TensorFlow搭建"简易"Wide and Deep 模型
标签:推荐算法
[TOC]
Wide & Deep 模型是谷歌在2016年发表的论文中所提到的模型。在论文中,谷歌将 LR 模型与 深度神经网络 结合在一起作为 Google Play 的推荐获得了一定的效果。
官方提供的 Wide & Deep 模型的(简称,WD 模型)教程 都是使用 TensorFlow (简称,TF )自带的函数来做的特征工程,并且模型也进行了封装,所以如果要简单验证这个模型的话,自己用tf直接搭建一个或许是一个更好的主意。
所以本文就向您展示了如何自己用 TF 搭建一个结构清晰,定制性更高的 WD 模型。
1.先让我们来看看wide_deep模型是如何工作的:
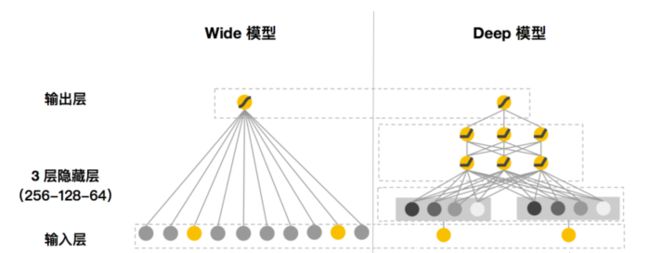
上图左边是wide模型,对于右边是deep模型。可见wide模型就是一个RL模型,而右边的deep网络隐藏层有三层,神经元个数分别为256,128,64。
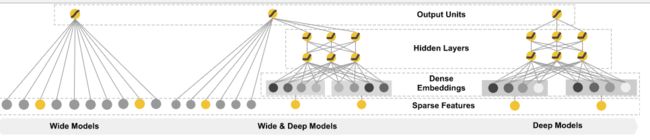
上面的图示谷歌教程里,可见最后将wide的输出和deep的输出进行相加。最后用一个Relu激活函数,然后输出最终预测。
我自己写了一个小小的demo,可以展示这个过程,思路还是很清晰的,下面我将用自己的demo来解释这个过程。
2. demo解析
outline:
我用了三个函数,分别为:
wide_model:来建立wide模型
deep_model: 来建立deep模型
build_w_d : 来结合上面二者进行预测与反向传播
1. wide_model函数解析
下面是我的代码,用的是TensorFlow框架:
我再代码内部已经给了一些注释,有一定解释作用
def wide_model(data) :
#得到数据的长度,即每个样例有多少个输入
len = np.shape(data)[1]
#随机初始化参数
tf.set_random_seed(1)
W = tf.get_variable("W" , [len , 1] , initializer = tf.contrib.layers.xavier_initializer())
b = tf.get_variable("b" , [1 , 1] , initializer = tf.zeros_initializer())
#前向传播:
Z = tf.add(tf.matmul(data , W) , b)
A = tf.nn.relu(Z) #这个Relu我不知道要不要用。。。
# 输出每个样本经过计算的值
output = tf.reshape(A, [-1, 1])
return output
#======分割线由于不要反向传播,这里wide就写完了============
值得注意的是:
1.我用的是随机初始化,但是我见过用修正方式初始化权重的,我不知道这个模型,用那种方式是不是会更好,所以这里可能会有错误。
2.对于前向传播完成后,是否需要用一个relu激活函数,我也没有查到什么确切的资料,这也是个问题。
2. deep_model函数解析
这里我只做了个demo,所以我直接用了和之前图中一样的隐藏层网络层数(3层),然后神经元节点数目,我还是用的参数形式表示,以便于扩展。
下面是我的代码:
def deep_model(data , hidden1 , hidden2 , hidden3) :
len = np.shape(data)[1]
#随机初始化参数
W1 = tf.get_variable("W1", [len , hidden1], initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable("b1", [hidden1 , 1], initializer=tf.zeros_initializer())
W2 = tf.get_variable("W2", [hidden1 , hidden2], initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.get_variable("b2", [hidden2 , 1], initializer=tf.zeros_initializer())
W3 = tf.get_variable("W3", [hidden2 , hidden3], initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.get_variable("b3", [hidden3 , 1], initializer=tf.zeros_initializer())
# 前向传播
Z1 = tf.add(tf.matmul(data, W1), b1) # Z1 = np.dot(W1, X) + b1
A1 = tf.nn.relu(Z1) # A1 = relu(Z1)
Z2 = tf.add(tf.matmul(A1, W2), b2) # Z2 = np.dot(W2, a1) + b2
A2 = tf.nn.relu(Z2) # A2 = relu(Z2)
Z3 = tf.add(tf.matmul(A2, W3), b3) # Z3 = np.dot(W3,Z2) + b3
output = tf.nn.relu(Z3) #这个Relu我不知道要不要用。。。
return output
问题:同样,,,这个最后的relu我不知道要不要用。
3. build_w_d函数解释
下面是代码:
def build_w_d(deep_input, wide_input, y):
dmodel = deep_model(deep_input, 256, 128, 64)
wmodel = wide_model(wide_input)
#初始化参数(就是类似于前面函数的b)
central_bias = tf.Variable([np.random.randn()], name="central_bias")
# 使用 LR 将两个模型组合在一起
dmodel_weight = tf.Variable(tf.truncated_normal([1, 1]), name="dmodel_weight")
wmodel_weight = tf.Variable(tf.truncated_normal([1, 1]), name="wmodel_weight")
#将wide和deep的输出结合起来
network = tf.add(tf.matmul(dmodel , dmodel_weight) , tf.matmul(wmodel, wmodel_weight))
prediction = tf.add(network, central_bias)
#计算cost函数
cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y , logits=prediction))
#反向传播,用了Adam优化
train_step = tf.train.AdamOptimizer(0.001).minimize(cost)
return train_step , cost , prediction
好了,结合起来就是这样,这展现了wide_deep模型的基本结构,当然,需要得到一个很厉害的,应用级的模型的话,还需要很多的优化与连接措施。
下面贴出几个参考资料:
https://www.tensorflow.org/tutorials/wide_and_deep
https://research.google.com/pubs/pub45413.html
https://research.googleblog.com/2016/06/wide-deep-learning-better-together-with.html