R、主成分分析(PCA)、ggplot2
R、主成分分析(PCA)、ggplot2
在生态环境领域中,作为非约束排序的方法之一,主成分分析(PCA)是我们常用的分析方法。本文以R语言vegan包rda函数演示主成分排序及基于ggplot2绘图。
a=read.csv("D:/wykt/sp.csv",header = T,row.names = 1)
library(vegan)
library(ggplot2)
library(ggrepel)
dd=rda(log10(a))###此处对物种数据取对数作转化,可根据自己数据选择合适的转化方法
oo=summary(dd)
site=as.data.frame(oo$sites)###提取样方坐标
spp=as.data.frame(oo$species)###提取物种坐标
grp=as.data.frame(c(rep("a",4),rep("b",4),rep("c",4),rep("d",4)))###根据样方类型分组
colnames(grp)="group"
###以下开始作图
ggplot()+
geom_point(data=site,aes(x=PC1,y=PC2,shape=grp$group,fill=grp$group),size=4)+
scale_shape_manual(values = c(21:24))+
geom_segment(data=spp,aes(x=0,y=0,xend=PC1,yend=PC2),
arrow = arrow(angle = 22.5,length = unit(0.35,"cm"),
type="closed"),linetype=1,size=1,color="red")+
geom_text_repel(data=spp,aes(x=PC1,y=PC2),label=row.names(spp))+
geom_hline(yintercept=0,linetype=3,size=1)+
geom_vline(xintercept=0,linetype=3,size=1)+
labs(x=paste("PC1(", format(100 *oo$cont[[1]][2,1], digits=4), "%)", sep=""),
y=paste("PC2(", format(100 *oo$cont[[1]][2,2], digits=4), "%)", sep=""))+
guides(shape=guide_legend(title = NULL),fill=guide_legend(title = NULL))+
theme_bw()+theme(panel.grid = element_blank())
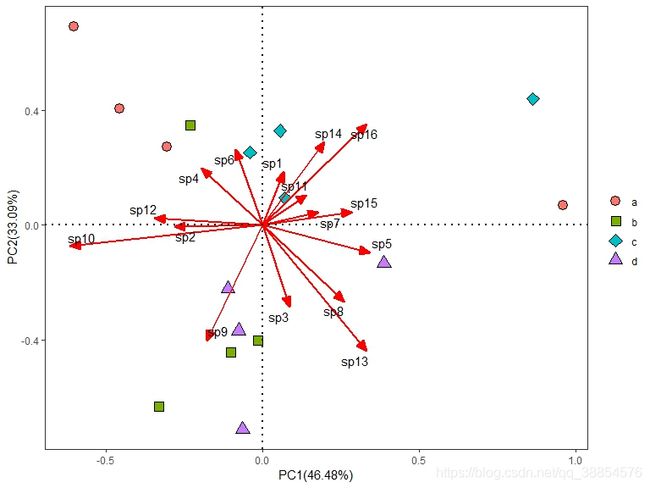
当样方坐标与物种坐标数值相差较大时,为了方便展示分析结果,我们可将样方或者物种的坐标数值扩大(或缩小),那么上面的代码就可达到这样的效果。当然,有比较方便的ggvegan包,但对于要求高的朋友来说,本文的代码将是更好的选择。对于其他排序分析,如主坐标分析、非度量多维尺度分析等分析,都可以用本文的思想来展现。
刚接触R的朋友,可能会因为R的“难”入门而选择较容易的CANOCO软件,当然后者也是生态环境领域的数据分析神器,但是,当我们想要个性化分析、个性化出图时,目前后者无法满足,R,应是首选。实验设计、实验过程、数据处理及分析、绘图、写作等是科研的必然过程,为促进相互进步、资源共享,我们创建了学术交流QQ群:335774366。欢迎有兴趣的朋友加入→指导。
声明:以上代码及观点,仅供参考。