Google 机器学习术语表 Part 4 of 4
文章目录
-
- 1. 背景
- 19. R
-
- 19.1. 等级 (rank)
- 19.2. 评分者 (rater)
- 19.3. 召回率 (recall)
- 19.4. 修正线性单元 (ReLU, Rectified Linear Unit)
- 19.5. 回归模型 (regression model)
- 19.6. 正则化 (regularization)
- 19.7. 正则化率 (regularization rate)
- 19.8. 表示法 (representation)
- 19.9. 受试者工作特征曲线(receiver operating characteristic,简称 ROC 曲线)
- 19.10. 根目录 (root directory)
- 19.11. 均方根误差 (RMSE, Root Mean Squared Error)
- 19.12. 旋转不变性 (rotational invariance)
- 20. S
-
- 20.1. SavedModel
- 20.2. Saver
- 20.3. 缩放 (scaling)
- 20.4. scikit-learn
- 20.5. 半监督式学习 (semi-supervised learning)
- 20.6. 序列模型 (sequence model)
- 20.7. 会话 (tf.session)
- 20.8. S 型函数 (sigmoid function)
- 20.9. 大小不变性 (size invariance)
- 20.10. softmax
- 20.11. 稀疏特征 (sparse feature)
- 20.12. 稀疏表示法 (sparse representation)
- 20.13. 稀疏性 (sparsity)
- 20.14. 空间池化 (spatial pooling)
- 20.15. 平方合页损失函数 (squared hinge loss)
- 20.16. 平方损失函数 (squared loss)
- 20.17. 静态模型 (static model)
- 20.18. 平稳性 (stationarity)
- 20.19. 步 (step)
- 20.20. 步长 (step size)
- 20.21. 随机梯度下降法 (SGD, stochastic gradient descent)
- 20.22. 结构风险最小化 (SRM, structural risk minimization)
- 20.23. 步长 (stride)
- 20.24. 下采样 (subsampling)
- 20.25. 总结 (summary)
- 20.26. 监督式机器学习 (supervised machine learning)
- 20.27. 合成特征 (synthetic feature)
- 21. T
-
- 21.1. 目标 (target)
- 21.2. 时态数据 (temporal data)
- 21.3. 张量 (Tensor)
- 21.4. 张量处理单元 (TPU, Tensor Processing Unit)
- 21.5. 张量等级 (Tensor rank)
- 21.6. 张量形状 (Tensor shape)
- 21.7. 张量大小 (Tensor size)
- 21.8. TensorBoard
- 21.9. TensorFlow
- 21.10. TensorFlow Playground
- 21.11. TensorFlow Serving
- 21.12. 测试集 (test set)
- 21.13. tf.Example
- 21.14. 时间序列分析 (time series analysis)
- 21.15. 训练 (training)
- 21.16. 训练集 (training set)
- 21.17. 迁移学习 (transfer learning)
- 21.18. 平移不变性 (translational invariance)
- 21.19. 负例 (TN, true negative)
- 21.20. 正例 (TP, true positive)
- 21.21. 正例率(true positive rate, 简称 TP 率)
- 22. U
-
- 22.1. 无标签样本 (unlabeled example)
- 22.2. 非监督式机器学习 (unsupervised machine learning)
- 23. V
-
- 23.1. 验证集 (validation set)
- 24. W
-
- 24.1. 权重 (weight)
- 24.2. 宽度模型 (wide model)
1. 背景
Google出了一份机器学习术语表,列出了一般的机器学习术语和 TensorFlow 专用术语的定义,并且翻译成了中文,对理解机器学习中的术语很有帮助,于是我把它转载过来,方便学习和记录,这一篇是首字母R-W的内容。
原文链接:https://developers.google.cn/machine-learning/glossary/?hl=zh-CN
19. R
19.1. 等级 (rank)
机器学习中的一个多含义术语,可以理解为下列含义之一:
- 张量中的维数。例如,标量等级为 0,向量等级为 1,矩阵等级为 2。
- 在将类别从最高到最低进行排序的机器学习问题中,类别的顺序位置。例如,行为排序系统可以将狗狗的奖励从最高(牛排)到最低(枯萎的羽衣甘蓝)进行排序。
19.2. 评分者 (rater)
为样本提供标签的人。有时称为"注释者"。
19.3. 召回率 (recall)
一种分类模型指标,用于回答以下问题:在所有可能的正类别标签中,模型正确地识别出了多少个?即:
召回率 = 正 例 数 正 例 数 + 假 负 例 数 \text{召回率} = \frac{正例数}{正例数 + 假负例数} 召回率=正例数+假负例数正例数
19.4. 修正线性单元 (ReLU, Rectified Linear Unit)
一种激活函数,其规则如下:
- 如果输入为负数或 0,则输出 0。
- 如果输入为正数,则输出等于输入。
19.5. 回归模型 (regression model)
一种模型,能够输出连续的值(通常为浮点值)。请与分类模型进行比较,分类模型会输出离散值,例如"黄花菜"或"虎皮百合"。
19.6. 正则化 (regularization)
对模型复杂度的惩罚。正则化有助于防止出现过拟合,包含以下类型:
- L 1 L_1 L1 正则化
- L 2 L_2 L2 正则化
- 丢弃正则化
- 早停法(这不是正式的正则化方法,但可以有效限制过拟合)
19.7. 正则化率 (regularization rate)
一种标量值,以 lambda 表示,用于指定正则化函数的相对重要性。从下面简化的损失公式中可以看出正则化率的影响:
min ( 损失方程 + λ 正则化方程 ) \min(\text{损失方程} + \lambda \text{正则化方程}) min(损失方程+λ正则化方程)
提高正则化率可以减少过拟合,但可能会使模型的准确率降低。
19.8. 表示法 (representation)
将数据映射到实用特征的过程。
19.9. 受试者工作特征曲线(receiver operating characteristic,简称 ROC 曲线)
不同分类阈值下的正例率和假正例率构成的曲线。另请参阅曲线下面积。
19.10. 根目录 (root directory)
您指定的目录,用于托管多个模型的 TensorFlow 检查点和事件文件的子目录。
19.11. 均方根误差 (RMSE, Root Mean Squared Error)
均方误差的平方根。
19.12. 旋转不变性 (rotational invariance)
在图像分类问题中,即使图像的方向发生变化,算法也能成功地对图像进行分类。例如,无论网球拍朝上、侧向还是朝下放置,该算法仍然可以识别它。请注意,并非总是希望旋转不变;例如,倒置的"9"不应分类为"9"。
另请参阅平移不变性和大小不变性。
20. S
20.1. SavedModel
保存和恢复 TensorFlow 模型时建议使用的格式。SavedModel 是一种独立于语言且可恢复的序列化格式,使较高级别的系统和工具可以创建、使用和转换 TensorFlow 模型。
如需完整的详细信息,请参阅《TensorFlow 编程人员指南》中的保存和恢复。
20.2. Saver
一种 TensorFlow 对象,负责保存模型检查点。
20.3. 缩放 (scaling)
特征工程中的一种常用做法,是指对某个特征的值区间进行调整,使之与数据集中其他特征的值区间一致。例如,假设您希望数据集中所有浮点特征的值都位于 0 到 1 区间内,如果某个特征的值位于 0 到 500 区间内,您就可以通过将每个值除以 500 来缩放该特征。
另请参阅标准化。
20.4. scikit-learn
一个热门的开放源代码机器学习平台。请访问 www.scikit-learn.org。
20.5. 半监督式学习 (semi-supervised learning)
训练模型时采用的数据中,某些训练样本有标签,而其他样本则没有标签。半监督式学习采用的一种技术是推断无标签样本的标签,然后使用推断出的标签进行训练,以创建新模型。如果获得有标签样本需要高昂的成本,而无标签样本则有很多,那么半监督式学习将非常有用。
20.6. 序列模型 (sequence model)
一种模型,其输入具有序列依赖性。例如,根据之前观看过的一系列视频对观看的下一个视频进行预测。
20.7. 会话 (tf.session)
封装了 TensorFlow 运行时状态的对象,用于运行全部或部分图。在使用底层 TensorFlow API 时,您可以直接创建并管理一个或多个 tf.session 对象。在使用 Estimator API 时,Estimator 会为您创建会话对象。
20.8. S 型函数 (sigmoid function)
一种函数,可将逻辑回归输出或多项回归输出(对数几率)映射到概率,以返回介于 0 到 1 之间的值。S 型函数的公式如下:
y = 1 1 + e − σ y = \frac{1}{1 + e^{-\sigma}} y=1+e−σ1
在逻辑回归问题中, 非常简单:
σ = b + w 1 x 1 + w 2 x 2 + ⋯ + w n x n \sigma = b + w_1 x_1 + w_2 x_2 + \dots + w_n x_n σ=b+w1x1+w2x2+⋯+wnxn
换句话说,S 型函数可将 σ \sigma σ 转换为介于 0 到 1 之间的概率。
在某些神经网络中,S 型函数可作为激活函数使用。
20.9. 大小不变性 (size invariance)
在图像分类问题中,即使图像的大小发生变化,算法也能成功地对图像进行分类。例如,无论一只猫以 200 万像素还是 20 万像素呈现,该算法仍然可以识别它。请注意,即使是最好的图像分类算法,在大小不变性方面仍然会存在切实的限制。例如,对于仅以 20 像素呈现的猫图像,算法(或人)不可能正确对其进行分类。
另请参阅平移不变性和旋转不变性。
20.10. softmax
一种函数,可提供多类别分类模型中每个可能类别的概率。这些概率的总和正好为 1.0。例如,softmax 可能会得出某个图像是狗、猫和马的概率分别是 0.9、0.08 和 0.02。(也称为完整 softmax。)
与候选采样相对。
20.11. 稀疏特征 (sparse feature)
一种特征向量,其中的大多数值都为 0 或为空。例如,某个向量包含一个为 1 的值和一百万个为 0 的值,则该向量就属于稀疏向量。再举一个例子,搜索查询中的单词也可能属于稀疏特征 - 在某种指定语言中有很多可能的单词,但在某个指定的查询中仅包含其中几个。
与密集特征相对。
20.12. 稀疏表示法 (sparse representation)
一种张量表示法,仅存储非零元素。
例如,英语中包含约一百万个单词。表示一个英语句子中所用单词的数量,考虑以下两种方式:
- 要采用密集表示法来表示此句子,则必须为所有一百万个单元格设置一个整数,然后在大部分单元格中放入 0,在少数单元格中放入一个非常小的整数。
- 要采用稀疏表示法来表示此句子,则仅存储象征句子中实际存在的单词的单元格。因此,如果句子只包含 20 个独一无二的单词,那么该句子的稀疏表示法将仅在 20 个单元格中存储一个整数。
例如,假设以两种方式来表示句子"Dogs wag tails."。如下表所示,密集表示法将使用约一百万个单元格;稀疏表示法则只使用 3 个单元格:
密集表示法 \text{密集表示法} 密集表示法
| 单元格编号 | 单词 | 出现次数 |
|---|---|---|
| 0 | a | 0 |
| 1 | aardvark | 0 |
| 2 | aargh | 0 |
| 3 | aarti | 0 |
| … 出现次数为 0 的另外 140391 个单词 | ||
| 140395 | dogs | 1 |
| … 出现次数为 0 的 633062 个单词 | ||
| 773458 | tails | 1 |
| … 出现次数为 0 的 189136 个单词 | ||
| 962594 | wag | 1 |
| … 出现次数为 0 的很多其他单词 |
稀疏表示法 \text{稀疏表示法} 稀疏表示法
| 单元格编号 | 单词 | 出现次数 |
|---|---|---|
| 140395 | dogs | 1 |
| 773458 | tails | 1 |
| 962594 | wag | 1 |
20.13. 稀疏性 (sparsity)
向量或矩阵中设置为 0(或空)的元素数除以该向量或矩阵中的条目总数。以一个 10x10 矩阵(其中 98 个单元格都包含 0)为例。稀疏性的计算方法如下:
稀疏性 = 98 100 = 0.98 \text{稀疏性} = \frac{98}{100} = 0.98 稀疏性=10098=0.98
特征稀疏性是指特征向量的稀疏性;模型稀疏性是指模型权重的稀疏性。
20.14. 空间池化 (spatial pooling)
请参阅池化。
20.15. 平方合页损失函数 (squared hinge loss)
合页损失函数的平方。与常规合页损失函数相比,平方合页损失函数对离群值的惩罚更严厉。
20.16. 平方损失函数 (squared loss)
在线性回归中使用的损失函数(也称为 L 2 L_2 L2 损失函数)。该函数可计算模型为有标签样本预测的值和标签的实际值之差的平方。由于取平方值,因此该损失函数会放大不佳预测的影响。也就是说,与 L 1 L_1 L1 损失函数相比,平方损失函数对离群值的反应更强烈。
20.17. 静态模型 (static model)
离线训练的一种模型。
20.18. 平稳性 (stationarity)
数据集中数据的一种属性,表示数据分布在一个或多个维度保持不变。这种维度最常见的是时间,即表明平稳性的数据不随时间而变化。例如,从 9 月到 12 月,表明平稳性的数据没有发生变化。
20.19. 步 (step)
对一个批次的向前和向后评估。
20.20. 步长 (step size)
与学习速率的含义相同。
20.21. 随机梯度下降法 (SGD, stochastic gradient descent)
批次大小为 1 的一种梯度下降法。换句话说,SGD 依赖于从数据集中随机均匀选择的单个样本来计算每步的梯度估算值。
20.22. 结构风险最小化 (SRM, structural risk minimization)
一种算法,用于平衡以下两个目标:
- 期望构建最具预测性的模型(例如损失最低)。
- 期望使模型尽可能简单(例如强大的正则化)。
例如,旨在将基于训练集的损失和正则化降至最低的函数就是一种结构风险最小化算法。
如需更多信息,请参阅 http://www.svms.org/srm/。
与经验风险最小化相对。
20.23. 步长 (stride)
在卷积运算或池化中,下一个系列的输入切片的每个维度中的增量。例如,下面的动画演示了卷积运算过程中的一个 (1,1) 步长。因此,下一个输入切片是从上一个输入切片向右移动一个步长的位置开始。当运算到达右侧边缘时,下一个切片将回到最左边,但是下移一个位置。
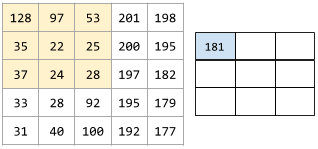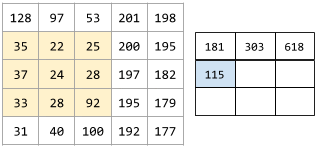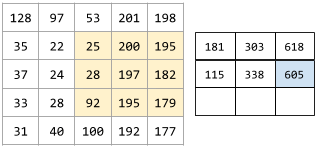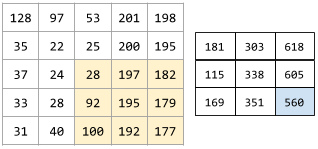
前面的示例演示了一个二维步长。如果输入矩阵为三维,那么步长也将是三维。
20.24. 下采样 (subsampling)
请参阅池化。
20.25. 总结 (summary)
在 TensorFlow 中的某一步计算出的一个值或一组值,通常用于在训练期间跟踪模型指标。
20.26. 监督式机器学习 (supervised machine learning)
根据输入数据及其对应的标签来训练模型。监督式机器学习类似于学生通过研究一系列问题及其对应的答案来学习某个主题。在掌握了问题和答案之间的对应关系后,学生便可以回答关于同一主题的新问题(以前从未见过的问题)。请与非监督式机器学习进行比较。
20.27. 合成特征 (synthetic feature)
一种特征,不在输入特征之列,而是从一个或多个输入特征衍生而来。合成特征包括以下类型:
- 对连续特征进行分桶,以分为多个区间分箱。
- 将一个特征值与其他特征值或其本身相乘(或相除)。
- 创建一个特征组合。
仅通过标准化或缩放创建的特征不属于合成特征。
21. T
21.1. 目标 (target)
与标签的含义相同。
21.2. 时态数据 (temporal data)
在不同时间点记录的数据。例如,记录的一年中每一天的冬外套销量就属于时态数据。
21.3. 张量 (Tensor)
TensorFlow 程序中的主要数据结构。张量是 N 维(其中 N 可能非常大)数据结构,最常见的是标量、向量或矩阵。张量的元素可以包含整数值、浮点值或字符串值。
21.4. 张量处理单元 (TPU, Tensor Processing Unit)
一种 ASIC(应用专用集成电路),用于优化 TensorFlow 程序的性能。
21.5. 张量等级 (Tensor rank)
请参阅等级。
21.6. 张量形状 (Tensor shape)
张量在各种维度中包含的元素数。例如,张量 [5, 10] 在一个维度中的形状为 5,在另一个维度中的形状为 10。
21.7. 张量大小 (Tensor size)
张量包含的标量总数。例如,张量 [5, 10] 的大小为 50。
21.8. TensorBoard
一个信息中心,用于显示在执行一个或多个 TensorFlow 程序期间保存的摘要信息。
21.9. TensorFlow
一个大型的分布式机器学习平台。该术语还指 TensorFlow 堆栈中的基本 API 层,该层支持对数据流图进行一般计算。
虽然 TensorFlow 主要应用于机器学习领域,但也可用于需要使用数据流图进行数值计算的非机器学习任务。
21.10. TensorFlow Playground
一款用于直观呈现不同的超参数对模型(主要是神经网络)训练的影响的程序。要试用 TensorFlow Playground,请前往 http://playground.tensorflow.org。
21.11. TensorFlow Serving
一个平台,用于将训练过的模型部署到生产环境。
21.12. 测试集 (test set)
数据集的子集,用于在模型经由验证集的初步验证之后测试模型。
与训练集和验证集相对。
21.13. tf.Example
一种标准协议缓冲区,旨在描述用于机器学习模型训练或推断的输入数据。
21.14. 时间序列分析 (time series analysis)
机器学习和统计学的一个子领域,旨在分析时态数据。很多类型的机器学习问题都需要时间序列分析,其中包括分类、聚类、预测和异常检测。例如,您可以利用时间序列分析根据历史销量数据预测未来每月的冬外套销量。
21.15. 训练 (training)
确定构成模型的理想参数的过程。
21.16. 训练集 (training set)
数据集的子集,用于训练模型。
与验证集和测试集相对。
21.17. 迁移学习 (transfer learning)
将信息从一个机器学习任务迁移到另一个机器学习任务。例如,在多任务学习中,一个模型可以完成多项任务,例如针对不同任务具有不同输出节点的深度模型。迁移学习可能涉及将知识从较简单任务的解决方案迁移到较复杂的任务,或者将知识从数据较多的任务迁移到数据较少的任务。
大多数机器学习系统都只能完成一项任务。迁移学习是迈向人工智能的一小步;在人工智能中,单个程序可以完成多项任务。
21.18. 平移不变性 (translational invariance)
在图像分类问题中,即使图像中对象的位置发生变化,算法也能成功对图像进行分类。例如,无论一只狗位于画面正中央还是画面左侧,该算法仍然可以识别它。
另请参阅大小不变性和旋转不变性。
21.19. 负例 (TN, true negative)
被模型正确地预测为负类别的样本。例如,模型推断出某封电子邮件不是垃圾邮件,而该电子邮件确实不是垃圾邮件。
21.20. 正例 (TP, true positive)
被模型正确地预测为正类别的样本。例如,模型推断出某封电子邮件是垃圾邮件,而该电子邮件确实是垃圾邮件。
21.21. 正例率(true positive rate, 简称 TP 率)
与召回率的含义相同,即:
正例率 = 正 例 数 正 例 数 + 假 负 例 数 \text{正例率} = \frac{正例数}{正例数 + 假负例数} 正例率=正例数+假负例数正例数
正例率是 ROC 曲线的 y 轴。
22. U
22.1. 无标签样本 (unlabeled example)
包含特征但没有标签的样本。无标签样本是用于进行推断的输入内容。在半监督式和非监督式学习中,在训练期间会使用无标签样本。
22.2. 非监督式机器学习 (unsupervised machine learning)
训练模型,以找出数据集(通常是无标签数据集)中的规律。
非监督式机器学习最常见的用途是将数据分为不同的聚类,使相似的样本位于同一组中。例如,非监督式机器学习算法可以根据音乐的各种属性将歌曲分为不同的聚类。所得聚类可以作为其他机器学习算法(例如音乐推荐服务)的输入。在很难获取真标签的领域,聚类可能会非常有用。例如,在反滥用和反欺诈等领域,聚类有助于人们更好地了解相关数据。
非监督式机器学习的另一个例子是主成分分析 (PCA)。例如,通过对包含数百万购物车中物品的数据集进行主成分分析,可能会发现有柠檬的购物车中往往也有抗酸药。
请与监督式机器学习进行比较。
23. V
23.1. 验证集 (validation set)
数据集的一个子集,从训练集分离而来,用于调整超参数。
与训练集和测试集相对。
24. W
24.1. 权重 (weight)
线性模型中特征的系数,或深度网络中的边。训练线性模型的目标是确定每个特征的理想权重。如果权重为 0,则相应的特征对模型来说没有任何贡献。
24.2. 宽度模型 (wide model)
一种线性模型,通常有很多稀疏输入特征。我们之所以称之为"宽度模型",是因为这是一种特殊类型的神经网络,其大量输入均直接与输出节点相连。与深度模型相比,宽度模型通常更易于调试和检查。虽然宽度模型无法通过隐藏层来表示非线性关系,但可以利用特征组合、分桶等转换以不同的方式为非线性关系建模。
与深度模型相对。
联系邮箱:[email protected]
CSDN:https://me.csdn.net/qq_41729780
知乎:https://zhuanlan.zhihu.com/c_1225417532351741952
公众号:复杂网络与机器学习
欢迎关注/转载,有问题欢迎通过邮箱交流。
