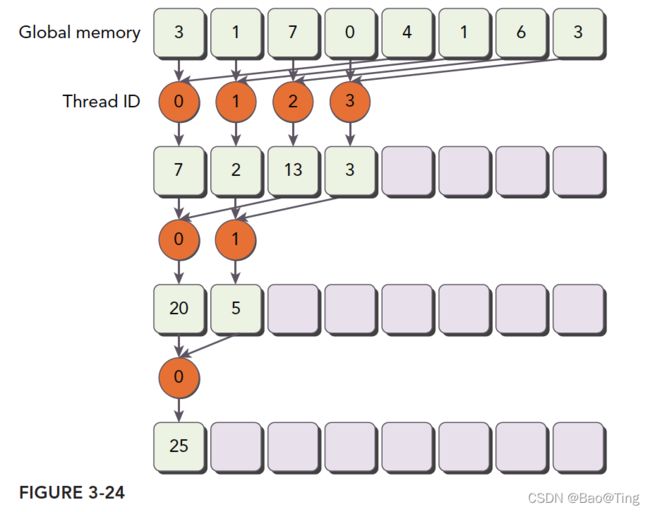
#include "kernel.cuh"
__global__ void sumPeace(float* g_idata, float* g_odata, unsigned int n)
{
unsigned int tid = threadIdx.x;
unsigned idx = blockIdx.x * blockDim.x + threadIdx.x;
//convert global data pointer to the local point of this block
float* idata = g_idata + blockIdx.x * blockDim.x; //0*1024---->1023*1024
if (idx >= n) return;
//in-place reduction in global memory
for (int stride = blockDim.x >> 1; stride > 0; stride >>= 1){
if (tid < stride){
idata[tid] += idata[tid + stride];
}
__syncthreads();
}
//write result for this block to global men
if (tid == 0) { g_odata[blockIdx.x] = idata[0]; }
}
//函数使用示例
int main()
{
LARGE_INTEGER timeStart; //开始时间
LARGE_INTEGER timeEnd; //结束时间
LARGE_INTEGER frequency; //计时器频率
QueryPerformanceFrequency(&frequency);
int nElems = 1<<16;
printf("= %d\r\n", nElems);
dim3 thread(512, 1);
printf(" = thread(%d,%d,%d)\r\n",thread.x,thread.y,thread.z);
dim3 block((nElems - 1) / thread.x + 1, 1); //向上取整
printf(" = block(%d,%d,%d)\r\n", block.x, block.y, block.z);
float* MatI_h = new float[nElems];
float* MatO_h = new float[block.x];
//CPU内存申请
int MatI_Bytes = nElems * sizeof(float);
int MatO_Bytes = block.x * sizeof(float);
for (int i = 0; i < nElems; i++) MatI_h[i] = i * 1.0 / 1000.0;
for (int i = 0; i < block.x; i++) MatO_h[i] = 0;
//GPU内存申请
float* MatI_d = 0;
float* MatO_d = 0;
CHECK(cudaMalloc((void**)&MatI_d, MatI_Bytes));
CHECK(cudaMalloc((void**)&MatO_d, MatO_Bytes));
//CPU内存->GPU内存
CHECK(cudaMemcpy(MatI_d, MatI_h, MatI_Bytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(MatO_d, MatO_h, MatO_Bytes, cudaMemcpyHostToDevice));
//选择在哪个GPU上运行
cudaError_t cudaStatus = cudaSetDevice(0);
//在GPU上启动一个内核,每个元素有一个线程
QueryPerformanceCounter(&timeStart);
sumPeace << > > (MatI_d,MatO_d,nElems);//传入的形参在CPU主存上
CHECK(cudaGetLastError());
CHECK(cudaDeviceSynchronize());
QueryPerformanceCounter(&timeEnd);
double elapsed = (timeEnd.QuadPart - timeStart.QuadPart) / (double)frequency.QuadPart;
std::cout << "gpu spend " << elapsed << "sec" << std::endl;//单位为秒,精度为微秒(1000000/cpu主频)
CHECK(cudaMemcpy(MatO_h, MatO_d, MatO_Bytes, cudaMemcpyDeviceToHost));
cudaFree(MatI_d);cudaFree(MatO_d);
float gpu_sum = 0;
for (int i = 0; i < block.x; i++) {
gpu_sum += MatO_h[i];
}
printf("gpu_sum = %f\r\n", gpu_sum);
delete[] MatI_h;
delete[] MatO_h;
return 0;
} 4.7、VS CUDA项目之展开循环
4.8、VS CUDA项目之动态并行
1、项目==>属性==>CUDA C/C++==>Common==>Generate Relocatable Device Code==>是
2、项目==>属性==>链接器==>输入==>附加依赖项==>添加 cudadevrt.lib
3、项目==>属性==>CUDA C/C++==>Device==>改为 compute_50,sm50
示例代码:
#include "kernel.cuh"
__global__ void nesthelloworld(int iSize, int iDepth)
{
unsigned int tid = threadIdx.x;
printf("depth : %d blockIdx: %d,threadIdx: %d\n", iDepth, blockIdx.x, threadIdx.x);
if (iSize == 1) return;
int nthread = (iSize >> 1);
if (tid == 0 && nthread > 0)
{
nesthelloworld<<<1,nthread>>>(nthread,++iDepth);
printf("--> nested execution depth: %d\n", iDepth);
}
}
int main(int argc, char* argv[])
{
int size = 64;
int block_x = 2;
dim3 block(block_x,1);
dim3 grid((size - 1) / block.x + 1,1);
nesthelloworld<<>> (size, 0);
cudaGetLastError();
cudaDeviceReset();
return 0;
}