python之机器学习sklearn(上)
这篇博客是python之机器学习sklearn的笔记,开始吧~
环境准备
先导入模块搭建好环境吧
import numpy as np
import pandas as pd #用于数据管理
from matplotlib import pyplot as plt
import seaborn as sns
sklearn内置数据集
内置了一些小型标准数据集可以直接用于学习sklearn中的各种算法
| 导入toy数据的方法 | 介绍 | 任务 |
|---|---|---|
| load_boston() | boston房价数据集 | 回归 |
| load_iris([return_x_y]) | 鸢尾花数据集 | 分类 |
| load_diabetes() | 糖尿病数据集 | 回归 |
| load_digits([n_class]) | 手写数据集 | 分类 |
| load_linnerud() | 运动和生理指标数据集 | 多元分析 |
| fetch_olivetti_faces() | Olivetti脸部图像数据集 | 降维 |
| fetch_20newsgroups() | 新闻分类数据集 | 分类 |
【小数据集可以直接调用,大数据集要在调用时程序自动下载(一次即可)】
以导入波士顿房价数据集为例

形成数据框

以手写数字数据集为例
手写数字数据集包括1797个0~9的手写数字数据,每个数字由8*8大小的矩阵构成,矩阵中值的范围是0-16,代表颜色的深度

前面已经从sklearn中导入了所有小数据集,所以这里可以直接用,如果你不怕麻烦也可以需要使用一个数据集就导入一个数据集
from sklearn.datasets import load_digits
sklearn基本操作
sklearn库一共分为6大部分,分别用于完成分类任务、回归任务、聚类任务、降维任务、模型选择以及数据预处理
分类任务
| 分类模型 | 加载模块 |
|---|---|
| 最近邻算法 | neighbors.NearestNeighbors |
| 支持向量机 | svm.SVC |
| 朴素贝叶斯 | naive_bayes.GaussianNB |
| 决策树 | tree.DecisionTreeClassifier |
| 集成方法 | ensemble.BaggingClassifier |
| 神经网络 | neural_network.MLPClassifier |
回归任务
| 回归模型 | 加载模块 |
|---|---|
| 岭回归 | linear_model.Ridge |
| Lasso回归 | linear_model.Lasso |
| 弹性回归 | linear_model.ElasticNet |
| 最小角回归 | linear_model.Lars |
| 贝叶斯回归 | linear_model.BayesianRidge |
| 逻辑回归 | linear_model.LogisticRegression |
| 多项式回归 | preprocessing.PolynomialFeatures |
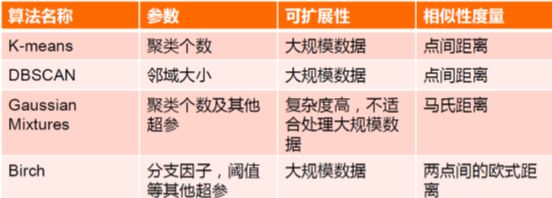
聚类任务
| 聚类方法 | 加载模块 |
|---|---|
| K-means | cluster.KMeans |
| AP聚类 | cluster.AffinityPropagation |
| 均值漂移 | cluster.MeanShift |
| 层次聚类 | cluster.AgglomerativeClustering |
| DBSCAN | cluster.DBSCAN |
| BIRCH | cluster.Birch |
| 谱聚类 | cluster.SpectralClustering |

降维任务
| 降维方法 | 加载模块 |
|---|---|
| 主成分分析 | decomposition.PCA |
| 截断SVD和LSA | decomposition.TruncatedSVD |
| 字典学习 | decomposition.SparseCoder |
| 因子分析 | decomposition.FactorAnalysis |
| 独立成分分析 | decomposition.FastlCA |
| 非负矩阵分解 | decomposition.NMF |
| LDA | decomposition.LatentDirichletAllocation |
降维是机器学习领域的一个重要研究内容,降维过程也可以被理解为对数据集的组成成分进行分解(decomposition)的过程,因此sklearn为降维模块命名为decomposition,在对降维算法调用需要使用sklearn.decomposition模块。

模型选择and数据预处理
- modelclass中基本通用的类方法:
 其中fit_transform()将fit和transform一起执行,方便挺多
其中fit_transform()将fit和transform一起执行,方便挺多 - modelclass中基本通用的类属性:
模型拟合前以下属性可能不存在
coef_:array,多因变量时为二维数组
intercept_:常数项
classes_:每个输出的类标签
n_classes_:int or list,类别数量
n_features_:int,特征数量
loss_:损失函数计算出来的当前损失值
n_iter_:迭代次数

总结一下基本顺序是:
- 首先传入数据
- 导入选用的模型
- fit数据集
- 调参
- 预测
- 评价模型
模型的保存(持久化)
可以直接使用通过python的pickle模块将训练好的模型保存为外部文件,但最好使用sklearn中的joblib模块进行操作。
from sklearn.externals import joblib
joblib.dump(模型,地址)
读入外部保存的模型文件
xxx = joblib.load(地址)
xxx.coef_
sklearn的数据预处理
1.数值型变量的标准化
数据标准化可以去除均数、离散程度量纲差异太大的影响。
减去均数:去除均数的影响
除以标准差:去除离散程度的影响
但是标准化对离群值的影响无能为力,其结果仍然受离群值的严重影响。
skleaan.preprocessing.scale(
X : {需要进行变化的数据矩阵}
axis = 0 (轴,=0按列汇总,=1按所有的数求均值、标准差进行行变化
with_mean = True (是否中心化数据移除均值)
with_std = True (是否均一化标准差)
copy = True (是否生成副本而不是替换原数据)
)

对整个矩阵统一进行标准化:axis = 1
即标准化用到的均值与标准差取整个矩阵所有元素的均值与标准差
boston_scaled.mean(axis = 0) #取名,名.mean(轴)均值
boston_scaled.std(axis = 0) #标准差
#array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
boston_scaled_all = preprocessing.scale(boston_df,axis=1) #将轴改成1
boston_scaled_all.mean(axis = 0)
boston_scaled_all.std(axis = 0)
boston_scaled_all.mean(),boston_scaled_all.std() #默认是全体的均值和标准差
preprocessing.scale(boston.target)#对单独某一列进行标准化
scale函数还可以对单独某一列进行标准化:
preprocessing.scale(boston.target)
2.在多个数据集上使用相同的标准化变换
class sklearn.preprocessing.StandardScaler(
copy = True (是否生成副本而不是替换原对象)
with_mean = True (该选项对稀疏矩阵无效)
with_std = True
StandardScaler类的方法:
inverse_transform(X[,copy]) 将数据进行逆变换
partial_fit(X[,y]) 在线计算数据特征用于后续拟合
fit(X[,y]) 计算数据特征用于后续拟合
transform(X[,y,copy]) 使用模型设定进行转换
fit_transform(X[,y]) 计算数据特征,并且进行转换
get_params([deep]) 获取模型的参数设定
set_params(**params) 设置模型参数
StandardScaler类的属性:
scale_ : ndarray,shape(n_features,)
mean_:array of floats with shape [n_features]
var_:array of floats with shape [n_features]
n_samples_seen_:int
将特征变量缩放至特定范围
常见的操作是将数据转换至0~1之间,也可以将每个特征的最大绝对值转换至指定数值大小(任然对离群值非常敏感)
- 放大方差极小的特征,使其在特征选择时能保留在模型中
- 聚类分析中常见的数据预处理方式之一
- 实现特征极小方差的稳健性,或者在稀疏矩阵中保留零元素
class sklearn.preprocessing.MinMaxScaler(feature_range = (0,1),copy = True)【将数据缩放至指定范围内】
class sklearn.preprocessing.MaxAbsScaler(copy = True)【将数据的最大值缩放至1】
4.数据的正则化
正则化(Normalization)/归一化/范数化是机器学习领域提出的基于向量空间模型上的一个转换,经常被使用在分类与聚类中
sklearn.preprocessing.normalize(
X,axis = 1,copy =True
norm = 'l2':'l1','l2',or 'max',
return_norm = False (是否返回所使用的范数)
分类聚类中,其中norm = ‘l2常用范数’:‘l1’不是1,是L
5.考虑异常值的标准化方法
稳健标准化:
将中位数和百分位数(默认使用四分位数间距)分别代替均数和标准差用于数据的标准化(更适合于已知有离群值的数据)
去除异常值的影响robust_scaler
调用RobustScaler类,可以得到想要的标准化数据
缺失值的填充
sklearn中的绝大部分模型都不能自动处理缺失值(树模型除外),必须进行预处理。
- 删除缺失值所在的整行或整列。代价是信息丢失
- 使用所在行或列中的平均值、中位数或者众数来填充缺失值,代价是引入偏差
使用Imputer
imp = preprocessing.Imputer()
imp.fit([[1,2],[np.nan,3],[7,8]]) #参数保留,像训练集将来作用到测试集
imp.statistics_
imp.transform([[np.nan,2],[6,np.nan]]) #将测试集的缺失值用刚刚得到的参数填补
#array([[4. , 2. ],
[6. , 4.33333333]])
生成多项式特征(交互项)
一般而言,建模时往往可以找到确实对模型改善有贡献的二次交互项,但三次以上的交互项则很少需要考虑。
class sklearn.preprocessing.PolynomialFeatures(
degree = 2 (希望计算的多项式的阶数)
interaction_only = False (是否只计算交互项,而不包括原变量的任何高次项)
include_bias = True (是否加入一个偏移量/常数项)
以波士顿数据集为例
自定义转换器
将任何一个已有的Python函数转化为sklearn中的转换器,用于在统一的流程中清理数据。
class sklearn.preprocessing.FunctionTransformer(
func = None (用于定义转换器的python函数)
inverse_func = None (用于逆转换函数)
validate = True (bool在调用函数前是否对数据做检查)
accept_sparse = False (boolean是否允许转换函数接受稀疏矩阵格式)
pass_y = False (bool转换函数是否会一并提交因变量y)
kw_args (dict转换函数使用的参数列表)
inv_kw_args (dict逆转换函数使用的参数列表)