NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction 论文笔记
文章目录
- Related Works
- 方法
-
- Rendering Procedure
-
- 场景表示 Scene Representation
- 渲染 Rendering
- 权重函数 weight function
- Discretization
- Training
-
- 分层采样 Hierarchical Sampling
- 实现细节
- 实验
-
-
- Ablation study
- Thin structures
-
近来非常火热的 Neural Implicit Function:
- Volume Rendering based: NeRF 结合poisson surface reconstruction (insufficient surface constraints)
- Surface Rendering based: IDR(require foreground mask as supervision; trapped in local minima; struggle with reconstruction of objects with severe self-occlusion or thin structures)
NeuS 使用 SDF 函数的水平集 (zero-level set of a signed distance function (SDF)) 表示物体的表面,引入SDF导出的密度分布,采用体渲染 volume rendering 训练一个新的神经SDF表示方法。
NeuS 在复杂几何形状和自遮挡情况下都有效,取得了SOTA的效果,重建效果超过 了NeRF 和 IDR,以及同期的 UNISURF。
体渲染可以处理突然的深度变化,但是重建结果的噪声较大。

Related Works
- Traditional multi-view 3D reconstruction
- Point- and surface-based reconstruction methods
- estimate the depth map of each pixel by exploiting inter-image photometric consistency
- then fuse the depth maps into a global dense point cloud
- the surface reconstruction is usually done as a post processing with methods like screened Poisson surface reconstruction
- the reconstruction quality heavily relies on the quality of correspondence matching, and the difficulties in matching correspondence for objects without rich textures often lead to severe artifacts and missing parts in the reconstruction results
- volumetric reconstruction methods
- circumvent the difficulty of explicit correspondence matching by estimating occupancy and color in a voxel grid from multi-view images and evaluating the color consistency of each voxel
- Due to limited achievable voxel resolution, these methods cannot achieve high accuracy
- Point- and surface-based reconstruction methods
- Neural Implicit Representation applications
- shape representation
- novel view synthesis
- multi-view 3D reconstruction
方法
给定物体的照片 { I k } \{I_k\} {Ik} ,重建物体的表面 S S S。物体表面用signed distance function(SDF)表示,采用MLP编码。
Rendering Procedure
场景表示 Scene Representation
物体形状和颜色分别用SDF场,颜色场函数表示,这两个函数都采用 MLP 编码
- f : R 3 → R f: \mathbb{R}^{3} \rightarrow \mathbb{R} f:R3→R 把空间点 x ∈ R 3 \mathbf x \in \mathbb{R}^{3} x∈R3 映射到它距离物体的signed distance
- 物体的表面 S S S 就用SDF的0-水平集表示: S = { x ∈ R 3 ∣ f ( x ) = 0 } S = \{\mathbf x \in \mathbb{R}^{3} | f(\mathbf x)=0\} S={x∈R3∣f(x)=0}
- c : R 3 × S 2 → R 3 c: \mathbb{R}^{3} \times \mathbb{S}^{2} \rightarrow \mathbb{R}^{3} c:R3×S2→R3 将空间点的颜色编码成位置 x ∈ R 3 \mathbf x \in \mathbb{R}^{3} x∈R3 和视角方向 v ∈ S 2 \mathbf v \in \mathbb{S}^{2} v∈S2 的函数
这里引入概率密度函数 S-density: ϕ ( f ( x ) ) \phi(f(\mathbf x)) ϕ(f(x)) ,其中 ϕ s ( x ) = s e − s x / ( 1 + e − s x ) 2 \phi_{s}(x)=s e^{-s x} /\left(1+e^{-s x}\right)^{2} ϕs(x)=se−sx/(1+e−sx)2,叫做 *logistic density distribution,*是 Φ s ( x ) = ( 1 + e − s x ) − 1 \Phi_{s}(x)=\left(1+e^{-s x}\right)^{-1} Φs(x)=(1+e−sx)−1 的导数。标准差是 1 / s 1/s 1/s,以 0 为对称轴。当网络收敛时,1/s 会逼近0。这里的概率密度函数可以用其他关于0对称的函数替代,这里是为了计算简便。
渲染 Rendering
为了学习 SDF 和 颜色场的MLP参数,采用 volume rendering。
给定一个像素点,定义对应的光线 { p ( t ) = o + t v ∣ t ≥ 0 } \{ \mathbf p(t) = \mathbf o + t \mathbf v | t \geq 0\} {p(t)=o+tv∣t≥0}, o \mathbf o o 是相机中心, v \mathbf v v 是光线的单位向量,该点的颜色用积分表示为:
C ( o , v ) = ∫ 0 + ∞ w ( t ) c ( p ( t ) , v ) d t C(\mathbf{o}, \mathbf{v})=\int_{0}^{+\infty} w(t) c(\mathbf{p}(t), \mathbf{v}) \mathrm{d} t C(o,v)=∫0+∞w(t)c(p(t),v)dt
其中, w ( t ) w(t) w(t)表示空间点 p ( t ) \mathbf p(t) p(t) 在观察方向 v \mathbf v v 的权重,并且满足 w ( t ) ≥ 0 w(t) \geq 0 w(t)≥0 且 ∫ 0 + ∞ w ( t ) d t = 1 \int_{0}^{+\infty} w(t) \mathrm d t =1 ∫0+∞w(t)dt=1 。
权重函数 weight function
训练出准确的SDF表达的关键就在于通过SDF函数 f f f 得到合适的权重函数 w ( t ) w(t) w(t) , w ( t ) w(t) w(t)有如下要求:
- Unbiased: w ( t ) w(t) w(t) 需要在相机光线与物体表面相交点 p ( t ∗ ) \mathbf p (t^*) p(t∗) (即 f ( p ( t ∗ ) ) = 0 f(\mathbf p (t^*))=0 f(p(t∗))=0)达到局部最大值。即表面附近的点对最终结果的贡献最大
- Occlusion-aware: 当两个点有同样的SDF值的时候,靠近相机的点的权重应该更大。即当经过多个表面时,最靠近的表面影响最大
根据NeRF中标准的体渲染公式,权重公式定义为:
w ( t ) = T ( t ) σ ( t ) , where T ( t ) = exp ( − ∫ 0 t σ ( u ) d u ) w(t)=T(t) \sigma(t), \quad \text{where} \ T(t) = \exp \left(-\int_{0}^{t} \sigma(u) d u\right) w(t)=T(t)σ(t),where T(t)=exp(−∫0tσ(u)du)
σ ( t ) \sigma(t) σ(t) 是 volume density 体密度, T ( t ) T(t) T(t) 是accumulated transmittance 累积透射比,表示这一段没有击中任何粒子的概率。
Naive Solution
现在最简单的想法是把 σ ( t ) \sigma (t) σ(t) 设为S-density,即 σ ( t ) = ϕ ( f ( p ( t ) ) ) \sigma (t) = \phi(f(\mathbf p(t))) σ(t)=ϕ(f(p(t)))。虽然是 occlusion-aware 的,但 w ( t ) w(t) w(t) 在光线到达交界点之前就达到了局部最大。
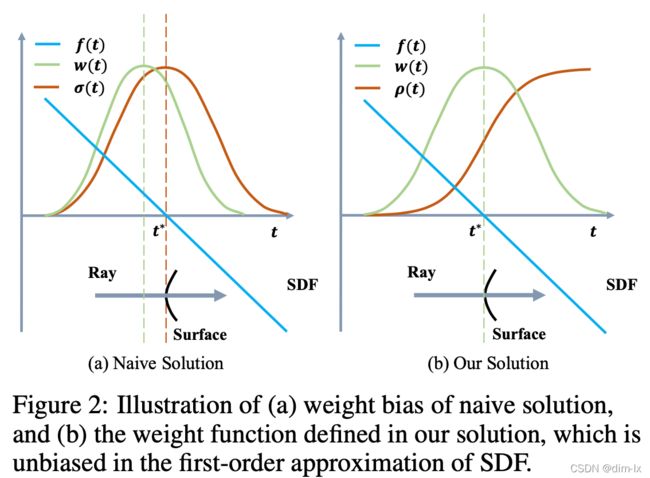
Our Solution
首先介绍直接把normalized S-density 作为权重的方法,这种方法满足unbiased,但是无法处理穿过多个表面的情况。
w ( t ) = ϕ s ( f ( p ( t ) ) ) ∫ 0 + ∞ ϕ s ( f ( p ( u ) ) ) d u w(t)=\frac{\phi_{s}(f(\mathbf{p}(t)))}{\int_{0}^{+\infty} \phi_{s}(f(\mathbf{p}(u))) \mathrm{d} u} w(t)=∫0+∞ϕs(f(p(u)))duϕs(f(p(t)))
仿照体渲染公式,定义 opaque density function ρ ( t ) \rho(t) ρ(t),代替标准体渲染中的 σ \sigma σ。权重方程表示为:
w ( t ) = T ( t ) ρ ( t ) , where T ( t ) = exp ( − ∫ 0 t ρ ( u ) d u ) w(t)=T(t) \rho(t), \quad \text { where } T(t)=\exp \left(-\int_{0}^{t} \rho(u) \mathrm{d} u\right) w(t)=T(t)ρ(t), where T(t)=exp(−∫0tρ(u)du)
根据几何关系, f ( p ( t ) ) = ∣ cos ( θ ) ∣ ⋅ ( t − t ∗ ) f(\mathbf p (t)) = |\cos (\theta)| \cdot\left(t-t^{*}\right) f(p(t))=∣cos(θ)∣⋅(t−t∗),其中 f ( p ( t ∗ ) ) = 0 f(\mathbf p (t^*))=0 f(p(t∗))=0, θ \theta θ 是视角方向与物体表面法向量 n \mathbf n n 的夹脚,这里可以看成常量。仍然使用上面的直接方法表示权重 w ( t ) w(t) w(t),有
w ( t ) = ϕ s ( f ( p ( t ) ) ) ∫ − ∞ + ∞ ϕ s ( f ( p ( u ) ) ) d u = ϕ s ( f ( p ( t ) ) ) ∫ − ∞ + ∞ ϕ s ( − ∣ cos ( θ ) ∣ ⋅ ( u − t ) ) d u = ϕ s ( f ( p ( t ) ) ) ∣ cos ( θ ) ∣ − 1 ⋅ ∫ − ∞ + ∞ ϕ s ( u − t ) d u = ∣ cos ( θ ) ∣ ϕ s ( f ( p ( t ) ) ) \begin{aligned} w(t) &=\frac{\phi_{s}(f(\mathbf{p}(t)))}{\int_{-\infty}^{+\infty} \phi_{s}(f(\mathbf{p}(u))) \mathrm{d} u} \\ &=\frac{\phi_{s}(f(\mathbf{p}(t)))}{\int_{-\infty}^{+\infty} \phi_{s}\left(-|\cos (\theta)| \cdot\left(u-t^{}\right)\right) \mathrm{d} u} \\ &=\frac{\phi_{s}(f(\mathbf{p}(t)))}{|\cos (\theta)|^{-1} \cdot \int_{-\infty}^{+\infty} \phi_{s}\left(u-t^{}\right) \mathrm{d} u} \\ &=|\cos (\theta)| \phi_{s}(f(\mathbf{p}(t))) \end{aligned} w(t)=∫−∞+∞ϕs(f(p(u)))duϕs(f(p(t)))=∫−∞+∞ϕs(−∣cos(θ)∣⋅(u−t))duϕs(f(p(t)))=∣cos(θ)∣−1⋅∫−∞+∞ϕs(u−t)duϕs(f(p(t)))=∣cos(θ)∣ϕs(f(p(t)))
为了求出 ρ ( t ) \rho(t) ρ(t),有 T ( t ) ρ ( t ) = ∣ cos ( θ ) ∣ ϕ s ( f ( p ( t ) ) ) = − d Φ s d t ( f ( p ( t ) ) ) = d T d t ( t ) T(t) \rho(t) = |\cos (\theta)| \phi_{s}(f(\mathbf{p}(t))) = -\frac{\mathrm{d} \Phi_{s}}{\mathrm{~d} t}(f(\mathbf{p}(t))) = \frac {\mathrm{d}T}{\mathrm{d}t}(t) T(t)ρ(t)=∣cos(θ)∣ϕs(f(p(t)))=− dtdΦs(f(p(t)))=dtdT(t)
所以, T ( t ) = Φ s ( f ( p ( t ) ) ) T(t)=\Phi_{s}(f(\mathbf{p}(t))) T(t)=Φs(f(p(t))),求得
ρ ( t ) = − d Φ s d t ( f ( p ( t ) ) ) Φ s ( f ( p ( t ) ) ) \rho(t)=\frac{-\frac{\mathrm{d} \Phi_{s}}{\mathrm{~d} t}(f(\mathbf{p}(t)))}{\Phi_{s}(f(\mathbf{p}(t)))} ρ(t)=Φs(f(p(t)))− dtdΦs(f(p(t)))
上式是单个surface的情况,当光线在两个surface之间时会变成负,把它拓展到多surface的情况需要在这时将之设为0。
ρ ( t ) = max ( − d Φ s d t ( f ( p ( t ) ) ) Φ s ( f ( p ( t ) ) ) , 0 ) \rho(t)=\max \left(\frac{-\frac{\mathrm{d} \Phi_{s}}{\mathrm{~d} t}(f(\mathbf{p}(t)))}{\Phi_{s}(f(\mathbf{p}(t)))}, 0\right) ρ(t)=max(Φs(f(p(t)))− dtdΦs(f(p(t))),0)
最后再使用 w ( t ) = T ( t ) ρ ( t ) w(t)=T(t) \rho(t) w(t)=T(t)ρ(t) 计算出权重方程。

Discretization
类似 NeRF,定义采样点 n n n 个: { p i = o + t i v ∣ i = 1 , … , n , t i < t i + 1 } \left\{\mathbf{p}{i}=\mathbf{o}+t{i} \mathbf{v} \mid i=1, \ldots, n, t_{i}
C ^ = ∑ i = 1 n T i α i c i \hat{C}=\sum_{i=1}^{n} T_{i} \alpha_{i} c_{i} C^=i=1∑nTiαici
- T i = ∏ j = 1 i − 1 ( 1 − α j ) T_{i}=\prod_{j=1}^{i-1}\left(1-\alpha_{j}\right) Ti=∏j=1i−1(1−αj) 是离散的累积透射比accumulated transmittance。
- α i = 1 − exp ( − ∫ t i t i + 1 ρ ( t ) d t ) \alpha_{i}=1-\exp \left(-\int_{t_{i}}^{t_{i+1}} \rho(t) \mathrm{d} t\right) αi=1−exp(−∫titi+1ρ(t)dt) 是离散的浑浊度 opacity value。
α i \alpha_i αi 对应前面提到的 ρ \rho ρ,可以进一步表示为:
α i = max ( Φ s ( f ( p ( t i ) ) − Φ s ( f ( p ( t i + 1 ) ) ) Φ s ( f ( p ( t i ) ) ) , 0 ) \alpha_{i}=\max \left(\frac{\Phi_{s}\left(f\left(\mathbf{p}\left(t_{i}\right)\right)-\Phi_{s}\left(f\left(\mathbf{p}\left(t_{i+1}\right)\right)\right)\right.}{\Phi_{s}\left(f\left(\mathbf{p}\left(t_{i}\right)\right)\right)}, 0\right) αi=max(Φs(f(p(ti)))Φs(f(p(ti))−Φs(f(p(ti+1))),0)
Training
分为有mask和无mask两种情况。为了优化网络和标准差倒数 s s s,随机采样一个batch的像素点和对应的光线 P = { C k , M k , O k , v k } P=\left\{C_{k}, M_{k}, \mathbf{O}{k}, \mathbf{v}{k}\right\} P={Ck,Mk,Ok,vk}, C k C_k Ck 是像素点颜色, M k ∈ { 0 , 1 } M_k \in \{0,1\} Mk∈{0,1} 指是否存在mask。batch大小设为 m m m,一条光线上的采样点数设为 n n n。
定义损失函数:
L = L color + λ L reg + β L mask \mathcal{L}=\mathcal{L}_{\text {color }}+\lambda \mathcal{L}_{\text {reg }}+\beta \mathcal{L}_{\text {mask }} L=Lcolor +λLreg +βLmask
其中, L color = 1 m ∑ k R ( C ^ k , C k ) \mathcal{L}_{\text {color }}=\frac{1}{m} \sum_{k} \mathcal{R}\left(\hat{C}_{k}, C_{k}\right) Lcolor =m1∑kR(C^k,Ck),类似IDR, R \mathcal{R} R 采用 L1 loss;Eikonal 项 L r e g = 1 n m ∑ k , i ( ∣ ∇ f ( p ^ k , i ) ∣ − 1 ) 2 \mathcal{L}_{r e g}=\frac{1}{n m} \sum_{k, i}\left(\left|\nabla f\left(\hat{\mathbf{p}}_{k, i}\right)\right|-1\right)^{2} Lreg=nm1∑k,i(∣∇f(p^k,i)∣−1)2;可选项 L mask = B C E ( M k , O ^ k ) \mathcal{L}_{\text {mask }}=\mathrm{BCE}\left(M_{k}, \hat{O}_{k}\right) Lmask =BCE(Mk,O^k), O ^ k = ∑ i = 1 n T k , i α k , i \hat{O}_{k}=\sum_{i=1}^{n} T_{k, i} \alpha_{k, i} O^k=∑i=1nTk,iαk,i是采样点权重的和,BCE是 Binary Entropy Loss。
分层采样 Hierarchical Sampling
不像NeRF同时优化 coarse 和 fine 网络,这里只维持一个网络,coarse阶段采样的概率是基于 S-density ϕ s ( f ( x ) ) \phi_s(f(\mathbf x)) ϕs(f(x)) 和一个大的固定的标准差计算得到,而fine阶段采样的概率基于 ϕ s ( f ( x ) ) \phi_s(f(\mathbf x)) ϕs(f(x)) 和学得的标准差。
实现细节

实验
Surface reconstruction with mask
Surface reconstruction w/o mask
Ablation study
