强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO
前言
22年底/23年初ChatGPT大火,在写《ChatGPT通俗导论》的过程中,发现ChatGPT背后技术涉及到了RL/RLHF,于是又深入研究RL,研究RL的过程中又发现里面的数学公式相比ML/DL更多,于此激发我一边深入RL,一边重修微积分、概率统计、最优化,前者成就了本篇RL极简入门,后者成就了另两篇数学笔记:概率统计极简入门(23修订版)、一文通透优化算法(23修订版)
如上篇ChatGPT笔记所说,本文最早是作为ChatGPT笔记的第一部分的,但RL细节众多,如果想完全在上篇笔记里全部介绍清楚,最后篇幅将长之又长同时还影响完读率,为了避免因为篇幅限制而导致RL很多细节阐述的不够细致,故把RL相关的部分从上文中抽取出来独立成本文
- 一方面,原有内容(第一部分 RL入门:从什么是RL与MRP、MDP,和第四部分 RL高级之策略学习:策略梯度、TRPO、PPO算法)继续完善、改进,完善记录见本文文末
- 二方面,在原有内容上新增了两部分内容的详细阐述:
第二部分 RL进阶之三大表格求解法:DP、MC、TD
第四部分 RL深入之价值学习:Q-learning与DQN
当然,如果你更多只想关注ChatGPT背后的PPO算法,此两部分内容可以忽略
另,本文有两个特色
- 定位入门。过去一个多月,我翻遍了十来本RL中文书,以及网上各种RL资料
有的真心不错(比如sutton的RL书,但此前从来没有接触过RL的不建议一上来就看该书,除非你看过本文之后)
其余大部分要么就是堆砌概念/公式,要么对已经入门的不错,但对还没入门的初学者极度不友好,很多背景知识甚至公式说明、符号说明没有交待,让初学者经常看得云里雾里
本文会假定大部分读者此前从来没有接触过RL,会尽可能多举例、多配图、多交待,100个台阶,一步一步拾级而上,不出现任何断层 - 推导细致。本文之前,99%的文章都不会把PPO算法从头推到尾,本文会把PPO从零推到尾,按照“RL-策略梯度-重要性采样(重要性权重)-增加基线(避免奖励总为正)-TRPO(加进KL散度约束)-PPO(解决TRPO计算量大的问题)”的顺序逐步介绍每一步推导
且为彻底照顾初学者,本文会解释/说明清楚每一个公式甚至符号,包括推导过程中不省任何一个必要的中间推导步骤,十步推导绝不略成三步
总之,大部分写书、写教材、写文章的人过了那个从不懂到懂的过程,所以懂的人写给不懂的人看,处处都是用已懂的思维去写,而不是用怎么从不懂到懂的思维 去写,未来三年 奋笔疾书,不断给更多初学者普及AI和RL技术
第一部分 RL入门:从什么是RL与MRP、MDP
1.1 入门强化学习所需掌握的基本概念
1.1.1 什么是强化学习:依据策略执行动作-感知状态-得到奖励
强化学习里面的概念、公式,相比ML/DL特别多,初学者刚学RL时,很容易被接连不断的概念、公式给绕晕,而且经常忘记概念与公式符号表达的一一对应。
为此,我建议学习RL的第一步就是一定要扎实关于RL的一些最基本的概念、公式(不要在扎实基础的阶段图快或图囵吞枣,不然后面得花更多的时间、更大的代价去弥补),且把概念与公式的一一对应关系牢记于心,这很重要。当然,为最大限度的提高本文的可读性,我会尽可能的多举例、多配图。
另,RL里面存着大量的数学,考虑到可以为通俗而增加篇幅,但不为了介绍而介绍式的增加篇幅,故
- 像高数/概率统计里的什么叫导数,期望以及什么叫概率分布、熵/香浓熵(Shannon熵)/交叉熵、相对熵(也称KL散度,即KL divergence)、多元函数、偏导数,可以参见Wikipedia或《概率统计极简入门:通俗理解微积分/期望方差/正态分布前世今生(23修订版)》等类似笔记
- 而AI一些最基本的概念比如损失函数、梯度、梯度下降、随机梯度下降(SGD)、学习率等,可以参考此篇笔记:《一文通透优化算法:从梯度下降、SGD到牛顿法、共轭梯度(23修订版)》,本文则不过多介绍
话休絮烦,下面进入正题,且先直接给出强化学习的定义和其流程,然后再逐一拆解、说明。
所谓强化学习(Reinforcement Learning,简称RL),是指基于智能体在复杂、不确定的环境中最大化它能获得的奖励,从而达到自主决策的目的。
经典的强化学习模型可以总结为下图的形式(你可以理解为任何强化学习都包含这几个基本部分:智能体、行为、环境、状态、奖励):

一般的文章在介绍这些概念时很容易一带而过,这里我把每个概念都逐一解释下
- Agent,一般译为智能体,就是我们要训练的模型,类似玩超级玛丽的时候操纵马里奥做出相应的动作,而这个马里奥就是Agent
- action(简记为
 ),玩超级玛丽的时候你会控制马里奥做三个动作,即向左走、向右走和向上跳,而马里奥做的这三个动作就是action
),玩超级玛丽的时候你会控制马里奥做三个动作,即向左走、向右走和向上跳,而马里奥做的这三个动作就是action - Environment,即环境,它是提供reward的某个对象,它可以是AlphaGo中的人类棋手,也可以是自动驾驶中的人类驾驶员,甚至可以是某些游戏AI里的游戏规则
- reward(简记为
 ),这个奖赏可以类比为在明确目标的情况下,接近目标意味着做得好则奖,远离目标意味着做的不好则惩,最终达到收益/奖励最大化,且这个奖励是强化学习的核心
),这个奖赏可以类比为在明确目标的情况下,接近目标意味着做得好则奖,远离目标意味着做的不好则惩,最终达到收益/奖励最大化,且这个奖励是强化学习的核心 - State(简介为
 ),可以理解成环境的状态,简称状态
),可以理解成环境的状态,简称状态
总的而言,Agent依据策略决策从而执行动作action,然后通过感知环境Environment从而获取环境的状态state,进而,最后得到奖励reward(以便下次再到相同状态时能采取更优的动作),然后再继续按此流程“依据策略执行动作-感知状态--得到奖励”循环进行。
1.1.2 RL与监督学习的区别和RL方法的分类
此外,RL和监督学习(supervised learning)的区别:
- 监督学习有标签告诉算法什么样的输入对应着什么样的输出(譬如分类、回归等问题)
所以对于监督学习,目标是找到一个最优的模型函数,使其在训练数据集上最小化一个给定的损失函数,相当于最小化预测误差
最优模型 = arg minE { [损失函数(标签,模型(特征)] }
RL没有标签告诉它在某种情况下应该做出什么样的行为,只有一个做出一系列行为后最终反馈回来的reward,然后判断当前选择的行为是好是坏
相当于RL的目标是最大化智能体策略在和动态环境交互过程中的价值,而策略的价值可以等价转换成奖励函数的期望,即最大化累计下来的奖励期望
最优策略 = arg maxE { [奖励函数(状态,动作)] }
- 监督学习如果做了比较坏的选择则会立刻反馈给算法
RL的结果反馈有延时,有时候可能需要走了很多步以后才知道之前某步的选择是好还是坏 - 监督学习中输入是独立分布的,即各项数据之间没有关联
RL面对的输入总是在变化,每当算法做出一个行为,它就影响了下一次决策的输入
进一步,RL为得到最优策略从而获取最大化奖励,有
- 基于值函数的方法,通过求解一个状态或者状态下某个动作的估值为手段,从而寻找最佳的价值函数,找到价值函数后,再提取最佳策略
比如Q-learning、DQN等,适合离散的环境下,比如围棋和某些游戏领域 - 基于策略的方法,一般先进行策略评估,即对当前已经搜索到的策略函数进行估值,得到估值后,进行策略改进,不断重复这两步直至策略收敛
比如策略梯度法(policy gradient,简称PG),适合连续动作的场景,比如机器人控制领域
以及Actor-Criti(一般被翻译为演员-评论家算法),Actor学习参数化的策略即策略函数,Criti学习值函数用来评估状态-动作对,不过,Actor-Criti本质上是属于基于策略的算法,毕竟算法的目标是优化一个带参数的策略,只是会额外学习价值函数,从而帮助策略函数更好的学习
此外,还有对策略梯度算法的改进,比如TRPO算法、PPO算法,当然PPO算法也可称之为是一种Actor-Critic架构,下文会重点阐述
可能你还有点懵懵懂懂,没关系,毕竟还有不少背景知识还没有交待,比如RL其实是一个马尔可夫决策过程(Markov decision process,MDP),而为说清楚MDP,得先从随机过程、马尔可夫过程(Markov process,简称MP)开始讲起,故为考虑逻辑清晰,我们还是把整个继承/脉络梳理下。
1.2 什么是马尔科夫决策过程
1.2.1 MDP的前置知识:随机过程、马尔可夫过程、马尔可夫奖励
如HMM学习最佳范例中所说,有一类现象是确定性的现象,比如红绿灯系统,红灯之后一定是红黄、接着绿灯、黄灯,最后又红灯,每一个状态之间的变化是确定的

但还有一类现象则不是确定的,比如今天是晴天,谁也没法百分百确定明天一定是晴天还是雨天、阴天(即便有天气预报)

对于这种假设具有 个状态的模型
个状态的模型
- 共有
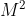 个状态转移,因为任何一个状态都有可能是所有状态的下一个转移状态
个状态转移,因为任何一个状态都有可能是所有状态的下一个转移状态 - 每一个状态转移都有一个概率值,称为状态转移概率,相当于从一个状态转移到另一个状态的概率
- 所有的个概率可以用一个状态转移矩阵表示
下面的状态转移矩阵显示的是天气例子中可能的状态转移概率:

也就是说,如果昨天是晴天,那么今天是晴天的概率为0.5,是多云的概率为0.375、是雨天的概率为0.125,且这三种天气状态的概率之和必为1。
接下来,我们来抽象建模下。正如概率论的研究对象是静态的随机现象,而随机过程的研究对象是随时间演变的随机现象(比如天气随时间的变化):
- 随机现象在某时刻t的取值是一个向量随机变量,用
 表示
表示
比如上述天气转移矩阵便如下图所示

- 在某时刻t的状态通常取决于t时刻之前的状态,我们将已知历史信息
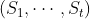 时下一个时刻的状态
时下一个时刻的状态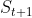 的概率表示成
的概率表示成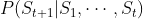
如此,便可以定义一个所有状态对之间的转移概率矩阵
- 当且仅当某时刻的状态只取决于上一时刻的状态时,一个随机过程被称为具有马尔可夫性质,即
 ,当然了,虽说当前状态只看上一个状态,但上一个状态其实包含了更上一个状态的信息,所以不能说当下与历史是无关的
,当然了,虽说当前状态只看上一个状态,但上一个状态其实包含了更上一个状态的信息,所以不能说当下与历史是无关的 - 而具有马尔可夫性质的随机过程便是马尔可夫过程
在马尔可夫过程的基础上加入奖励函数 和折扣因子
和折扣因子 ,就可以得到马尔可夫奖励过程(Markov reward process,MRP)。其中
,就可以得到马尔可夫奖励过程(Markov reward process,MRP)。其中
- 奖励函数,某个状态的奖励
 ,是指转移到该状态时可以获得奖励的期望,有
,是指转移到该状态时可以获得奖励的期望,有![R(s) = E[R_{t+1}|S_t = s]](http://img.e-com-net.com/image/info8/077f6fe19ce441a4a6e38a6b4d6ee66d.gif)
注意,有的书上奖励函数和下面回报公式中的 的下标
的下标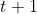 写为
写为 ,其实严格来说,先有时刻的状态/动作之后才有时刻的奖励,但应用中两种下标法又都存在,读者注意辨别
,其实严格来说,先有时刻的状态/动作之后才有时刻的奖励,但应用中两种下标法又都存在,读者注意辨别 - 此外,实际中,因为一个状态可以得到的奖励是持久的,所有奖励的衰减之和称为回报,可用
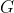 表示当下即时奖励和所有持久奖励等一切奖励的加权和(考虑到一般越往后某个状态给的回报率越低,也即奖励因子或折扣因子越小,用表示),从而有
表示当下即时奖励和所有持久奖励等一切奖励的加权和(考虑到一般越往后某个状态给的回报率越低,也即奖励因子或折扣因子越小,用表示),从而有
举个例子,一个少年在面对“上大学、去打工、在家啃老”这三种状态,哪一种更能实现人生的价值呢?
相信很多人为长远发展都会选择上大学,因为身边有太多人因为上了大学,而好事连连,比如读研读博留学深造、进入大厂、娶个漂亮老婆、生个聪明孩子
当然了,上大学好处肯定多多,但上大学这个状态对上面4件好事所给予的贡献必然是逐级降低,毕竟越往后,越会有更多或更重要的因素成就更后面的好事,总不能所有好事都百分百归功于最开头选择了“上大学”这个状态/决策嘛
而一个状态的期望回报就称之为这个状态的价值,所有状态的价值则组成了所谓的价值函数,用公式表达为![V(s) = E[G_t|S_t=s]](http://img.e-com-net.com/image/info8/8967a7f2f5a9491f87f2b16da5bb4e7a.gif) ,展开一下可得
,展开一下可得
在上式最后一个等式中
- 前半部分表示当前状态得到的即时奖励
![E[R_{t+1}|S_t = s] = R(s)](http://img.e-com-net.com/image/info8/740bced49772498e9920d1cb4fa468bd.gif)
- 后半部分表示当前状态得到的所有持久奖励
![\gamma E[V(S_{t+1})|S_t = s]](http://img.e-com-net.com/image/info8/62b6caa4e7e947d6b35948dc89818775.gif) ,可以根据从状态出发的转移概率得到『至于上述推导的最后一步,即为何
,可以根据从状态出发的转移概率得到『至于上述推导的最后一步,即为何![E[G_{t+1}|S_t = s]](http://img.e-com-net.com/image/info8/612c6f4c1daf4a76a12562803c56c437.gif) 等于
等于![E[v(S_{t+1}|S_t = s)]](http://img.e-com-net.com/image/info8/27290e7c31174299aa52e700903caf0a.gif) ,待补充』
,待补充』
从而,综合前后两个部分可得
![]()
而这就是所谓的贝尔曼方程(bellman equation)。该公式精准而简洁,其背后浓缩了很多信息,为形象起见,举个例子,比如状态 得到的即时奖励为
得到的即时奖励为![]() ,然后接下来,有
,然后接下来,有
 的概率引发状态
的概率引发状态 ,此时状态得到的即时奖励为
,此时状态得到的即时奖励为
接下来有 的概率引发状态
的概率引发状态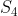 (的即时奖励为
(的即时奖励为 ,后续无持久奖励),有
,后续无持久奖励),有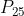 的概率引发状态
的概率引发状态 (的即时奖励为
(的即时奖励为 ,后续无持久奖励)
,后续无持久奖励) 的概率引发状态
的概率引发状态 ,此时状态得到的即时奖励为
,此时状态得到的即时奖励为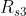
接下来有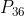 的概率引发状态
的概率引发状态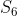 (的即时奖励为
(的即时奖励为 ,后续无持久奖励),有
,后续无持久奖励),有 的概率引发状态
的概率引发状态 (的即时奖励为
(的即时奖励为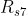 ,后续无持久奖励)
,后续无持久奖励)
其中折扣因此为,那么因状态而得到的一切奖励为
类似的,因状态得到的一切奖励为![]()
为更加形象起见,再举一个生活中最常见的“吃饭-抽烟/剔牙”例子
比如你吃完饭后你自己的心情愉悦值即奖励+5,然后下一个状态,有
- 0.6的概率是抽烟(抽烟带来的心情愉悦值即奖励+7,要不说 饭后一支烟 赛过活神仙呢)
- 0.4的概率是剔牙(剔牙带来的奖励值+3)
假设折扣因子
- 吃饭的状态定义为
,则
- 抽烟的状态定义为
,则
,且由于抽烟之后无后续状态,所以
也是7
- 剔牙的状态定义为
,则
,且由于剔牙之后无后续状态,所以
也是3
从而有:
当从
时,
当从时,
由于状态
再根据贝尔曼方程
,可得状态
当然,你也可以如此计算(可以很明显的看出,计算量不如上述过程简洁,所以一般优先按上述方式计算)


上述例子的状态比较少所以计算量不大,但当状态一多,则贝尔曼方程的计算量还是比较大的,而求解较大规模的马尔可夫奖励过程中的价值函数时,可以用的方法包括:动态规划、蒙特卡洛方法、时序差分(temporal difference,简称TD)方法
当然,其中细节还是不少的,下文第二部分会详述这三大方法
1.2.2 马尔可夫决策过程(MDP):马尔可夫奖励(MRP) + 智能体动作因素
根据上文我们已经得知,在随机过程的基础上
- 增加马尔可夫性质,即可得马尔可夫过程
- 而再增加奖励,则得到了马尔可夫奖励过程(MRP)
- 如果我们再次增加一个来自外界的刺激比如智能体的动作,就得到了马尔可夫决策过程(MDP)
通俗讲,MRP与MDP的区别就类似随波逐流与水手划船的区别
在马尔可夫决策过程中,
(
是状态的集合)和
(
和前一个动作
(
是动作的集合),并且与更早之前的状态和动作完全无关
换言之,当给定当前状态(比如![]() ),以及当前采取的动作
),以及当前采取的动作 (比如
(比如 ),那么下一个状态出现的概率,可由状态转移概率矩阵表示如下
),那么下一个状态出现的概率,可由状态转移概率矩阵表示如下
![]()
考虑到在当前状态和当前动作确定后,那么其对应的即时奖励则也确定了 ,故sutton的RL一书中,给的状态转移概率矩阵类似为
,故sutton的RL一书中,给的状态转移概率矩阵类似为
![]()
从而可得奖励函数即为
![\begin{aligned}R(s,a) &= E[R_{t+1} | S_t = s,A_t = a] \\&=\sum_{s'\in S}^{}p(s',r|s,a) \sum_{r\in R}^{}r \end{aligned}](http://img.e-com-net.com/image/info8/99d840be209845ee96e3fb3d8f5ac29c.gif)
至于过程中采取什么样的动作就涉及到策略policy,策略函数可以表述为 函数(当然,这里的跟圆周率没半毛钱关系)
函数(当然,这里的跟圆周率没半毛钱关系)
- 从而可得
 ,意味着输入状态,策略函数输出动作
,意味着输入状态,策略函数输出动作 - 此外,还会有这样的表述:
 ,相当于在输入状态确定的情况下,输出的动作只和参数
,相当于在输入状态确定的情况下,输出的动作只和参数 有关,这个就是策略函数的参数
有关,这个就是策略函数的参数 - 再比如这种
 ,相当于输入一个状态下,智能体采取某个动作的概率
,相当于输入一个状态下,智能体采取某个动作的概率
通过上文,我们已经知道不同状态出现的概率不一样(比如今天是晴天,那明天是晴天,还是雨天、阴天不一定),同一状态下执行不同动作的概率也不一样(比如即便在天气预报预测明天大概率是天晴的情况下,你大概率不会带伞,但依然不排除你可能会防止突然下雨而带伞)
而有了动作这个因素之后,我们重新梳理下价值函数
- 首先,通过“状态价值函数”对当前状态进行评估
相当于从状态![\begin{aligned} V_{\pi}(s) &= E_\pi [G_t|S_t = s] \\& = E_\pi [R_{t+1} + \gamma G_{t+1} | S_t = s] \\& = E_\pi [R_{t+1} + \gamma V_\pi (S_{t+1}) | S_t = s] \end{aligned}](http://img.e-com-net.com/image/info8/4a96152feaec4d5f850e8c3066766442.gif) 出发遵循策略能获得的期望回报
出发遵循策略能获得的期望回报 - 其次,通过“动作价值函数”对动作的评估
相当于对当前状态依据策略执行动作得到的期望回报,这就是大名鼎鼎的 函数,得到函数后,进入某个状态要采取的最优动作便可以通过函数得到
函数,得到函数后,进入某个状态要采取的最优动作便可以通过函数得到
当有了策略、价值函数和模型3个组成部分后,就形成了一个马尔可夫决策过程(Markov decision process)。如下图所示,这个决策过程可视化了状态之间的转移以及采取的动作。

且通过状态转移概率分布,我们可以揭示状态价值函数和动作价值函数之间的联系了
- 在使用策略时,状态的价值等于在该状态下基于策略采取所有动作的概率与相应的价值相乘再求和的结果

我猜可能有读者会问怎么来的,简略推导如下『至于如果不清楚从第一个等式到第二个等式怎么来的,待后续详述』

-
而使用策略
时,在状态下采取动作的价值等于当前奖励 ,加上经过衰减的所有可能的下一个状态的状态转移概率与相应的价值的乘积
,加上经过衰减的所有可能的下一个状态的状态转移概率与相应的价值的乘积
针对这个公式 大部分资料都会一带而过,但不排除会有不少读者问怎么来的,考虑到对于数学公式咱们不能想当然靠直觉的自认为,所以还是得一五一十的推导下
其中,倒数第二步依据的是
![E[ G_{t+1} | S_t =s,A_t = a] = \sum_{s'}^{} V_\pi (S_{t+1}) P[S_{t+1} = s' |S_t =s,A_t = a ]](http://img.e-com-net.com/image/info8/6da828952d77427ca0dc77bd1d59fbae.gif) ,最后一步依据的状态转移概率矩阵的定义
,最后一步依据的状态转移概率矩阵的定义
接下来,把上面 和
和![]() 的计算结果互相代入,可得马尔可夫决策的贝尔曼方程
的计算结果互相代入,可得马尔可夫决策的贝尔曼方程
![V_{\pi}(s) = \sum_{a \in A}^{}\pi (a|s)\left [ r(s,a) + \gamma \sum_{s' \in S}^{}P(s'|s,a)V_\pi (s'))\right ]](http://img.e-com-net.com/image/info8/0e3fa7c752284380bab69f63cc0ccd22.gif)
![Q_\pi (s,a) = r(s,a) + \gamma \sum_{s' \in S}^{}P(s'|s,a)\left [ \sum_{a \in A}^{}\pi (a'|s')Q_\pi (s',a') \right ]](http://img.e-com-net.com/image/info8/460e580693a745ee8238ee45fddcd108.gif)
上述过程可用下图形象化表示(配图来自文献21)

计算示例和更多细节待补充..
第二部分 RL进阶之三大表格求解法:DP、MC、TD
2.1 动态规划法
2.1.1 什么是动态规划
上文简单介绍过动态规划,其核心思想在于复杂问题的最优解划分为多个小问题的最优解的求解问题,就像递归一样,且子问题的最优解会被储存起来重复利用
举个例子,输入两个整数n和sum,从数列1,2,3.......n 中随意取几个数,使其和等于sum,要求将其中所有的可能组合列出来。
注意到取n,和不取n个区别即可,考虑是否取第n个数的策略,可以转化为一个只和前n-1个数相关的问题。
- 如果取第n个数,那么问题就转化为“取前n-1个数使得它们的和为sum-n”,对应的代码语句就是sumOfkNumber(sum - n, n - 1);
- 如果不取第n个数,那么问题就转化为“取前n-1个数使得他们的和为sum”,对应的代码语句为sumOfkNumber(sum, n - 1)
所以其关键代码就是
list1.push_front(n); //典型的01背包问题
SumOfkNumber(sum - n, n - 1); //“放”n,前n-1个数“填满”sum-n
list1.pop_front();
SumOfkNumber(sum, n - 1); //不“放”n,前n-1个数“填满”sum其实,这是一个典型的0-1背包问题,其具体描述为:有
件物品和一个容量为
的背包。放入第
件物品耗费的费用是
(也即占用背包的空间容量),得到的价值是
,求解将哪些物品装入背包可使价值总和最大。
简单分析下:这是最基础的背包问题,特点是每种物品仅有一件,可以选择放或不放。用子问题定义状态:即
表示前
的背包可以获得的最大价值
对于“将前i件物品放入容量为v的背包中”这个子问题,若只考虑第i件物品的策略(放或不放),那么就可以转化为一个只和前
件物品相关的问题。即:
- 如果不放第
;
- 如果放第
的背包中”,此时能获得的最大价值就是
再加上通过放入第i件物品获得的价值
则其状态转移方程便是:
通过上述这两个个例子,相信你已经看出一些端倪,具体而言,动态规划一般也只能应用于有最优子结构的问题。最优子结构的意思是局部最优解能决定全局最优解(对有些问题这个要求并不能完全满足,故有时需要引入一定的近似)。简单地说,问题能够分解成子问题来解决。
动态规划算法一般分为以下4个步骤:
- 描述最优解的结构
- 递归定义最优解的值
- 按自底向上的方式计算最优解的值 //此3步构成动态规划解的基础。
- 由计算出的结果构造一个最优解 //此步如果只要求计算最优解的值时,可省略
换言之,动态规划方法的最优化问题的俩个要素:最优子结构性质,和子问题重叠性质
- 最优子结构
如果问题的最优解所包含的子问题的解也是最优的,我们就称该问题具有最优子结构性质(即满足最优化原理)。意思就是,总问题包含很多个子问题,而这些子问题的解也是最优的。 - 重叠子问题
子问题重叠性质是指在用递归算法自顶向下对问题进行求解时,每次产生的子问题并不总是新问题,有些子问题会被重复计算多次。动态规划算法正是利用了这种子问题的重叠性质,对每一个子问题只计算一次,然后将其计算结果保存在一个表格中,当再次需要计算已经计算过的子问题时,只是在表格中简单地查看一下结果,从而获得较高的效率
更多请参看此文(上面阐述什么是DP的内容就来自此文):通俗理解动态规划:由浅入深DP并解决LCS问题(23年修订版)
2.1.2 通过动态规划法求解最优策略
如果你之前没接触过RL,你确实可能会认为DL只存在于数据结构与算法里,实际上
- 最早在1961年,有人首次提出了DP与RL之间的关系
- 1977年,又有人提出了启发式动态规划,强调连续状态问题的梯度下降法
- 再到1989年,Watkins明确的将RL与DP联系起来,并将这一类强化学习方法表征为增量动态规划
下面,我们考虑如何求解最优策略![]()
- 首先,最优策略可以通过最大化
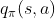 找到
找到 - 当
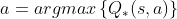 时,
时,
综合上述两点,可得

另,考虑到
故也可以如sutton的RL一书上,这样写满足贝尔曼最优方程的价值函数![]()
![\begin{aligned} v_*(s) &= max E[R_{t+1} + \gamma v_*(S_{t+1}) | S_t =s,A_t =a] \\&= max \sum_{s',r}^{}p(s',r|s,a) [r + \gamma v_*(s')] \end{aligned}](http://img.e-com-net.com/image/info8/a974a07e13db43948140e5ae9312bd90.gif)
相当于当知道奖励函数和状态转换函数时,便可以根据下一个状态的价值来计算当前状态的价值,意味着可以把计算下一个可能状态的价值当成一个子问题,而把计算当前状态的价值看做当前问题,这不刚好就可以用DP来求解了
于是,sutton的RL一书上给出了DP求解最优策略的算法流程
- 1.初始化
对,任意设定
以及
- 2.策略评估
循环:
对每一个
直到- 3. 策略改进
policy-stabletrue
对每一个
old-actiton
如果old-action,那么policy-stable
如果policy-stable为true,那么停止并返回以及
;否则跳转到2
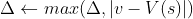


![\pi (s) \leftarrow argmax_{(a)} \left \{ \sum_{s',r}^{}p(s',r|s,a) [r + \gamma V(s')] \right \}](http://img.e-com-net.com/image/info8/d21310f62ae141c29e562dabcc6f7aa6.gif)
2.2 蒙特卡洛法
蒙特卡洛(monte carlo,简称MC)方法,也称为统计模拟方法,就是通过大量的随机样本来估算或近似真实值,比如近似估算圆的面经、近似定积分、近似期望、近似随机梯度
比如先看估算圆的面积,如下图
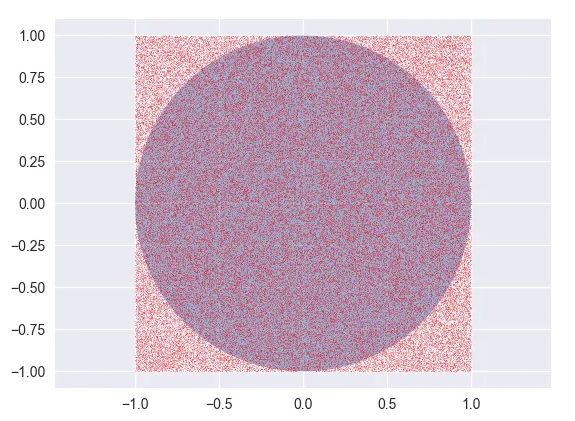
可以通过这个式子来近似计算:圆的面积/ 正方形的面积 = 圆中点的个数/正方形中点的个数
类似的,我们也可以用蒙特卡洛方法来估计一个策略在一个马尔可夫决策过程中的状态价值。考虑到 一个状态的价值是它的期望回报,那么如果我们用策略在MDP上采样很多条序列,然后计算从这个状态出发的回报再求其期望是否就可以了?好像可行!公式如下:
![V_\pi (s) = E_\pi [G_t|S_t = s] = \frac{1}{N} \sum_{i=1}^{N}G_{t}^{(i)}](http://img.e-com-net.com/image/info8/c666e71e77204ebbbc38a4d82628b105.gif)
再看下如何估算定积分的值『如果忘了定积分长啥样的,可以通过RL所需数学基础的其中一篇笔记《概率统计极简入门:通俗理解微积分/期望方差/正态分布前世今生(23修订版)》回顾下,比如积分可以理解为由无数个无穷小的面积组成的面积S』
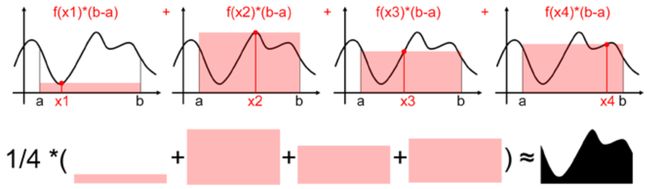
如上图,我们可以通过随机取4个点,然后类似求矩形面积那样(底x高),从而用4个面积![]() 的期望来估算定积分
的期望来估算定积分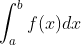 的值,为让对面积的估算更准确,我们可以取更多的点,比如,当
的值,为让对面积的估算更准确,我们可以取更多的点,比如,当![]() 时
时

接下来
- 假设令
![q(x) = \begin{cases} \frac{1}{a-b} & \text{ , } x\in [a,b] \\ 0 & \text{ } \end{cases}](http://img.e-com-net.com/image/info8/047774cdedc545ef9ea41aa6cb8c54dc.gif) ,且
,且
- 且考虑到对于连续随机变量
 ,其概率密度函数为
,其概率密度函数为 ,期望为
,期望为![E[X] = \int_{-\propto }^{\propto }xp(x)dx](http://img.e-com-net.com/image/info8/5c926f52799544478d2abb1c0d2e1e69.gif)
则有
![\int_{a}^{b}f(x)dx = \int_{a}^{b}f^*(x)q(x)dx = E_{x\sim f_{X}(x)}[f^*(x)]]](http://img.e-com-net.com/image/info8/b95cb8ecdb9a492e92fc4bab6ccd25bf.gif)
跟蒙特卡洛方法关联的还有一个重要性采样,不过,暂不急,在第四部分时用到再讲。
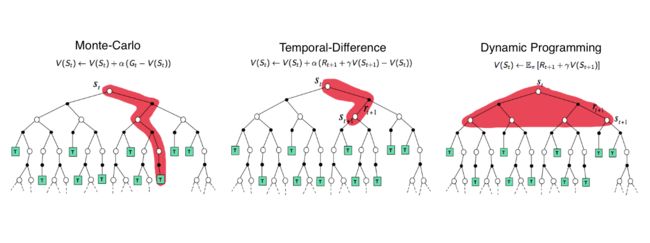
2.3 时序差分法及与DP、MC的区别
当面对状态价值函数的求解时
上述公式总共三个等式
- 动态规划(DP)会把上述第三个等式的估计值作为目标,不是因为DP要求需要环境模型本身提供期望值,而是因为真实的
 是未知的,所以只能使用当前的估计值
是未知的,所以只能使用当前的估计值 来替代
来替代 ![V(S_t) \leftarrow E_\pi [R_{t+1} + \gamma V(S_{t+1})]](http://img.e-com-net.com/image/info8/0137fd38b7dc45fd8116999ab90e0720.gif)
且DP求解状态
的状态值函数时,需要利用所有后续状态 - 蒙特卡洛方法(MC)会上述把第一个等式的估计值作为目标,毕竟第一个等式中的期望值是未知的,所以我们用样本回报来代替实际的期望回报
但MC求解状态
的状态值函数时,需要等一个完整序列结束![V(S_t) \leftarrow V(S_t) + \alpha [G_t - V(S_t)]](http://img.e-com-net.com/image/info8/8c74ca93e8094bab87e270da0e0041a0.gif)
- 而时序差分(TD)呢,它既要采样得到上述第一个等式的期望值,而且还要通过使用上述第三个等式中当前的估计值来替代真实值

且TD每过一个time step就利用奖励和值函数 更新一次(当然,这里所说的one-step TD 方法,也可以两步一更新,三步一更新….),考虑到
更新一次(当然,这里所说的one-step TD 方法,也可以两步一更新,三步一更新….),考虑到
此更新法也叫TD(0)法,或者一步时序差分法,![V(S_t) \leftarrow V(S_t) + \alpha \left [ R_{t+1} + \gamma V{S_{t+1}} - V(S_t) \right ]](http://img.e-com-net.com/image/info8/975fcc6608bd4205a04df5464ad64a05.gif)
 被称为TD目标,
被称为TD目标, 被称为TD误差
被称为TD误差
与DP一致的是 ,时序差分方法也无需等待交互的最终结果,而可以基于下一个时刻的收益和估计值来更新当前状态的价值函数
不需像MC等到N步以后即return一个episode结束后才能更新 ,因为只有知道此时,
,因为只有知道此时, 才是已知的
才是已知的
就像不同学生做题,有的学生则是TD派:做完一题就问老师该题做的对不对 然后下一题即更新做题策略,有的学生是MC派:做完全部题才问老师所有题做的对不对 然后下一套试卷更新做题策略
与DP不一致的是,TD俗称无模型的RL算法,不需要像DP事先知道环境的奖励函数和状态转移函数(和MC一样,可以直接从与环境互动的经验中学习策略,事实上,很多现实环境中,其MDP的状态转移概率无从得知)
总之,TD结合了DP和MC,与DP一致的点时与MC不一致,与DP不一致的点时恰又与MC一致,某种意义上来说,结合了前两大方法各自的优点,从而使得在实际使用中更灵活,具体而言
第三部分 RL深入之价值学习:Q-learning与DQN
3.1 TD(0)控制/Sarsa(0)算法与多步Sarsa算法
既然上文可以用时序差分来估计状态价值函数,那是否可以用类似策略迭代的方法来评估动作价值函数呢?毕竟在无模型的RL问题中,动作价值函数比状态价值函数更容易被评估
接下来,我们来看下TD(0)控制如何寻找最优的动作价值函数,并提取出最优策略
TD(0)控制算法有时也被称作Sarsa(0)算法,可以如下表达
![]()
此外,上文说过,“TD每过一个time step就利用奖励和值函数 更新一次(当然,这里所说的one-step TD 方法,也可以两步一更新,三步一更新”,这个所谓的多步一更新我们便称之为N步时序差分法
// 待补充
第四部分 RL高级之策略学习:策略梯度、TRPO、PPO算法
4.1 策略梯度与其两个问题:采样效率低下与步长难以确定
本节推导的核心内容参考自Easy RL教程等资料(但修正了原教程上部分不太准确的描述,且为让初学者更好懂,补充了大量的解释说明和心得理解,倪老师则帮拆解了部分公式)。
另,都说多一个公式则少一个读者,本文要打破这点,虽然本节推导很多,但每一步推导都有介绍到,不会省略任何一步推导,故不用担心看不懂(对本文任何内容有任何问题,都欢迎随时留言评论)。
4.1.1 什么是策略梯度和梯度计算/更新的流程
策略梯度的核心算法思想是:
- 参数为的策略
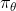 接受状态,输出动作概率分布,在动作概率分布中采样动作,执行动作(形成运动轨迹
接受状态,输出动作概率分布,在动作概率分布中采样动作,执行动作(形成运动轨迹 ),得到奖励,跳到下一个状态
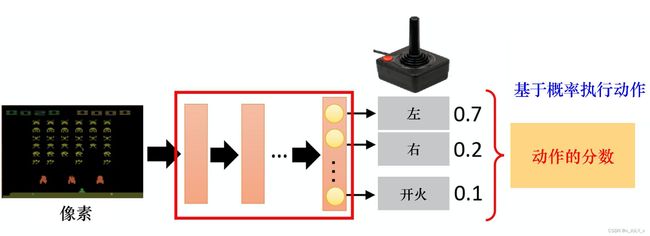
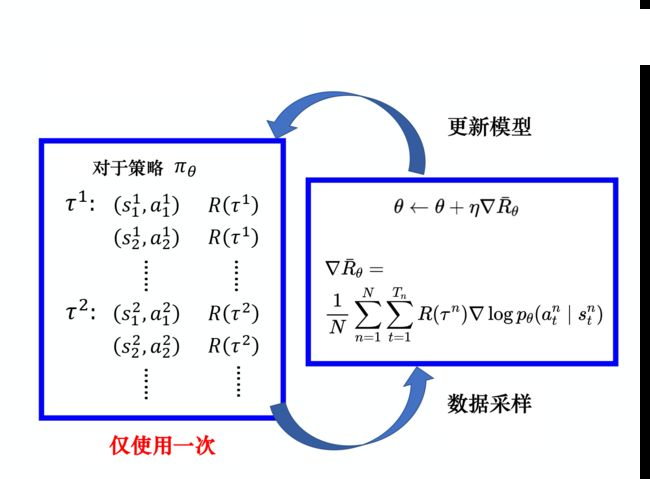
),得到奖励,跳到下一个状态 - 在这样的步骤下,可以使用策略收集一批样本,然后使用梯度下降算法学习这些样本,不过当策略的参数更新后,这些样本不能继续被使用,还要重新使用策略与环境互动收集数据
比如REINFORCE算法便是常见的策略梯度算法,类似下图所示(下图以及本节大部分配图/公式均来自easy RL教程)
接下来,详细阐述。首先,我们已经知道了策略函数可以如此表示:![]()
其中, 可以理解为一个我们所熟知的神经网络
可以理解为一个我们所熟知的神经网络
- 当你对神经网络有所了解的话,你一定知道通过梯度下降求解损失函数的极小值(忘了的,可以复习下:首先通过正向传播产生拟合值,与标签值做“差”计算,产生误差值,然后对误差值求和产生损失函数,最后对损失函数用梯度下降法求极小值,而优化的对象就是神经网络的参数)
- 类比到这个问题上,现在是正向传播产生动作,然后动作在环境中产生奖励值,通过奖励值求和产生评价函数,此时可以针对评价函数做梯度上升(gradient ascent),毕竟能求极小值,便能求极大值,正如误差能最小化,奖励/得分就能最大化
如何评价策略的好坏呢?
假设机器人在策略的决策下,形成如下的运动轨迹(类似你玩三国争霸时,你控制角色在各种不同的游戏画面/场景/状态下作出一系列动作,而当完成了系统布置的某个任务时则会得到系统给的奖励,如此,运动轨迹用 表示,从而表示为一个状态、动作、奖励值不断迁移的过程)

可能有读者注意到了,既然奖励是延后的,
/
后的奖励怎么用
而非
呢,事实上,sutton RL书上用
表示整条轨迹,其实这样更规范,但考虑到不影响大局和下文的推导,本笔记则暂且不细究了
给定智能体或演员的策略参数,可以计算某一条轨迹发生的概率为『轨迹来源于在特定的环境状态下采取特定动作的序列,而特定的状态、特定的动作又分别采样自智能体的动作概率分布 、状态的转换概率分布
、状态的转换概率分布![]() 』
』
其中,有的资料也会把写成为![]() ,但由于毕竟是概率,所以更多资料还是写为
,但由于毕竟是概率,所以更多资料还是写为
那该策略的评价函数便可以设为![]() (以为参数的策略的条件下,产生一系列实际奖励值,且为客观综合起见,最终取的是多个奖励的平均值,即数学期望
(以为参数的策略的条件下,产生一系列实际奖励值,且为客观综合起见,最终取的是多个奖励的平均值,即数学期望 )
)
![]()
多说一句,这个策略评价函数为方便理解也可以称之为策略价值函数,就像上文的状态价值函数、动作价值函数,说白了,评估策略(包括状态、动作)的价值,就是看其因此得到的期望奖励。故从某种意义上讲,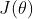 就是
就是
由于每一个轨迹 都有其对应的发生概率,对所有及其出现的概率进行加权并求和出期望值,可得:
![\bar{R}_{\theta}=\sum_{\tau} R(\tau) p_{\theta}(\tau)=\mathbb{E}_{\tau \sim p_{\theta}(\tau)}[R(\tau)]](http://img.e-com-net.com/image/info8/938d3d9fa0604788bc639628f00040ac.gif)
上述整个过程如下图所示
通过上文已经知道,想让奖励越大越好,可以使用梯度上升来最大化期望奖励。而要进行梯度上升,先要计算期望奖励 的梯度。
的梯度。
考虑对 做梯度运算(再次提醒,忘了什么是梯度的,可以通过梯度的Wikipedia,或这个页面:直观形象地理解方向导数与梯度复习下)

其中,只有  与 有关。再考虑到
与 有关。再考虑到 ,可得
,可得

从而进一步转化,可得 ,表示期望的梯度等于对数概率梯度的期望乘以原始函数。
,表示期望的梯度等于对数概率梯度的期望乘以原始函数。
Em,怎么来的?别急,具体推导是
上述推导 总共4个等式3个步骤,其中,第一步 先分母分子都乘以一个
做个简单转换,此处的
然不巧的是,期望值![\mathbb{E}_{\tau \sim p_{\theta}(\tau)}\left[R(\tau) \nabla \log p_{\theta}(\tau)\right]](http://img.e-com-net.com/image/info8/fdcb9beb107e4841834fb49735f687f3.gif) 无法计算,按照蒙特卡洛方法的原则,可以用采样的方式采样 个轨迹并计算每一个的值,再把每一个的值加起来,如此得到梯度,即(
无法计算,按照蒙特卡洛方法的原则,可以用采样的方式采样 个轨迹并计算每一个的值,再把每一个的值加起来,如此得到梯度,即(![]() 上标
上标 代表第条轨迹,而
代表第条轨迹,而![]() 、
、![]() 则分别代表第条轨迹里时刻的动作、状态)
则分别代表第条轨迹里时刻的动作、状态)
任何必要的中间推导步骤咱不能省,大部分文章基本都是一笔带过,但本文为照顾初学者甚至更初级的初学者,
中间的推导过程还是要尽可能逐一说明下:
- 首先,通过上文中关于某一条轨迹
- 然后两边都取对数,可得
由于乘积的对数等于各分量的对数之和,故可得
- 接下来,取梯度可得
上述过程总共4个等式,在从第2个等式到第3个等式的过程中,之所以消掉了
是因为其与




完美!我们可以直观地理解的梯度计算公式

- 即在采样到的数据里面,采样到在某一个状态 要执行某一个动作,
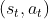 是在整个轨迹的里面的某一个状态和动作的对
是在整个轨迹的里面的某一个状态和动作的对 - 为了最大化奖励,假设在执行,最后发现的奖励是正的,就要增加在 执行 的概率。反之,如果在执行 会导致 的奖励变成负的, 就要减少在 执行 的概率
- 最后,用梯度上升来更新参数,原来有一个参数,把 加上梯度
 ,当然要有一个学习率
,当然要有一个学习率  (类似步长、距离的含义),学习率的调整可用 Adam、RMSProp等方法调整,即
(类似步长、距离的含义),学习率的调整可用 Adam、RMSProp等方法调整,即

有一点值得说明的是...,为了提高可读性,还是举个例子来说明吧。
比如到80/90后上大学时喜欢玩的另一个游戏CF(即cross fire,10多年前我在东华理工的时候也经常玩这个,另一个是DNF),虽然玩的是同一个主题比如沙漠战场,但你每场的发挥是不一样的,即便玩到同一个地方(比如A区埋雷的地方),你也可能会控制角色用不同的策略做出不同的动作,比如
- 在第一场游戏里面,我们在状态
,在状态
。且你在同样的状态
采取
、在状态
采取
等,整场游戏结束以后,得到的奖励是
- 在第二场游戏里面,在状态
采取
,在状态
采取
,采样到的就是
,得到的奖励是
这时就可以把采样到的数据用梯度计算公式把梯度算出来
- 也就是把每一个
,对这个概率取梯度
- 然后在梯度前面乘一个权重
,权重就是这场游戏的奖励,这也是和一般分类问题的区别所在
- 计算出梯度后,就可以通过




4.1.2 避免采样的数据仅能用一次:重要性采样(为采样q解决p从而增加重要性权重)
策略梯度有个问题,在于 是对策略
是对策略  采样的轨迹 求期望。一旦更新了参数,从 变成
采样的轨迹 求期望。一旦更新了参数,从 变成  ,在对应状态s下采取动作的概率
,在对应状态s下采取动作的概率  就不对了,之前采样的数据也不能用了。
就不对了,之前采样的数据也不能用了。
换言之,策略梯度是一个会花很多时间来采样数据的算法,其大多数时间都在采样数据。智能体与环境交互以后,接下来就要更新参数,我们只能更新参数一次,然后就要重新采样数据, 才能再次更新参数。
这显然是非常花时间的,怎么解决这个问题呢?
首先,先来明确两个概念:
- 如果要学习的智能体和与环境交互的智能体是相同的,称之为同策略
- 如果要学习的智能体和与环境交互的智能体不是相同的,称之为异策略
回到策略梯度这个采样到的数据只能使用一次的问题,是否可以把同策略模式转变成异策略模式呢?
- 想要从同策略变成异策略,这样就可以用另外一个策略
 、另外一个演员与环境交互(被固定了),用采样到的数据去训练
、另外一个演员与环境交互(被固定了),用采样到的数据去训练 - 假设我们可以用 采样到的数据去训练,我们可以多次使用采样到的数据,可以多次执行梯度上升,可以多次更新参数, 都只需要用采样到的同一批数据
这个过程具体的做法就叫重要性采样,即通过使用另外一种分布,来逼近所求分布的一种方法。
为备忘,我把2.2.1节得出的
基于重要性采样的原则,我们用另外一个策略 ,它就是另外一个演员,与环境做互动采样数据来训练,从而间接计算
,它就是另外一个演员,与环境做互动采样数据来训练,从而间接计算
但具体怎么操作呢?为说明怎么变换的问题,再举一个例子。
假设有一个函数
,
需要从分布
中采样,应该如何怎么计算()的期望值呢?
如果分布
,然后全都代入到
当不能在分布
中去采样数据时(
首先,期望值
的另一种写法是
,对其进行变换,如下式所示,
整理下可得(左边是分布
如此,便就可以从
,再取期望值。所以就算我们不能从
以后的期望值。
![\mathbb{E}_{x \sim p}[f(x)] \approx \frac{1}{N} \sum_{i=1}^N f(x^i)](http://img.e-com-net.com/image/info8/f1596b9fd65c4e679818387e3fccc861.gif)
![\int f(x) p(x) \mathrm{d}x=\int f(x) \frac{p(x)}{q(x)} q(x) \mathrm{d}x=\mathbb{E}_{x \sim q}[f(x){\frac{p(x)}{q(x)}}]](http://img.e-com-net.com/image/info8/29fe51004a124d898f257b01795a929b.gif)
![\mathbb{E}_{x \sim p}[f(x)]=\mathbb{E}_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right]](http://img.e-com-net.com/image/info8/b57486061ec0411f9314e406835c6179.gif)
类似的,当转用去采样数据训练后,得在
- 的基础上补上一个重要性权重:
 ,这个重要性权重针对某一个轨迹用算出来的概率除以这个轨迹用
,这个重要性权重针对某一个轨迹用算出来的概率除以这个轨迹用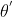 算出来的概率
算出来的概率 - 注意,上面例子中的/与此处的/
 没有任何联系,前者只是为了说明重要性权重的两个普通的分布而已
没有任何联系,前者只是为了说明重要性权重的两个普通的分布而已
最终加上重要性权重之后,可得
![\nabla \bar{R}_{\theta}=\mathbb{E}_{\tau \sim p_{\theta^{\prime}(\tau)}}\left[\frac{p_{\theta}(\tau)}{p_{\theta^{\prime}}(\tau)} R(\tau) \nabla \log p_{\theta}(\tau)\right]](http://img.e-com-net.com/image/info8/4fc5d3c9268a4824a7a0bf2947034dcb.gif)
怎么来的?完整推导如下
4.1.3 实现技巧:为避免奖励总为正增加基线——优势函数
梯度的计算好像差不多了?但实际在做策略梯度的时候,并不是给整个轨迹都一样的分数,而是每一个状态-动作的对会分开来计算,但通过蒙特卡洛方法进行随机抽样的时候,可能会出问题,比如在采样一条轨迹时可能会出现
- 问题1:所有动作均为正奖励
- 问题2:出现比较大的方差(另,重要性采样时,采样的分布与当前分布之间也可能会出现比较大的方差,具体下一节详述)
对于第一个问题,举个例子,比如在某一一个状态,可以执行的动作有a、b、c,但我们可能只采样到动作b或者只采样到动作c,没有采样到动作a
- 但不管采样情况如何,现在所有动作的奖励都是正的,所以采取a、b、 c的概率都应该要提高
- 可实际最终b、c的概率按预期提高了,但因为a没有被采样到,所以a的概率反而下降了
- 然问题是a不一定是一个不好的动作,它只是没有被采样到

为了解决奖励总是正的的问题,也为避免方差过大,需要在之前梯度计算的公式基础上加一个基准线 『此指的baseline,非上面例子中的b,这个所谓的基准线可以是任意函数,只要不依赖于动作即可』
『此指的baseline,非上面例子中的b,这个所谓的基准线可以是任意函数,只要不依赖于动作即可』

上面说可以是任意函数,这个“任意”吧,对初学者而言可能跟没说一样,所以到底该如何取值呢
- 有一种选择是使用轨迹上的奖励均值,即
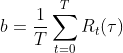
从而使得 有正有负
有正有负
当 大于平均值时,则为正,则增加该动作的概率
大于平均值时,则为正,则增加该动作的概率
当小于平均值时,则为负,则降低该动作的概率
如此,对于每条轨迹,平均而言,较好的50%的动作将得到奖励,避免所有奖励均为正或均为负,同时,也减少估计方差 - 还可以是状态价值函数
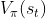
可曾还记得2.1节介绍过的所谓Actor-Criti算法(一般被翻译为演员-评论家算法)
Actor学习参数化的策略即策略函数,Criti学习值函数用来评估状态-动作对,然后根据评估结果选择动作
当然,Actor-Criti本质上是属于基于策略的算法,毕竟算法的目标是优化一个带参数的策略,只是会额外学习价值函数,从而帮助策略函数更好的学习,而学习优势函数的演员-评论家算法被称为优势演员-评论家(Advantage Actor-Criti,简称A2C)算法
而这个一般被定义为优势函数 ,再考虑到评估动作的价值,就看其因此得到的期望奖励,故一般有
,再考虑到评估动作的价值,就看其因此得到的期望奖励,故一般有![]() ,此举意味着在选择一个动作时,根据该动作相对于特定状态下其他可用动作的执行情况来选择,而不是根据该动作的绝对值(由函数估计)
,此举意味着在选择一个动作时,根据该动作相对于特定状态下其他可用动作的执行情况来选择,而不是根据该动作的绝对值(由函数估计)
总之, 要估测的是在状态
要估测的是在状态 采取动作
采取动作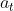 是好的还是不好的:即如果是正的,就要增加概率;如果是负的,就要减少概率
是好的还是不好的:即如果是正的,就要增加概率;如果是负的,就要减少概率
最终在更新梯度的时候,如下式所示『我们用演员去采样出跟,采样出状态跟动作的对 ,计算这个状态跟动作对的优势』
,计算这个状态跟动作对的优势』
![\mathbb{E}_{\left(s_{t}, a_{t}\right) \sim \pi_{\theta}}\left[A^{\theta}\left(s_{t}, a_{t}\right) \nabla \log p_{\theta}\left(a_{t}^{n} | s_{t}^{n}\right)\right]](http://img.e-com-net.com/image/info8/ab94bf54d94a4eb0b1b24fcf9b7e6cd7.gif)
由于是演员与环境交互的时候计算出来的,基于重要性采样的原则,当从 换到 的时候,就需要在
基础上, 变换成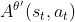 ,一变换便得加个重要性权重(即把、用采样出来的概率除掉 、用采样出来的概率),公式如下『Easy RL纸书第1版上把下面公式中的写成了』
,一变换便得加个重要性权重(即把、用采样出来的概率除掉 、用采样出来的概率),公式如下『Easy RL纸书第1版上把下面公式中的写成了』
接下来,我们可以拆解 和
和 ,即
,即
于是可得公式
这里需要做一件事情,假设模型是的时候,我们看到的概率,跟模型是的时候,看到的概率是差不多的,即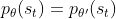 。
。
为什么可以这样假设呢?一种直观的解释就是
很难算,这一项有一个参数
但是
是很好算,我们有
。
所以,实际上在更新参数的时候,我们就是按照下式来更新参数:
从而最终可以从梯度 来反推目标函数,当使用重要性采样的时候,要去优化的目标函数如下式所示,把它记
来反推目标函数,当使用重要性采样的时候,要去优化的目标函数如下式所示,把它记
终于大功告成!
4.1.4 基于信任区域的TRPO:加进KL散度解决两个分布相差大或步长难以确定的问题
好巧不巧,看似大功告成了,但重要性采样还是有个问题。具体什么问题呢,为更好的说明这个问题,我们回到上文的那个例子中。
还是那两个分布:
比如,虽然上述公式成立,但如果不是计算期望值,而是计算方差,
和
是不一样的。因为两个随机变量的平均值相同,并不代表它们的方差相同
此话怎讲?以下是推导过程:
将
则分别可得(且考虑到不排除会有比初级更初级的初学者学习本文,故把第二个公式拆解的相对较细)
上述两个公式前后对比,可以很明显的看出,后者的第一项多乘了
,如果
的方差就会很大。
![\operatorname{Var}[X]=E\left[X^{2}\right]-(E[X])^{2}](http://img.e-com-net.com/image/info8/016f5f73e7ea4d28b861588f5e65844b.gif)
![\operatorname{Var}_{x \sim p}[f(x)]=\mathbb{E}_{x \sim p}\left[f(x)^{2}\right]-\left(\mathbb{E}_{x \sim p}[f(x)]\right)^{2}](http://img.e-com-net.com/image/info8/78938a7069ac4c4fb08e684593424584.gif)
所以结论就是,如果我们只要对分布采样足够多次,对分布采样足够多次,得到的期望值会是一样的。但是如果采样的次数不够多,会因为它们的方差差距可能是很大的,所以就可能得到差别非常大的结果。
这意味着什么呢,意味着我们目前得到的这个公式里
如果  与
与  相差太多,即这两个分布相差太多,重要性采样的结果就会不好。怎么避免它们相差太多呢?这就是TRPO算法所要解决的。
相差太多,即这两个分布相差太多,重要性采样的结果就会不好。怎么避免它们相差太多呢?这就是TRPO算法所要解决的。
2015年John Schulman等人提出了信任区域策略优化(Trust Region Policy Opimization,简称TRPO),表面上,TRPO的出现解决了同时解决了两个问题,一个是解决重要性采样中两个分布差距太大的问题,一个是解决策略梯度算法中步长难以确定的问题
- 关于前者,在1.2.2节得到的目标函数基础上(下图第一个公式),增加了一个KL散度约束(如下图第二个公式)
至此采样效率低效的问题通过重要性采样(重要性权重)、以及增加KL散度约束解决了KL散度(KL divergence),也称相对熵,而相对熵 = 交叉熵 - shannon熵,其衡量的是两个数据分布
和之间的差异
下图左半边是一组原始输入的概率分布曲线
,与之并列的是重构值的概率分布曲线 ,下图右半边则显示了两条曲线之间的差异
,下图右半边则显示了两条曲线之间的差异
- 关于后者,具体而言,当策略网络是深度模型时,沿着策略梯度更新参数,很有可能由于步长太长,策略突然显著变差,进而影响训练效果
这是1.2.1节,我们已经得到的策略梯度计算、策略梯度更新公式如下(别忘了,学习率
类似步长、距离的含义)分别如下对这个问题,我们考虑在更新时找到一块信任区域(trust region),在这个区域上更新策略时能够得到安全性保证,这就是TRPO算法的主要思想
本质上,其实这两个问题是同一个问题(简言之,避免两个分布相差大即意味着避免步长过大)。举个例子,比如爬两面都是悬崖的山,左右脚交替往前迈步,无论哪只脚向前迈步都是一次探索
- 为尽快到达山顶且不掉下悬崖,一方面 你会选择最陡峭的方向,二方面 你会用目光选择一片信任区域,从而尽量远离悬崖边,在信任区域中,首先确定要探索的最大步长(下图的黄色圆圈),然后找到最佳点并从那里继续搜索
- 好,现在问题的关键变成了,怎么确定每一步的步长呢?如果每一步的步长太小,则需要很长时间才能到达峰值,但如果步长太大,就会掉下悬崖(像不像两个分布之间差距不能太大)
- 具体做法是,从初始猜测开始可选地,然后动态地调整区域大小。例如,如果新策略和当前策略的差异越来越大,可以缩小信赖区域。怎么实现?KL散度约束!

总之,TRPO就是考虑到连续动作空间无法每一个动作都搜索一遍,因此大部分情况下只能靠猜。如果要猜,就最好在信任域内部去猜。而TRPO将每一次对策略的更新都限制了信任域内,从而极大地增强了训练的稳定性。
至此,PG算法的采样效率低下、步长难以确定的问题都被我们通过TRPO给解决了。但TRPO的问题在哪呢?
TRPO的问题在于把 KL 散度约束当作一个额外的约束,没有放在目标里面,导致TRPO很难计算,总之因为信任域的计算量太大了,John Schulman等人于2017年又推出了TRPO的改进算法:PPO
4.2 近端策略优化PPO:解决TRPO的计算量大的问题
4.2.1 什么是近端策略优化PPO与PPO-penalty
如上所述,PPO算法是针对TRPO计算量的大的问题提出来的,正因为PPO基于TROP的基础上改进,故PPO也解决了策略梯度不好确定学习率Learning rate (或步长Step size) 的问题。毕竟通过上文,我们已经得知
- 如果 step size 过大, 学出来的 Policy 会一直乱动,不会收敛;但如果 Step Size 太小,想完成训练,我们会等到地老天荒
- 而PPO 利用 New Policy 和 Old Policy 的比例,限制了 New Policy 的更新幅度,让策略梯度对稍微大点的 Step size 不那么敏感
具体做法是,PPO算法有两个主要的变种:近端策略优化惩罚(PPO-penalty)和近端策略优化裁剪(PPO-clip),其中PPO-penalty和TRPO一样也用上了KL散度约束。
近端策略优化惩罚PPO-penalty的流程如下
-
首先,明确目标函数,通过上节的内容,可知咱们需要优化
,让其最大化 -
接下来,先初始化一个策略的参数
,在每一个迭代里面,我们用前一个训练的迭代得到的actor的参数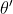 与环境交互,采样到大量状态-动作对, 根据交互的结果,估测
与环境交互,采样到大量状态-动作对, 根据交互的结果,估测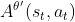
- 由于目标函数牵涉到重要性采样,而在做重要性采样的时候,不能与相差太多,所以需要在训练的时候加个约束,这个约束就好像正则化的项一样,是 与 输出动作的 KL散度,用于衡量 与 的相似程度,我们希望在训练的过程中,学习出的 与 越相似越好
所以需要最后使用 PPO 的优化公式:
当然,也可以把上述那两个公式合二为一『如此可以更直观的看出,PPO-penalty把KL散度约束作为惩罚项放在了目标函数中(可用梯度上升的方法去最大化它),此举相对TRPO减少了计算量』
上述流程有一个细节并没有讲到,即 是怎么取值的呢,事实上,是可以动态调整的,故称之为自适应KL惩罚(adaptive KL penalty),具体而言
是怎么取值的呢,事实上,是可以动态调整的,故称之为自适应KL惩罚(adaptive KL penalty),具体而言
- 先设一个可以接受的 KL 散度的最大值

假设优化完以后,KL 散度值太大导致 ,意味着 与差距过大(即学习率/步长过大),也就代表后面惩罚的项
,意味着 与差距过大(即学习率/步长过大),也就代表后面惩罚的项 惩罚效果太弱而没有发挥作用,故增大惩罚把增大
惩罚效果太弱而没有发挥作用,故增大惩罚把增大 - 再设一个 KL 散度的最小值
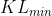
如果优化完以后,KL散度值比最小值还要小导致 ,意味着 与 差距过小,也就代表后面这一项的惩罚效果太强了,我们怕它只优化后一项,使与 一样,这不是我们想要的,所以减小惩罚即减小
,意味着 与 差距过小,也就代表后面这一项的惩罚效果太强了,我们怕它只优化后一项,使与 一样,这不是我们想要的,所以减小惩罚即减小
总之,近端策略优化惩罚可表示为
4.2.2 PPO算法的另一个变种:近端策略优化裁剪PPO-clip
如果觉得计算 KL散度很复杂,则还有一个 PPO2算法,即近端策略优化裁剪PPO-clip。近端策略优化裁剪的目标函数里面没有 KL 散度,其要最大化的目标函数为(easy RL上用![]() 代替
代替![]() ,还有的书用
,还有的书用![]() 代替
代替![]() ,为上下文统一需要,本笔记的文字部分统一用
,为上下文统一需要,本笔记的文字部分统一用![]() )
)
整个目标函数在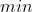 这个大括号里有两部分,最终对比两部分那部分更小,就取哪部分的值,这么做的本质目标就是为了让和
这个大括号里有两部分,最终对比两部分那部分更小,就取哪部分的值,这么做的本质目标就是为了让和 可以尽可能接近,不致差距太大。
可以尽可能接近,不致差距太大。
换言之,这个裁剪算法和KL散度约束所要做的事情本质上是一样的,都是为了让两个分布之间的差距不致过大,但裁剪算法相对好实现,别看看起来复杂,其实代码很好写
// ratios即为重要性权重,exp代表求期望,括号里的old_log_probs代表用于与环境交互的旧策略
ratios = torch.exp(log_probs - old_log_probs)
// 分别用sur_1、sur_2来计算公式的两部分
// 第一部分是重要性权重乘以优势函数
sur_1 = ratios * advs
// 第二部分是具体的裁剪过程
sur_2 = torch.clamp(ratios, 1 - clip_eps, 1 + clip_eps) * advs
// 最终看谁更小则取谁
clip_loss = -torch.min(sur_1,sur_2).mean()回到公式,公式的第一部分我们已经见过了,好理解,咱们来重点分析公式的第二部分
![]()
- 首先是
 括号里的部分,如果用一句话简要阐述下其核心含义就是:如果和之间的概率比落在范围
括号里的部分,如果用一句话简要阐述下其核心含义就是:如果和之间的概率比落在范围 和
和 之外,
之外,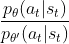 将被剪裁,使得其值最小不小于,最大不大于
将被剪裁,使得其值最小不小于,最大不大于
- 然后是括号外乘以,如果大于0,则说明这是好动作,需要增大,但最大不能超过;如果小于0,则说明该动作不是好动作,需要减小,但最小不能小过
最后把公式的两个部分综合起来,针对整个目标函数
- 如果
则相当于第二部分是
取更小值当然是- 如果
则相当于第二部分是
取更小值当然是原函数值:
反之,如果
- 如果
则相当于第二部分是
取更小值当然是原函数的值: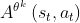
- 如果
则相当于第二部分是
取更小值当然是


的..
后记
1.6日决定只是想写个ChatGPT通俗导论,但为了讲清楚其中的PPO算法,更考虑到之后还会再写一篇强化学习极简入门,故中途花了大半时间去从头彻底搞懂RL,最终把网上关于RL的大部分中英文资料都翻遍之外(详见参考文献与推荐阅读),还专门买了这几本书以系统学习
- 第1本,《白话强化学习与pytorch》,偏通俗,对初学者最友好,可以最快最短时间内入门RL,缺点是部分内容稍感混乱,且对部分前沿/细节比如PPO算法阐述不足,毕竟19年出版的了
- 第2本,《Eazy RL强化学习教程》,基于台大李宏毅等人的公开课,虽有不少小问题,但对于初学入门不错的
- 第3本,《动手学强化学习》,张伟楠等人著,概念讲解、公式定义都很清晰,且配套代码实现,当然 如果概念讲解能更细致则会对初学者更友好
- 第4本,《深度强化学习》,王树森等人著,偏原理讲解(无代码),此书对于已对RL有一定了解的是不错的选择
- 第5本,《强化学习2》,权威度最高但通俗性不足,当然 也看人,没入门之前你会觉得此书晦涩,入门之后你会发现经典还是经典、不可替代,另书之外可配套七月的强化学习2带读课
- 第6本,《深度强化学习:基于Python的理论与实践》,理论讲的挺清楚,代码实践也不错
- 第7本,《强化学习(微课版)》,这本书是作为RL教材出版的,所以有教材的特征,即对一些关键定理会举例子展示实际计算过程,比如马尔可夫决策的计算过程,对初学者友好
总之,RL里面的概念和公式很多(相比ML/DL,RL想要机器/程序具备更好的自主决策能力),而
- 一方面,绝大部分的资料没有站在初学者的角度去通俗易懂化、没有把概念形象具体化、没有把公式拆解举例化(如果逐一做到了这三点,何愁文章/书籍/课程不通俗)
而我自己也经常思考为何通俗易懂的文章不多见,思来想去,想必原因至少包括这三点:
1 写通俗,需要花费更多的时间/精力
2 每个作者水平不一样,读者水平更各不相同,不好定义到底哪些背景知识需要交代完全,很容易习惯性自以为读者应该懂这懂那,而如果认为读者什么都不懂,则是鸿篇巨制
3 越深入细节 资料越匮乏,从而越需要系统研究后 再写清楚 - 二方面,不够通俗的话,则资料一多,每个人的公式表达习惯不一样便会导致各种形态,虽说它们最终本质上都是一样的,可当初学者还没有完全入门之前,就不一定能一眼看出背后的本质了,然后就不知道该以哪个为准,从而丧失继续前进的勇气(这种情况下,要么硬着头皮继续啃 可能会走弯路,要么通过比如七月在线的课程问老师或人 提高效率少走弯路)
比如一个小小的策略梯度的计算公式会有近10来种表达,下面特意贴出其中6种(第2-4种考虑了折扣因子的情况,其他种情况则没考虑折扣因子的情况,更多对比可以参看参考文献46),供读者辨别
第一种,本笔记和Easy RL中用的第二种,Sutton强化学习《Reinforcement Learning: An Introduction》第一版中用的
![\nabla_{\theta}J(\pi_\theta)=\sum_{s}^{}d^\pi (s) \sum_{a}^{}\nabla_{\theta} \pi _\theta (a|s)Q^\pi (s,a)= E_\pi [\gamma^t \nabla_{\theta}log\pi_\theta (A_t|S_t)Q^\pi(S_t,A_t)]](http://img.e-com-net.com/image/info8/3f13164733bf454db6d0b292107e5a71.gif)
其中
 叫做discounted state distribution
叫做discounted state distribution第三种,David sliver在2014年的《Deterministic Policy Gradient Algorithm》论文中用的
![\nabla_\theta J(\pi _\theta ) = \int_{S}^{}\rho ^\pi (s) \int_{A}^{}\nabla_\theta \pi _\theta(a|s)Q^\pi(s,a) =E_{s\sim\rho ^\pi,a\sim\pi_\theta }[\nabla_\theta log\pi _\theta(a|s)Q^\pi (s,a)]](http://img.e-com-net.com/image/info8/39e3cd1705954c6b8f12c4c708b947d8.gif)
其中,
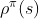 与上述
与上述 相同,都是discounted state distribution。
相同,都是discounted state distribution。第四种,肖志清《强化学习:原理与Python实现》中用的
![\nabla_\theta J(\pi _\theta )= E[\sum_{t=0}^{\infty } \gamma ^t \nabla_\theta log\pi _\theta (A_t|S_t)Q^\pi (S_t,A_t)]](http://img.e-com-net.com/image/info8/2921dff7bfa74bbca3f1eba2d3f5e738.gif)
第五种,Sutton强化学习在2018年的第二版中用的
![\nabla_\theta J(\pi_\theta)\propto\sum_{S}^{}\mu ^\pi(s)\sum_{a}^{}\nabla_\theta \pi _\theta(a|s)Q^\pi(s,a)= E_\pi [\nabla_\theta log\pi _\theta (A_t|S_t)Q^\pi (S_t,A_t)]](http://img.e-com-net.com/image/info8/e0b2cbac55ce4841914bf7707420c9d0.gif)
其中,
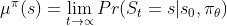 是stationary distribution (undiscounted state distribution)
是stationary distribution (undiscounted state distribution)第六种,Open AI spinning up教程中用的
![\nabla_\theta J(\pi_\theta)= E_{(\tau \sim\pi)} [\sum_{t=0}^{T}\nabla_\theta log\pi _\theta (a_t|s_t)Q^\pi(s_t,a_t)]](http://img.e-com-net.com/image/info8/3f0a5561ffd84d91a17f60514e2b5592.gif)
参考文献与推荐阅读
- 关于强化学习入门的一些基本概念
- 《白话强化学习与Pytorch》,此书让我1.6日起正式开启RL之旅,没看此书之前,很多RL资料都不好看懂
- 《Eazy RL强化学习教程》,基于台大李宏毅和UCLA周博磊等人的RL公开课所编著,其GitHub、其在线阅读地址
- 《动手学强化学习》,张伟楠等人著
- 台大李宏毅RL公开课,这是其:视频/PPT/PDF下载地址
- UCLA周博磊RL公开课,这是其:GitHub地址
- 关于Q-leaning的几篇文章:1 如何用简单例子讲解 Q - learning 的具体过程? 2 莫烦:什么是 Q-Learning
- AlphaGo作者之一David Silver主讲的增强学习笔记1、笔记2,另附其讲授的《UCL Course on RL》的课件地址
-
huggingface的两篇RL教程:An Introduction to Deep Reinforcement Learning、GitHub:The Hugging Face Deep Reinforcement Learning Course
- TRPO原始论文:Trust Region Policy Optimization
- PPO原始论文:Proximal Policy Optimization Algorithms
- PPO算法解读(英文2篇):解读1 RL — Proximal Policy Optimization (PPO) Explained、解读2 Proximal Policy Optimization (PPO)
- PPO算法解读(中文3篇):Easy RL上关于PPO的详解、详解近端策略优化、详解深度强化学习 PPO算法
- PPO算法实现:GitHub - lvwerra/trl: Train transformer language models with reinforcement learning.
- 如何选择深度强化学习算法?MuZero/SAC/PPO/TD3/DDPG/DQN/等
- 如何通俗理解隐马尔可夫模型HMM?
- HMM学习最佳范例
- 强化学习中“策略梯度定理”的规范表达、推导与讨论
- 强化学习——时序差分算法
- KL-Divergence详解
- 《强化学习(微课版)》,清华大学出版社出版
- 使用蒙特卡洛计算定积分(附Python代码)
附录:修改/完善记录
RL里的细节、概念、公式繁多,想完全阐述清楚是不容易的,以下是自从23年1.16日以来的修改、完善记录:
- 1.16日,第一轮修改/完善
修正几个笔误,且考虑到不排除会有比初级更初级的初学者阅读本文,补充部分公式的拆解细节 - 1.17日,先后修正了2.2节重要性采样与重要性权重的部分不准确的描述、修正个别公式的笔误,以及补充1.4.2中关于PPO-clip的细节阐述、优化第四部分的相关描述
- 1.18日,为措辞更准确,优化1.2.5节“基于信任区域的TRPO:通过KL散度解决两个分布相差大和步长难以确定的问题”的相关描述
- 1.19日,为让读者理解起来更一目了然
优化1.3.1节中关于什么是近端策略优化PPO的描述
优化1.3.2节中关于“近端策略优化惩罚PPO-penalty关于自适应KL惩罚(adaptive KL penalty)”的描述
拆解细化关于的推导过程
补充说明对优势函数 的介绍 - 1.20日,第五轮修改/完善
通过LaTeX重新编辑部分公式,以及补充说明1.2.1节中关于某一条轨迹发生概率的定义 - 1.21日(大年三十),新增对蒙特卡洛方法的介绍,以及新增中基线的定义,且简化2.1.1节中关于强化学习过程的描述
- 1.22日,为严谨起见改进第二部分中对回报、状态价值函数、动作价值函数、马尔可夫决策、策略评价函数的描述,并纠正个别公式的笔误
- 1.23日,梳理1.1节的整体内容结构和顺序脉络,以让逻辑更清晰,补充了MDP的整个来龙去脉(包括且不限于马尔可夫过程、马尔可夫奖励、马尔可夫决策以及贝尔曼方程)
- 1.25日,为方便对高数知识有所遗忘的同学更顺畅的读懂本文,新增对导数、期望的简单介绍(后汇总至概率统计极简入门笔记里),以及补充对 中基线的定义的介绍
- 1.26日,第十轮修改/完善
优化改进2.2节关于策略梯度的梯度计算的整个推导过程,以让逻辑更清晰 - 1.27日,优化关于增加基线baseline和优势函数等内容的描述
在后记里补充策略梯度计算公式的5种其它表达
优化关于“近端策略优化惩罚PPO-penalty的流程”的描述 - 1.28日,新增对MC和TD方法各自的阐述及两者的对比,优化对KL散度定义的描述,新增近端策略优化裁剪PPO-clip的关键代码
- 1.30日,新增马尔可夫决策的贝尔曼方程以及对应的计算图解,以方便一目了然
简单阐述了下GPT2相比GPT的结构变化,以及完善丰富了下文末的参考文献与推荐阅读,比如增加图解GPT2、图解GPT3的参考文献 - 1.31日,为行文严谨,针对1.1.2节中关于马尔可夫奖励的部分
规范统一个别公式的大小写表示
补充状态下奖励函数的定义
修正回报公式的笔误
修正状态价值函数公式的笔误
且为形象起见,新增一个“吃饭-抽烟/剔牙”的例子以展示利用贝尔曼方程计算的过程
此外,且为通俗细致,针对1.1.3节中关于马尔科夫决策的部分
拆解状态价值函数、动作价值函数的定义公式,拆解关于状态价值函数和动作价值函数之间联系的推导过程 - 2.1日,第十五轮修改/完善
参考sutton RL一书,补充对奖励函数、回报公式、轨迹定义的公式表达规范的说明 - 2.12日,为更一目了然,新增对状态价值函数的贝尔曼方程的解释,与例子说明
- 2.13日,开始完善动态规划一节的内容,然后发现之前写的一篇关于DP的博客不够通俗,故本周得先修订下那篇旧文,以通俗理解DP
- 2.15日,基于已经修订好的DP旧文,完善本文对DP算法的阐述
并修正第一部分里关于“什么是强化学习”的不够准确的表述 - 2.16日,完善对蒙特卡洛方法和时序差分法的介绍,并重点对比DP、MC、TD三者的区别与联系