斯坦福大学自然语言处理第四课 语言模型(Language Modeling)笔记
一、课程介绍
斯坦福大学于2012年3月在Coursera启动了在线自然语言处理课程,由NLP领域大牛Dan Jurafsky 和 Chirs Manning教授授课:
https://class.coursera.org/nlp/
以下是本课程的学习笔记,以课程PPT/PDF为主,其他参考资料为辅,融入个人拓展、注解,抛砖引玉,欢迎大家在“我爱公开课”上一起探讨学习。
课件汇总下载地址:斯坦福大学自然语言处理公开课课件汇总
二、语言模型(Language Model)
1)N-gram介绍
在实际应用中,我们经常需要解决这样一类问题:如何计算一个句子的概率?如:
- 机器翻译:P(high winds tonite) > P(large winds tonite)
- 拼写纠错:P(about fifteen minutes from) > P(about fifteenminuets from)
- 语音识别:P(I saw a van) >> P(eyes awe of an)
- 音字转换:P(你现在干什么|nixianzaiganshenme) > P(你西安在干什么|nixianzaiganshenme)
- 自动文摘、问答系统、... ...
以上问题的形式化表示如下:
p(S)=p(w1,w2,w3,w4,w5,…,wn)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)//链规则
p(S)被称为语言模型,即用来计算一个句子概率的模型。
那么,如何计算p(wi|w1,w2,...,wi-1)呢?最简单、直接的方法是直接计数做除法,如下:
p(wi|w1,w2,...,wi-1) = p(w1,w2,...,wi-1,wi) / p(w1,w2,...,wi-1)
但是,这里面临两个重要的问题:数据稀疏严重;参数空间过大,无法实用。
基于马尔科夫假设(Markov Assumption):下一个词的出现仅依赖于它前面的一个或几个词。
- 假设下一个词的出现依赖它前面的一个词,则有:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w2)...p(wn|wn-1) // bigram
- 假设下一个词的出现依赖它前面的两个词,则有:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|wn-1,wn-2) // trigram
那么,我们在面临实际问题时,如何选择依赖词的个数,即n。
- 更大的n:对下一个词出现的约束信息更多,具有更大的辨别力;
- 更小的n:在训练语料库中出现的次数更多,具有更可靠的统计信息,具有更高的可靠性。
理论上,n越大越好,经验上,trigram用的最多,尽管如此,原则上,能用bigram解决,绝不使用trigram。
2)构造语言模型
通常,通过计算最大似然估计(Maximum Likelihood Estimate)构造语言模型,这是对训练数据的最佳估计,公式如下:
p(w1|wi-1) = count(wi1-, wi) / count(wi-1)
如给定句子集“ I am Sam
Sam I am
I do not like green eggs and ham ”
部分bigram语言模型如下所示:

c(wi)如下:

c(wi-1,wi)如下:

则bigram为:

那么,句子“ I want english food ”的概率为:
p( I want english food )=p(I|)
× P(want|I)
× P(english|want)
× P(food|english)
× P(|food)
= .000031
为了避免数据溢出、提高性能,通常会使用取log后使用加法运算替代乘法运算。
log(p1*p2*p3*p4) = log(p1) + log(p2) + log(p3) + log(p4)
推荐开源语言模型工具:
- SRILM(http://www.speech.sri.com/projects/srilm/)
- IRSTLM(http://hlt.fbk.eu/en/irstlm)
- MITLM(http://code.google.com/p/mitlm/)
- BerkeleyLM(http://code.google.com/p/berkeleylm/)
推荐开源n-gram数据集:
- Google Web1T5-gram(http://googleresearch.blogspot.com/2006/08/all-our-n-gram-are-belong-to-you.html)
Total number of tokens: 1,306,807,412,486
Total number of sentences: 150,727,365,731
Total number of unigrams: 95,998,281
Total number of bigrams: 646,439,858
Total number of trigrams: 1,312,972,925
Total number of fourgrams: 1,396,154,236
Total number of fivegrams: 1,149,361,413
Total number of n-grams: 4,600,926,713
- Google Book N-grams(http://books.google.com/ngrams/)
- Chinese Web 5-gram(http://www.ldc.upenn.edu/Catalog/catalogEntry.jsp?catalogId=LDC2010T06)
3)语言模型评价
语言模型构造完成后,如何确定好坏呢? 目前主要有两种评价方法:
- 实用方法:通过查看该模型在实际应用(如拼写检查、机器翻译)中的表现来评价,优点是直观、实用,缺点是缺乏针对性、不够客观;
- 理论方法:迷惑度/困惑度/混乱度(preplexity),其基本思想是给测试集赋予较高概率值的语言模型较好,公式如下:

由公式可知,迷惑度越小,句子概率越大,语言模型越好。使用《华尔街日报》训练数据规模为38million words构造n-gram语言模型,测试集规模为1.5million words,迷惑度如下表所示:

4)数据稀疏与平滑技术
大规模数据统计方法与有限的训练语料之间必然产生数据稀疏问题,导致零概率问题,符合经典的zip'f定律。如IBM, Brown:366M英语语料训练trigram,在测试语料中,有14.7%的trigram和2.2%的bigram在训练语料中未出现。
数据稀疏问题定义:“The problem of data sparseness, also known as the zero-frequency problem arises when analyses contain configurations that never occurred in the training corpus. Then it is not possible to estimate probabilities from observed frequencies, and some other estimation scheme that can generalize (that configurations) from the training data has to be used. —— Dagan”。
人们为理论模型实用化而进行了众多尝试与努力,诞生了一系列经典的平滑技术,它们的基本思想是“降低已出现n-gram条件概率分布,以使未出现的n-gram条件概率分布非零”,且经数据平滑后一定保证概率和为1,详细如下:
- Add-one(Laplace) Smoothing
加一平滑法,又称拉普拉斯定律,其保证每个n-gram在训练语料中至少出现1次,以bigram为例,公式如下:

其中,V是所有bigram的个数。
承接上一节给的例子,经Add-one Smoothing后,c(wi-1, wi)如下所示:

则bigram为:

在V >> c(wi-1)时,即训练语料库中绝大部分n-gram未出现的情况(一般都是如此),Add-one Smoothing后有些“喧宾夺主”的现象,效果不佳。那么,可以对该方法扩展以缓解此问题,如Lidstone's Law,Jeffreys-Perks Law。
- Good-Turing Smoothing
其基本思想是利用频率的类别信息对频率进行平滑。调整出现频率为c的n-gram频率为c*:
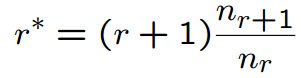


但是,当nr+1或者nr > nr+1时,使得模型质量变差,如下图所示:

直接的改进策略就是“对出现次数超过某个阈值的gram,不进行平滑,阈值一般取8~10”,其他方法请参见“Simple Good-Turing”。
- Interpolation Smoothing
不管是Add-one,还是Good Turing平滑技术,对于未出现的n-gram都一视同仁,难免存在不合理(事件发生概率存在差别),所以这里再介绍一种线性插值平滑技术,其基本思想是将高阶模型和低阶模型作线性组合,利用低元n-gram模型对高元n-gram模型进行线性插值。因为在没有足够的数据对高元n-gram模型进行概率估计时,低元n-gram模型通常可以提供有用的信息。公式如下:

扩展方式(上下文相关)为:
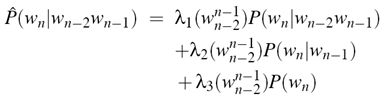
λs可以通过EM算法来估计,具体步骤如下:
- 首先,确定三种数据:Training data、Held-out data和Test data;

- 然后,根据Training data构造初始的语言模型,并确定初始的λs(如均为1);
- 最后,基于EM算法迭代地优化λs,使得Held-out data概率(如下式)最大化。

- Kneser-Ney Smoothing
- Web-scale LMs
如Google N-gram语料库,压缩文件大小为27.9G,解压后1T左右,面对如此庞大的语料资源,使用前一般需要先剪枝(Pruning)处理,缩小规模,如仅使用出现频率大于threshold的n-gram,过滤高阶的n-gram(如仅使用n<=3的资源),基于熵值剪枝,等等。
另外,在存储优化方面也需要做一些优化,如使用trie数据结构存储,借助bloom filter辅助查询,把string映射为int类型处理(基于huffman编码、Varint等方法),float/double转成int类型(如概率值精确到小数点后6位,然后乘10E6,即可将浮点数转为整数)。
2007年Google Inc.的Brants et al.提出了针对大规模n-gram的平滑技术——“Stupid Backoff”,公式如下:

数据平滑技术是构造高鲁棒性语言模型的重要手段,且数据平滑的效果与训练语料库的规模有关。训练语料库规模越小,数据平滑的效果越显著;训练语料库规模越大,数据平滑的效果越不显著,甚至可以忽略不计——锦上添花。
5)语言模型变种
- Class-based N-gram Model
该方法基于词类建立语言模型,以缓解数据稀疏问题,且可以方便融合部分语法信息。
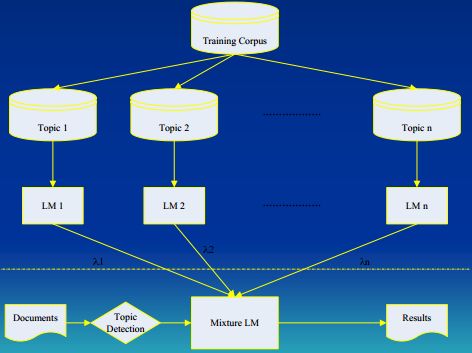
- Topic-based N-gram Model
该方法将训练集按主题划分成多个子集,并对每个子集分别建立N-gram语言模型,以解决语言模型的主题自适应问题。架构如下:
- Cache-based N-gram Model
该方法利用cache缓存前一时刻的信息,以用于计算当前时刻概率,以解决语言模型动态自适应问题。
-People tends to use words as few as possible in the article.
-If a word has been used, it would possibly be used again in the future.
架构如下:

猜测这是目前QQ、搜狗、谷歌等智能拼音输入法所采用策略,即针对用户个性化输入日志建立基于cache的语言模型,用于对通用语言模型输出结果的调权,实现输入法的个性化、智能化。由于动态自适应模块的引入,产品越用越智能,越用越好用,越用越上瘾。
- Skipping N-gram Model&Trigger-based N-gram Model
二者核心思想都是刻画远距离约束关系。
- 指数语言模型:最大熵模型MaxEnt、最大熵马尔科夫模型MEMM、条件随机域模型CRF
传统的n-gram语言模型,只是考虑了词形方面的特征,而没有词性以及语义层面上的知识,并且数据稀疏问题严重,经典的平滑技术也都是从统计学角度解决,未考虑语法、语义等语言学作用。
MaxEnt、MEMM、CRF可以更好的融入多种知识源,刻画语言序列特点,较好的用于解决序列标注问题。
三、参考资料
- Lecture Slides: Language Modeling
- http://en.wikipedia.org
- 关毅,统计自然语言处理基础 课程PPT
- 微软拼音输入法团队,语言模型的基本概念
- 肖镜辉,统计语言模型简介
- fandywang,统计语言模型
-
Stanley F. Chen and Joshua Goodman. An empirical study of smoothing techniques for language modeling. Computer Speech andLanguage, 13:359-394, October 1999.
- Thorsten Brants et al. Large Language Models in Machine Translation
- Gale & Sampson, Good-Turing Smoothing Without Tears
- Bill MacCartney,NLP Lunch Tutorial: Smoothing,2005
P.S. : 基于本次笔记,整理了一份slides,分享下:http://vdisk.weibo.com/s/jzg7h
转自:http://52opencourse.com/111/%E6%96%AF%E5%9D%A6%E7%A6%8F%E5%A4%A7%E5%AD%A6%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86%E7%AC%AC%E5%9B%9B%E8%AF%BE-%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%EF%BC%88language-modeling%EF%BC%89