Triple Adversarial Learning for Influence based PoisoningAttack in Recommender Systems
摘要:推荐系统作为解决信息超载问题的一种重要手段,在电子商务、广告等多个领域得到了广泛的应用。然而,最近的研究表明,推荐系统很容易受到中毒攻击;也就是说,在推荐系统中注入一组精心设计的用户档案会严重影响推荐质量。目的(从先令攻击发展到基于优化的攻击,但在大多数攻击中生成的数据的不可感知性和危害是难以平衡的)为此,我们提出了一种基于影响的中毒攻击(三重对抗性中毒攻击),这是一种灵活的端到端中毒框架,可以生成不显著和有害的用户档案。具体来说,在考虑到输入噪声的情况下,试验攻击通过对生成器、鉴别器和影响模块的三重对抗性学习,生成恶意用户。此外,为了为试验攻击训练提供可靠的影响,我们探索了一种新的近似方法来估计每个假用户的影响。通过理论分析,证明了在执行有效攻击的前提下,试验攻击的分布近似于真实用户的评级分布。这个属性允许注入的用户以一种简单的方式进行攻击。在三个真实数据集上的实验表明,试验攻击的攻击性能优于最先进的攻击,并且生成的假轮廓比基线更难检测。
1 介绍
推荐系统容易受到中毒攻击,即在推荐系统中注入少量设计良好的虚假用户,很容易欺骗推荐模型。一方面,这种脆弱性是无可辩驳的,鼓励研究人员学习和探索模型的鲁棒性。另一方面,不同系统中的许多商家都有很好的动机去利用数据中毒攻击来推广他们的产品或降低他们的竞争对手的产品。例如,索尼影业制作了一些通过伪造电影评论而被广泛推荐的特定电影1。因此,从学术研究和现实实践的角度来看,非常需要对推荐系统的数据中毒攻击进行研究,为开发有效的防御方法提供关键的见解和策略。
复杂的中毒攻击方法不仅应有效地实现攻击目标,而且应以非显着的方式起作用 [12,28]。大多数现有的中毒攻击方法都集中在优化定义的攻击对象 [13,22]; 但是,生成的中毒配置文件通常缺乏多样性,并且严重偏离正常用户的数据 [7]。这一缺陷导致中毒攻击很容易被防御工具或机制检测到 [7,26]。尽管先令攻击利用统计信息生成更接近真实用户的用户,但它们没有得到理论分析,也无法优化具体模型,这显著削弱了攻击的破坏性 [32]。
鉴于现有攻击的不足,最近的一些作品 [9,25] 利用生成对抗网络 (GAN) 对数据分布进行建模 [3,8,15,18,444],并考虑使用GAN的生成能力来产生恶意用户。例如,Christakopoulou等人 [9] 使用DCGAN生成 “真实” 用户,然后根据特定的攻击意图对其进行修补。这样的逐步处理主要集中在第二优化阶段,在最坏的情况下,它会退化到传统的基于模型的优化攻击。林等 [25] 将先令损失纳入发电机,但本质上仍是先令攻击,攻击性能令人难以保证。
为了解决上述挑战,我们提出了三重对抗学习,以共同攻击优化和GAN,以生成有害且晦涩的中毒数据。然而,评估用户对攻击的奖励是具有挑战性的。一种简单的方法是重新训练受污染的数据集,然后评估攻击性能。这种方法需要推荐模型在每个GAN训练时期进行多次重新训练,这在计算上是不可行的。这就是为什么当前基于GAN的攻击仅限于添加与模型无关的先令损失的原因 [25]。受影响函数在跟踪训练样本对决策影响的效率 [19] 的启发,我们提出了一种计算中毒用户攻击影响的近似方法,避免了耗时的重新训练。此外,我们使用神经网络将影响力建模为影响力模块,并将其与GAN集成,以开发基于影响力的中毒攻击 (TrialAttack) 的三重对抗学习。与三个玩家玩minimax游戏的TripleGAN [8] 类似,TrialAttack允许生成器,鉴别器和影响力模块通过三重对抗机制相互竞争。通过理论和实验分析,我们证实了TrialAttack可以生成非显着且有效的中毒数据,从而实现了攻击目标。
总而言之,我们工作的主要贡献如下。
• 我们为推荐系统中的中毒攻击提出了一个灵活的端到端框架TrialAttack。通过三重对抗性学习,TrialAttack可以有效平衡生成用户的不可感知性和危害性。此外,与现有的模型相关攻击相比,我们的框架可以更有效地生成假用户。我们从理论上证明,在有效攻击的前提下,以TrialAttack为特征的分布可以近似于真实分布。该属性允许假用户不显眼地注入,显著增加了防御难度。
• 在TrialAttack中,我们提供了一种新的近似方法来估计中毒数据对攻击目标的影响。给定任何用户,它可以有效地评估用户对推荐器系统的损害。
• 我们评估三个真实世界数据集的TrialAttack。实验结果表明,我们的攻击优于最先进的方法,并且与基线相比,生成的假用户更难检测。
2相关工作
近年来,人们对中毒攻击、攻击检测和推荐系统鲁棒性进行了深入研究 [28]。
中毒攻击: 早期的先令攻击,如平均攻击 [28] 和乐队攻击 [4],只是基于类似用户有相似兴趣的事实,没有优化具体的模型,使得攻击的伤害不令人满意。2016年,Li等人 [22] 提出了基于因式分解的协同推荐的中毒攻击,通过最小化攻击目标来实现完整性攻击和可用性攻击。它为后续基于模型的攻击 [12,13,30,34,36] 的研究奠定了基础。Yang等 [34] 将攻击建模为约束线性优化问题,并注入有限的假同访以欺骗推荐系统。Fang等人 [13] 攻击了基于图的推荐系统,将中毒轮廓转化为最小化问题,并使用投影梯度下降来解决它。TNA [12] 通过选择和评估一部分有影响力的用户来实现卓越的性能。考虑到恶意用户往往不同于正常数据,[9,25] 利用GANs来研究真实用户的分布,以生成难以检测的假用户,[11] 从不同的域获得配置文件来执行攻击。最近,将攻击轨迹建模为马尔可夫决策过程,并使用强化学习来攻击已逐渐引起人们的注意 [30,36]。
攻击检测: 传统的检测方法 [4,27] 主要从评级矩阵中提取特征来判断其是否为恶意用户。但是,由于数据的不平衡和不足,这些方法无法获得足够令人满意的结果。Aktukmak等 [2] 建立了检测恶意用户的概率模型。边界-SMOTE方法可以解决数据不平衡,并进一步微调目标项目的检测结果 [40]。Zhang等 [38] 提出了标签传播的方法来传播已知的恶意用户标签。此外,一段时间监视数据流是合理的 [37,39]。
推荐系统的鲁棒性: 最近的研究表明,对抗示例不是错误,而是有意义的数据特征,容易被模型忽略 [17]。因此,当前的工作主要集中在对抗性训练上,希望提高推荐算法对数据变化的容忍度 [6,16,31,35]。Deldzoo等 [10] 利用回归模型分析了URM数据特征与协同过滤的脆弱性之间的关系。
3问题定义
3.1威胁模型
攻击目标: 根据攻击的效果,中毒攻击可分为升级攻击,降级攻击和可用性攻击 [28]。其中,提升攻击和降级攻击旨在提升或降级目标项目的推荐频率 [28],可用性攻击旨在最大化未看到项目的预测误差 [22],从而降低对系统的信任。拟议的TrialAttack可以通过设计不同的攻击目标来有效地执行这些攻击。为简单起见,我们在本文中重点介绍促销攻击。
攻击知识: 我们首先考虑大多数现有作品 [9,12,13,22,25] 所关心的全知识攻击。在全知性攻击中,攻击者可以捕获所有用户的历史行为,包括产品浏览记录或评级 (例如,攻击者可以从地下市场、内部员工获得)。此外,攻击者知道推荐器系统的算法和参数。尽管许多现实世界的推荐者都是黑匣子,但一些系统仍然揭示了他们的推荐算法,例如,亚马逊 [29] 和Netflix [14] 已经报告了推荐算法。更重要的是,它为防御提供了最坏的情况假设,为攻击和捍卫许多真正的推荐者揭示了重要的见解和发现。因此,实际上需要调查全知识攻击。
其次,我们研究更实用的部分知识攻击。在这种情况下,只有部分历史行为暴露给攻击者,并且攻击者只知道推荐器系统的类型,而无法捕获内部参数。它的关键思想是通过估计目标模型将这种类型的攻击转变为全知识攻击。具体来说,假设目标模型的参数是未知的,攻击者使用web爬虫获得的部分数据来训练一个本地模拟器,该模拟器使用与目标模型相同的算法,但具有攻击者定义的参数。此时,本地模拟器是攻击者的白盒。相应地,攻击者可以基于本地模拟器执行全知识攻击以生成假用户,并将这些本地生成的用户注入到目标模型中以执行攻击。
攻击能力: 理论上,攻击者拥有的权限越高,目标模型就越容易受到攻击。然而,太多的假用户注射是无法操作的,并且很容易被检测程序感知 [38,40]。因此,我们限制攻击者在推荐系统中注入多达 的假用户。
3.2中毒攻击: 一个双层优化问题目前大部分的工作仍然集中在启发式驱动的先令攻击上,而对基于优化的攻击的研究略有不足。一个艰巨的挑战是它需要解决一个双层优化问题 [32]:
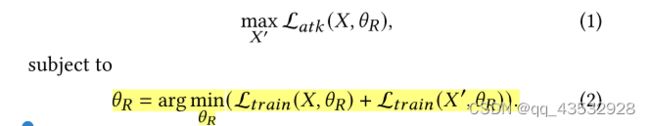
(假用户和真用户分别计算损失)
这里的 ∈ R × 是当前观察到的评级矩阵,其中 , 是用户 给项目 的评级, 是正常用户的数量, 是项目的数量。 ′ ∈ R ′ × 是我们需要求解的假用户的评级矩阵; 表示推荐器模型的参数。L (,) 是攻击的目标函数。对于论文中的推广攻击,我们希望目标条目出现在尽可能多的用户的top- 推荐列表中,因此我们定义L (,) 如下:
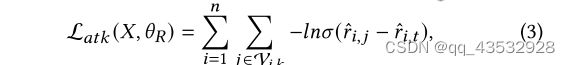
其中 () = 1/(1 − ),V , 为用户 的top- 推荐列表, 为目标项。这里V , 在求解过程中动态变化。这意味着在优化的某个阶段,如果 ∈ V ,,∈ , − ∈ ,> 0,那么目标项 将在top- 推荐列表中。再者,若损失L 较大,则目标物品 将倾向于持有较高的等级。
但是,考虑到双层的情况,该模型需要在中毒后重新训练,这将导致基于当前的优化解决方案 只是最优解的近似值。此外,大多数优化方法使用可微目标的梯度或其他矩在离散数据的邻域中搜索 [41]。对于梯度不确定的离散评级,无疑会增加优化的难度。因此,类似于 [12],我们对用户项目评级进行了放松操作。假设离散评级 , ∈ {0,1,...,},我们将其松弛为 [0,] 的连续变量。生成连续的用户评分后,我们使用投影运算符将其剪切为rational离散评分。
4基于影响的攻击
4.1的三重对抗学习概述
在本文中,我们提出了一种基于影响的中毒攻击的三重对抗学习 (TrialAttack),它在GAN中包含了攻击影响模块。受到TripleGAN [8] 的启发,提议的TrialAttack将传统的GAN扩展到三人游戏: 生成器 、鉴别器 和影响模块 。具体框架如图1所示,主要包括三个组成部分:
• 影响模块: 一方面,影响模块要对产生的用户的破坏力进行评估,引导生成器产生影响尽可能大的用户。为此,我们提出了一种新的求解器来近似假冒用户的攻击影响。另一方面,影响力可以被视为用户的潜在特征,并用作鉴别器的输入。因此,它旨在使预测的影响真实而不被鉴别器检测到。
• 生成器: 给定输入噪声 ,生成器专用于生成具有尽可能大的攻击影响的接近真实的用户配置文件 ∈ R ,其中 代表项目 的评级。为了减轻其学习压力,我们设计了一种多样化的噪声采样来产生输入噪声 .
鉴别器: 鉴别器应该专门用于区分生成的剖面和真实的剖面。除了用户个人资料之外,相应的影响力也是判断的关键因素。因此,当且仅当用户配置文件和影响力都是真实的时,鉴别器才预测真实。在这里,我们将计算出的影响视为真实,将预测的影响视为假。
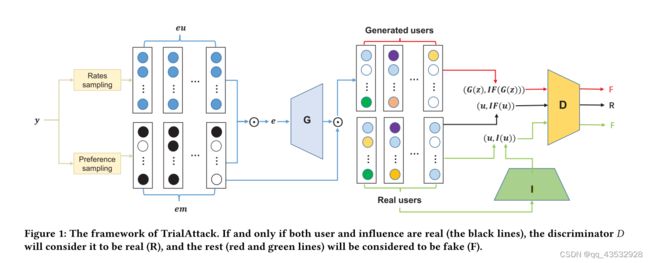
最近,一些研究 [9,11,25] 也提出了生成难以察觉的中毒概况,但我们的工作与它们完全不同。[11] 中的中毒用户是不同领域的真实用户; 相比之下,TrialAttack通过类似GAN的对抗结构生成假用户,而不依赖于其他领域数据集。对于也使用生成网络的 [9,25],他们利用了无法保证攻击性能的传统GAN结构,并且我们的TrialAttack结合了影响模块来生成现实的用户,同时最大化攻击伤害。
4.2影响模块
4.2.1在推荐系统中的影响。
了解提高或扰动训练样本对测试一下样本的影响最现实的想法是重新训练改变的数据集以进行效果估计。但是,在大数据时代,重新训练海量数据是不切实际的。在这一点上,影响函数 [19,20] 提供了一个有效的解决方案。
对于训练集中的一个样本 ,如果用一个小的值 上加权,改变后的参数 ∈ , = arg min ∈ Θ 1 Í = 1 L(,) L(,),其中L为模型的训练损失。然后根据 [19],加码对测试一下样本 的影响函数可以定义如下:
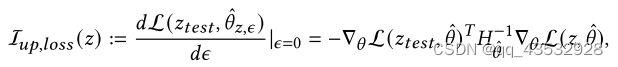
影响:扰动的改变能给参数带来多大的变化,也就是微分
其中 ˆ: = 1 Í = 1 ∇2 L(, ˆ ˆ) 是训练损失的Hessian矩阵。此外,考虑在样本中添加一个小扰动 的场景,对样本 的影响函数可以定义为:
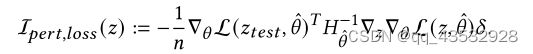
具体的证明可以在 [19] 中找到。
通过影响函数估计模型振荡可以用作评估攻击效果的有效工具。最近有少数相关作品 [12,36] 利用影响力毒害推荐系统。他们评估正常用户 [12] 或项目 [36] 对建议的影响。由于此类用户和物品客观地存在于系统中,因此可以直接应用旨在估计训练样本影响力的影响函数。
与他们的研究对象不同,我们希望计算一个从未出现过的恶意用户 的破坏,因此简单的增加或干扰用户是不可行的。为了解决这个问题,我们将毒害用户的操作分解为两个阶段 :( 1) 选择现有用户 并将其添加到数据集中; (2) 干扰添加的用户 与假用户 ' 相同。图2示出了一个示例,因此,中毒用户的影响将是这两个阶段的总和:
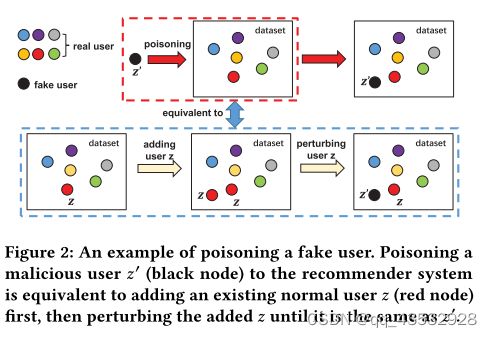
![]()
首先,对于一个由 用户组成的系统,每个训练用户的权重为1 /,因此添加一个现有用户相当于将这个用户的权重提高了 ≈ 1 /。特别是,通过计算对攻击目标L (,) 损失的影响。3,我们可以线性近似增加一个训练用户 的影响I ,::
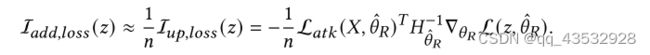
第二,扰乱新加入的用户 ,使其与中毒用户 ′ 相同。因此,摄动 ( ↦↦→ ′) 的大小应为 = ′ − ,则摄动I , () 的影响如下:

综上所述,我们可以近似计算任何假用户 ′ 的攻击伤害 (也适用于普通用户):

要满足影响函数的线性假设 [19],所选用户 应尽可能类似于 ′。因此,对于一个候选假用户 ′,理想情况下,它需要遍历整个数据集,找到一个与其相似的用户,然后计算影响力I ( ′)。尽管隐式Hessian-vector products (IHVP) [1] 可以有效地近似 − 1 ˆ,但在最坏的情况下,基于MF的推荐系统需要 ( ) 时间,其中, 是IHVP的迭代次数 (可能很大), = 是模型参数的总维。为了高效计算,我们只选择一个用户 ,该用户期望接近所有可行的假用户。
命题4.1.
在目标项目为 的推广攻击中,假设 ( ′) 是假用户的分布, ∈ R ,每一个 代表对项目 的评分模式,∈ ∈ {0,} ,维度 为 , 其他为0,则 = arg min ′ ~ ( ′) ∥ ′ − ∥ 0 = Π( et),其中 Π() 将每个 投影到合理的离散评级。
证明在附录a.1中。因此,我们直接注入用户 ,然后重新训练推荐系统。这样的设计避免了对ofI 、 () 的评估,减少了对 () 的时间。最后,给出了本文使用的中毒用户 '的影响
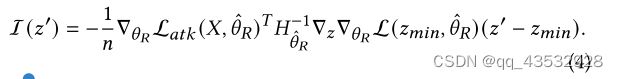
命题4.2.
假设 ( ′) 为用户的分布; 用户 ′ 的影响误差为 ( ′,) 选择用户 时。如果扰动 = ′ − → 0,则 ′ ~ ( ′) ( ( ′, )) ≤ ′ ~ ( ′) ( ( ′,))。
证明在附录a.1中。它告诉我们,当扰动最小时,选择 的影响估计误差并不比从原始数据集中选择的用户差。
4.2.2影响模型
基于影响越大,攻击收益越高的事实,我们利用公式4中定义的攻击影响。进行生成器产生有影响力的用户。在这里,我们利用神经网络将影响建模为影响模型,并将其与GAN结合。这种设计允许生成器从影响模型接收反馈,以进行端到端训练。因此,该模块对影响力的预测应准确真实,为生成器训练提供可靠的保证。
通过采用标准的监督学习可以保证准确性。在每个时期,我们随机抽取一组真实用户 ~ (),然后最小化真实影响力 (由式4计算) 与预测影响力 () 之间的差距:
![]()
为了保证现实,影响模型可以通过鉴别器的反馈来修正其参数,并试图混淆鉴别器以为预测的影响是真实的 ((,()) 接近于1):

4.3生成器
生成器专门用于生成非显著和恶意中毒用户。不幸的是,推荐系统中的离散数据给生成器创建用户配置文件带来了严峻的挑战
:( 1) 对于大量的项目,要具体了解每个项目的偏好并不容易 [5]。
(2) 因模式崩溃而产生的用户多样性不足 [8]。即使假用户具有攻击性,也很容易被发现,因为多样性低 [7,26]。
针对这些挑战,我们提出了一种多样化的噪声采样,以生成发生器的输入噪声 ∈ R ,其中 是给予项目 的评级。多样化的噪声采样主要包括等级采样和偏好采样,如图1的左部分所示。
具体过程如下 :
( 1) 使用K-means算法将所有真实用户聚类为不同的组。
(2) 我们使用等级采样来生成初始噪声 ∈ R ,其中 是从项目 的评分分布中采样的。
(生成器的输入噪声∈R,其中是给第项的评级 噪声采样用了两种:额定采样和偏好采样噪声)
(3) 由于用户对所有项目进行评分是不切实际的,因此我们使用偏好抽样来选择用户可能对其进行评分的项目。这里我们生成一个指标向量 ∈ {0,1} ,用于指定用户选择项i ( = 1) 与否 ( = 0)。具体来说,首先,我们随机选择一个群组j,然后将被选中的条目数 Í set设为群组 中每个用户的平均评分数,条目 被选中的概率为 ( = 1) = Í , ,,其中 , 为group组中项目 的平均评分。此外,我们为目标项 设置 = 1。
(4) 我们只关注偏好抽样所选择的项目,因此最终的噪声 = ⊙ ,其中 ⊙ 是按元素乘法 (注意生成的用户也只关心这些偏好项目)。一方面,多样化的噪声采样使生成器可以专注于可能被评级的低维项目,从而减轻了学习压力。另一方面,可以通过这样的一系列操作 (例如,聚类) 来保证多样性。
解决上述挑战使我们专注于生成用户。首先,生成器需要伪装生成的用户,以便鉴别器将其误认为是真实的:

此外,生成的用户应该是恶意和攻击性的。基于能量密度和攻击损失的强相关性 [19],我们将影响模块的预测反馈作为攻击损失L ,然后引导生成器产生影响大的用户:

最后,为了防止学习分布因合并攻击损失而偏离实际分布,我们将重建损失L integrate integrate集成到生成器中。由于输入噪声是从真实分布中采样的,因此重建损失有利于生成接近现实的评级:
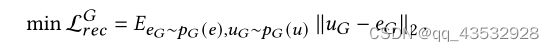
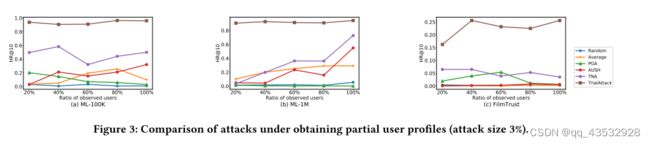
4.4鉴别器、
鉴别器致力于区分生成的用户和真实用户,以避免被生成器和影响模块欺骗。只有当输入用户和影响力是真实的时,鉴别器才会将其视为真实的。因此,判别器的对抗性损失定义如下:

综上所述,TrialAttack中的效用 (,,) 可以被公式化为一个三方的minimax博弈:
![]()
TrialAttack的训练过程如Alg1所示。训练完成后,我们首先通过多样化的噪声采样对 ( > ′) 噪声进行采样。然后我们将它们输入到生成器中,以获取恶意用户配置文件,同时通过影响模块获取其影响。最后,使用组级抽样 :( 1) 根据每个组的用户比例选择一个组,以及 (2) 选择该组中最有影响力的用户。重复该过程,直到选择了 '用户。

值得一提的是,虽然本文主要关注推广攻击,但其他攻击也可以通过修改Eq定义的攻击目标来实现。
3.对于降级攻击,我们只需要将L (,) 更改为 − L (,) 即可。对于可用性攻击,我们可以定义L (,) = Í , ∈ Φ(, − ∈ , )2,其中 Φ 是评级集,, 代表用户 对item 的真实评级。Alg。1不需要任何更改。
4.5理论分析
本部分将对TrialAttack在非参数假设下的学习能力进行系统的理论分析,证明TrialAttack可以在执行有效攻击的同时近似真实用户 (所有证明见附录A.1)。
首先,我们考虑一个没有攻击损失的简化试验攻击,即 1 = 0。然后下面描述生成器和影响模块的学习能力。
引理4.3.当 1 = 0时,对于在 (,,) 的纳什均衡处训练良好的试验攻击,我们可以得到 (,) = (,) = (,),其中 ∗(,) = 0.5。
引理告诉我们,如果TrialAttack不考虑攻击,则生成器和影响模块都可以学习达到均衡时的真实用户分布。此外, ∗(,) = 0.5表示判别器很难区分用户影响对是否是真实的。
引理4.4.对于域X中的两个分布 和 ,假设存在一个小的 使得对于任意 ∈ X, 和 的概率密度 () 和 () 满足 ∥ () − ()∥ <,则 ( | )| = 0。
引理4.4启示我们,对于分布的任何点 ,如果在另一个分布中总是有一个具有小的neighbors邻居的点,那么这两个分布几乎是相同的。
定理4.5.假设 , (,) 是合并攻击损失后生成用户的分布。当达到 (,,) 的均衡时,TrialAttack可以学习和近似真实用户的分布,即 , (,) ≈ (,)。
从定理4.5,我们知道,当考虑攻击损失时,通过TrialAttack学习的评级分布接近真实的。此外,TrialAttack通过最大化影响力来生成具有特定攻击意图的恶意用户。因此,TrialAttack可以产生恶意但接近现实的中毒配置文件。
5实验
5.1实验设置
5.1.1数据集我们使用三个电影数据集,包括ML-100K2 (MovieLens-100K),ML-1M2 (MovieLens-1M) 和FilmTrust3,来评估TrialAttack。对于FilmTrust,我们过滤易受攻击的冷启动用户 (评级数量小于15) [25]。表1列出了这些数据集的具体统计数据。对于每个数据集,我们从每个用户中随机选择一个阳性样本进行测试,并以9:1的比例将其余部分用作训练集和验证集。

5.1.2参数设置
我们将基于MF的推荐系统作为目标模型,除非另有说明,否则我们将潜在因子维度 设置为64。用于Alg的试验攻击训练。1,我们将训练epochs设置为1000,三个模块都使用Adam优化器,生成器和鉴别器的学习率都0.0001,影响模块的学习率设置为0.001, = 0.5, 2 = 100, = 1,= 1, = 2, = 1。对于ML100K,ML-1M和FilmTrust, 1分别设置为2000年,4000、400, 分别设置为500、2000、500。此外,我们将基线中的填充项目数量 '设置为每个用户的平均评分数,并确保通过各种噪声采样采样的填充项目的平均数量不大于 '。https://github.com/Daftstone/TrialAttack. 中提供了trialattack的源代码.
5.1.3比较攻击我们将TrialAttack与经典的先令攻击以及基于模型优化的最新攻击进行了比较,包括随机攻击 [21],平均攻击 [21],PGA [22],TNA [12],和AUSH [25] (我们将其详细信息放在附录A.3中)。值得注意的是,由于使用了不同的数据集,基线在默认设置下的性能很差,因此我们使用网格搜索来获得验证集下的最佳参数。
5.1.4评价指标。我们首先使用平均命中率 (HR @ k) 和归一化贴现累积收益 (NDCG @ k) 作为评估指标。HR @ k测量用户top- 推荐列表中出现的目标项目的平均分数。采用NDCG @ k是因为攻击目标L (,) 的优化是为了提升目标项的排名。对于这两个指标,我们将排名列表 截断为10。
其次,我们研究了两种类型的目标项目:
(1)不受欢迎的项目,它们很少被访问并且更有可能成为攻击者的目标[25]。这里我们随机选择评分数小于5的不受欢迎的项目。
(2)随机项目是从所有项目中随机选择的。目标项目的数量设置为 5。此外,我们在必要时对显着性检验进行配对 t 检验。
5.2 全知识攻击
5.2.1 与基线比较。
我们进行了 30 次独立的重复实验,并在表 2 中总结了平均攻击性能。首先,结果表明 TrialAttack 在 HR@10 和 NDCG@10 方面明显优于基线。与 state-of-the-art 方法 TNA 相比,TrialAttack 在攻击随机项目时对 HR@10 的提升超过 33.7%,并且在攻击冷门项目时提升更为显着,提升高达 72.0%人力资源@10。其次,对于同样基于 GAN 的 AUSH,我们观察到其性能与平均攻击和其他先令攻击几乎相同。那是因为它包含了段内损失,这在本质上仍然是一种启发式先令攻击。最后,我们注意到在 ML-1M 和 ML-100K 中,对冷门物品的攻击伤害比随机物品更明显。当攻击规模为 2% 时,超过 80% 的用户被成功攻击。我们怀疑它们比 FilmTrust 更密集且具有相对较少的行为特征,使它们更容易受到攻击。
5.2.2影响的有效性。
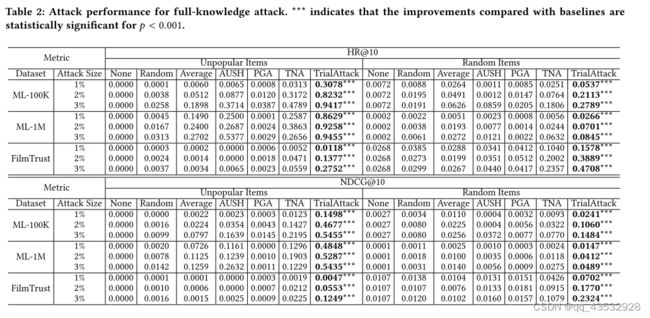
TrialAttack的关键是结合影响力函数来引导生成器产生有影响力的用户。在这一部分中,我们评估了影响函数对攻击性能的影响。设TrialAttack-NIF为无攻击影响损失的攻击,即 1 = 0。表3报告了当攻击大小为3% 时,TrialAttack-NIF与原始TrialAttack攻击随机项目之间的比较。它揭示了利用影响力进行试验攻击的优势是显著的。在ML-100K的最佳情况下,HR @ 10增加约62倍,而NDCG @ 10增加92倍。这些结果强调了影响对提高攻击性能的积极影响。
5.2.3 防御模型中的表现。
我们在防御模型中测试性能。在这里,我们使用了最近研究中最广泛的对抗训练[6,16,31,35]。表 4 列出了攻击规模为 3% 时对抗性训练后的性能。为了强调防御效果,我们这里使用 HR@50。结果表明,即使配置了防御程序,TrialAttack仍然有效并处于领先地位,显示出TrialAttack强大的破坏性。

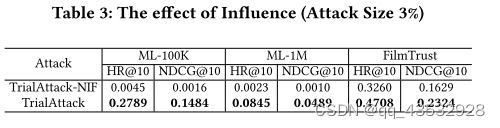
对于观察到的用户的采样,我们采用操作[12],根据到目标项目的距离选择最近的用户。本地模拟器的维度设置为 128,与目标模型不同。图 3 将 HR@10 与仅使用部分用户进行训练时不受欢迎的项目进行了比较(我们在随机项目上也有类似的结果)。我们注意到 TrialAttack 仍然有效,知识的缺乏并没有显着降低攻击性能。相比之下,我们发现获得的知识越多,攻击不一定越好(例如,当观察到 60% 的用户评分时,FilmTrust 中的 PGA 实现了最佳性能)。我们怀疑它可以在获得足够知识的前提下,针对部分用户进行高质量的攻击。
我们还研究了推荐系统维度 的攻击敏感性。我们将本地模拟器的维度 设置为64,而目标系统使用不同的维度。在不受欢迎的项目下的结果如图4所示,它表明该维度具有最小的影响,并且TrialAttack仍然可以在不同维度上产生高质量的假冒用户。攻击总是有效的优良特性给我们一个警钟,即解决推荐系统的安全问题势在必行。

5.3 部分知识攻击
如3.1节所述,我们构建了一个本地模拟器,将部分知识攻击转化为全知识攻击,并在本地模拟器上执行TrialAttack和baseline。对于观察到的用户的采样,我们采用操作[12],根据到目标项目的距离选择最近的用户。本地模拟器的维度设置为 128,与目标模型不同。图 3 将 HR@10 与仅使用部分用户进行训练时不受欢迎的项目进行了比较(我们在随机项目上也有类似的结果)。我们注意到 TrialAttack 仍然有效,知识的缺乏并没有显着降低攻击性能。相比之下,我们发现获得的知识越多,攻击不一定越好(例如,当观察到 60% 的用户评分时,FilmTrust 中的 PGA 实现了最佳性能)。我们怀疑它可以在获得足够知识的前提下,针对部分用户进行高质量的攻击。
我们还研究了推荐系统维度的攻击敏感性。我们将本地模拟器的维度 设置为 64,而目标系统使用不同的维度。冷门项目下的结果如图 4 所示。表明维度影响最小,TrialAttack 仍然可以产生不同维度的高质量假用户。攻击总是有效的优良特性给我们敲响了警钟,解决推荐系统的安全问题势在必行。
5.4假冒用户检测
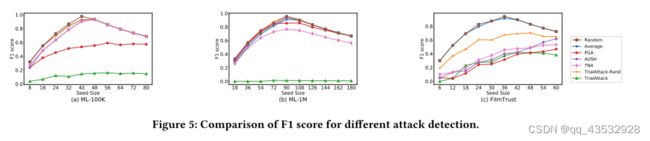
在[28]之后,我们使用基于欺诈行为传播的最先进的同行评审检测方法[38]。对于ML-1M,产生了3%的攻击不同随机项的Offake用户,对于用户数量较少的ML-100K和FilmTrust,产生了10%的虚假用户。为了研究不同噪声采样的有效性,我们将基于随机采样的方法定义为TrialAttack-Rand.
图5报告了在不同参数下检测虚假用户的F1得分。分数越大,检测性能越好。首先,由TrialAttack-Rand生成的大部分用户很容易被检测到,这表明不同的噪声采样在学习真实轮廓方面是有效的。其次,可以看出,在这些数据集中,TrialAttack不容易被察觉。特别是在ML-100K和ML-1M上,假冒用户几乎完全欺骗了检测器,这清楚地验证了TrialAttack在生成不可察觉用户方面的优越性。最后,我们发现对FilmTrust的大多数攻击的检测性能显著下降。我们怀疑FilmTrust更稀疏,更容易被注入类似于正常用户的虚假用户,这也符合[13]中观察到的现象。关于生成用户的真实性验证的更多实验,请参见附录A.5。
6 结论
在本文中,我们提出了一个端到端框架 TrialAttack,用于推荐系统中的中毒攻击。通过生成器、判别器和影响模块的三重对抗学习,TrialAttack 可以有效地产生非显著和有害用户。此外,TrialAttack 的灵活性允许我们设计不同的攻击影响函数,并通过对抗性学习的优化生成具有不同攻击意图的假用户。通过在现实世界数据集下的理论分析和大量实验,我们证明 TrialAttack 可以在执行有效攻击的同时逼近真实用户。与最先进的中毒方法相比,TrialAttack 的性能并不逊色。从理论上讲,只要基于非 MF 的模型在评级松弛后是二阶可微的,我们的解决方案就可以通过替换等式的 来工作。 4 与非基于 MF 的模型的参数。未来,我们计划将 TrialAttack 扩展到其他推荐模型。