Lecture2 线性模型(Linear Model)
注意,文章目录在左侧ヽ(*^ー^)人(^ー^*)ノ
1 模型的训练过程
1.1 课堂案例引入
先来看一幅图:

图1 课堂案例
x=1时,对应y=2;x=2时,对应y=4;x=3时,对应y=6。现在问你x=4时对应的y是多少?
对于人脑来说,我们马上就可以得出一个结论: ,所以x=4时,y=8。然而这个对于计算机来说是困难的,计算机要经过什么过程,才能像人脑一样得出相应结论呢?下面是相关流程图:
,所以x=4时,y=8。然而这个对于计算机来说是困难的,计算机要经过什么过程,才能像人脑一样得出相应结论呢?下面是相关流程图:

简单来说,我们用算法对数据集进行训练,训练出一个模型后,对于以后的输入,我们就可以直接通过模型来预测出结果。

图2 关系图
对于图1,橙色部分相当于训练集(Training Set),浅蓝色部分相当于测试集(Test Set),整个过程叫做监督学习(Supervised Learning),监督学习是机器学习中的一种学习方法,它通过对带有正确答案的样本数据进行训练,来学习预测未知数据的结果。我们根据模型计算出的值与正确的值之间的差异,来对模型进行不断调整与优化,最终得到能更精确预测出结果的模型。
对于图1案例,简言之就是利用橙色部分,来训练出对应模型,然后输入测试集,也就是x=4,让模型预测出x=4时对应的y值。
1.2 数据集、训练集、验证集、测试集之间的关系

图3 注:开发集就是验证集
数据集(Data Set)包括训练集、验证集、测试集。
验证集(Validation Set):为了测试模型的泛化(Generalization)能力,我们通常会把训练集分成两份,一份进行训练,即训练集;一份用来对模型进行评估,即验证集。
测试集:测试集于评估模型的泛化能力,即模型对未见过的数据的预测能力。
通常情况下,我们通过训练集训练模型,然后用测试集来测试模型的泛化能力。然而单纯使用训练集进行训练模型,容易出现过拟合(Overfitting),过拟合是指机器学习模型过于适应训练数据,以至于不能很好地泛化到新数据上的情况。简单来说,就是把不想要的特征也给学习了,比如图像的噪声之类。
此时为了减轻过拟合现象,就需要使用验证集,验证集通过评估模型的泛化能力,帮助开发者更好地调整模型的超参数(Hyperparameter),尽可能减少过拟合的风险。
为什么不直接用测试集来评估泛化能力,而是用验证集来评估呢?因为如果将测试集数据用于评估模型的泛化能力,很容易导致过度拟合,即模型与测试集数据过于紧密地匹配。
更详细请参考这篇文章:http://t.csdn.cn/EAm93
2 模型的设定
2.1 线性模型(Linear Model)
课堂上给出的线性模型是:

图4 线性模型
其中, 表示预测值,
表示预测值, 表示权重,
表示权重, 表示偏移量,偏移量允许模型更好地拟合数据,并且对模型的性能有重要影响。
表示偏移量,偏移量允许模型更好地拟合数据,并且对模型的性能有重要影响。
目前我们要解决的问题,就是确定和的值,使得训练出的模型具有更好的泛化能力。
我们先把模型简化一下,变成

图5 简化后的线性模型
此时我们根据原有的数据来画出对应示意图:
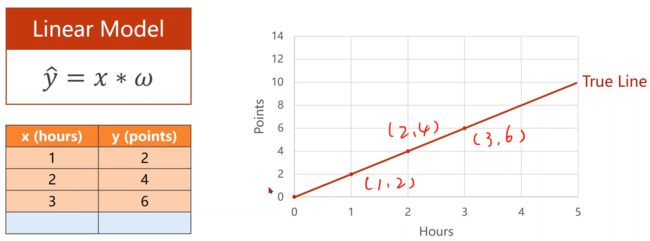
图6 根据原有数据画出正确结果示意图
现在,我们需要不断调整值,使得的值和图中的‘True Line’一致。

图7 不同的权重对应不同的图像
2.2 损失函数(Loss Function)
那么如何确定呢?在机器学习中,通常会以一个随机数作为值,然后通过一个评估模型,来计算不同情况下与真实值对应的误差值,最终确定最拟合情况下的(比如图7中要确定哪条直线与True Line最拟合)。这种评估模型就叫做损失函数(Loss Function),课上用的损失函数模型如下:

图8 损失函数
我们根据损失函数,计算出不同值下的情况,我们的目的是,找到一个值,使得损失的均值(mean)降到最低。:
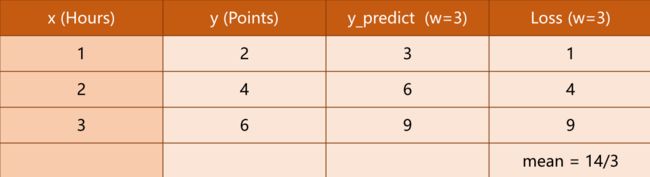
图9 情况1

图10 情况2
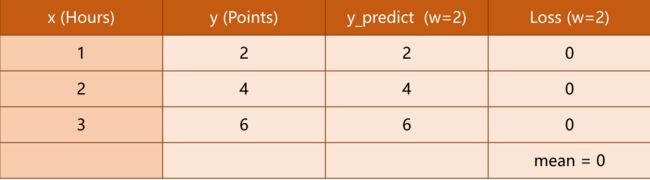
图11 情况3
可以发现,上述评估过程中=2时,Loss均值是最小的,所以我们确定=2是最优值。
2.3 平均平方误差(Mean Square Error)
损失函数仅是对应一个样本的,而对于整个训练集来估算偏差,这时引入了一个新的模型:平均平方误差/均方误差(Mean Square Error), 即MSE。MSE越小,则说明模型的预测更接近实际值,模型更准确。MSE公式的意思是,对所有样本的预测值和真实值的差值的平方进行求和,然后除以样本总数。

图12 MSE和Loss之间的关系
于是能得到下表:

图13 各种情况下MSE的值
那么如何确定要拿哪个数值作为的最优值呢?(这边很容易看出=2时最优,但是在实际情况里,数据量很大,就不好直接确定最优值)
,
2.4 穷举法以及代码实现
这种情况下,一般使用穷举法(Exhaustive search),采样一定范围内的值,计算每个可能的取值对应的Loss值,然后画出对应图像,根据图像性质来确定最优值。比如根据下图可知最低点就是的最优值
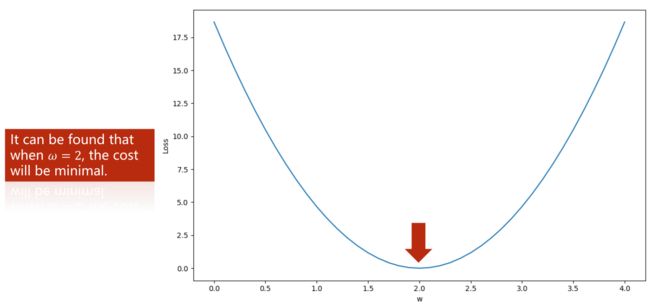
图14 穷举法画出函数图像以确定最优值
代码实现
import numpy as np
import matplotlib.pyplot as plt
'''训练集'''
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
'''线性函数'''
def forward(x):
return x * w
'''损失函数'''
def loss(x, y):
y_pred = forward(x) # 计算出y_hat
return (y_pred - y) * (y_pred - y)
w_list = [] # 用来保存权重
mse_list = [] # 用来保存对应权重的损失值
for w in np.arange(0.0, 4.1, 0.1): # 从0.0到4.1,间隔0.1生成权重序列
print('w=', w)
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
# 代码中使用zip(x_data, y_data)将x_data和y_data中的元素打包为一个tuple,方便同时遍历。
y_pred_val = forward(x_val) # 计算预测值(这边主要是用来打印用)
loss_val = loss(x_val, y_val) # 计算损失值
l_sum += loss_val # 求和
print('\t', x_val, y_val, y_pred_val, loss_val)
print('MSE=', l_sum / 3) # 总和除以样本总数,转变成MSE
w_list.append(w)
mse_list.append(l_sum / 3)
'''绘图'''
plt.plot(w_list, mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
图15 输出结果
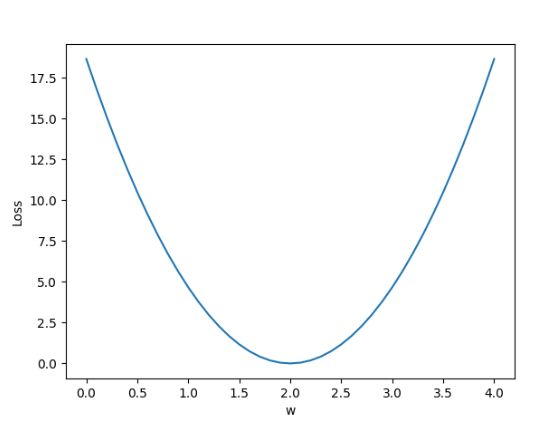
图16 生成图像

图17 生成的数据