最新 Visual Transformer 论文速览 (Attention Free Transformer,CeiT,DynamicViT)
Convolution-enhanced image Transformer (CeiT)
目录
An Attention Free Transformer [28 May 2021]
Abstract
Incorporating Convolution Designs into Visual Transformers [20 Apr 2021]
Abstract
Method
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification [3 Jun 2021]
Abstract
Method
When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations [3 Jun 2021]
Abstract
An Attention Free Transformer [28 May 2021]

https://arxiv.org/pdf/2105.14103.pdf
Abstract
We introduce Attention Free Transformer (AFT), an efficient variant of Transformers that eliminates the need for dot product self attention.
In an AFT layer, the key and value are first combined with a set of learned position biases, the result of which is multiplied with the query in an element-wise fashion.
This new operation has a memory complexity linear w.r.t. both the context size and the dimension of features, making it compatible to both large input and model sizes.
We also introduce AFT-local and AFT-conv, two model variants that take advantage of the idea of locality and spatial weight sharing while maintaining global connectivity.
We conduct extensive experiments on two autoregressive modeling tasks (CIFAR10 and Enwik8) as well as an image recognition task (ImageNet-1K classification). We show that AFT demonstrates competitive performance on all the benchmarks, while providing excellent efficiency at the same time.
本文核心:介绍了无注意力的 Transformer (AFT),消除了点积自注意的需要。
具体方法:首先将 key 和 value 与一组学习到的位置偏差结合起来,其结果以元素相乘地方式与 query 相乘。本文还引入了 AFT-local 和 AFT-conv,这两个模型变种,在保持全局连通性的同时,利用了局域性和空间权重共享的思想。
方法优点:该方法在上下文大小和特征维度上都具有线性的内存复杂度,使得它能够兼容大的输入和模型大小。实验展示了 AFT 在所有 banchimarks 上的竞争性能,同时提供了出色的效率。
第一段,Transformers介绍:以 Transformers 为代表的自注意机制推动了各种机器学习问题的发展,包括语言理解和计算机视觉应用。与卷积神经网络 (CNNs) 或循环神经网络 (RNNs) 等经典模型架构不同,Transformers 能够在序列中的每一对元素之间进行直接交互,这使得它们在捕获长期依赖关系方面特别强大。
第二段,研究问题及现状:然而,Transformers 需要很高的计算成本。造成这一挑战的原因是需要执行注意力操作,其时间和空间复杂度为上下文大小的二次值。这使得 Transformers 很难扩展到具有大上下文规模的输入。许多最近的工作都致力于解决 Transformers 的可伸缩性问题 [7-13]。这里的普遍想法是使用稀疏性、局部敏感哈希、低秩分解、核近似等技术来近似全注意操作。
第三段,本文解决思路:本文提出一个计算模块,不使用或不使用近似标准点积的注意力。因此,本文的模型命名为 attention free transformer (AFT)。与点积注意力类似,AFT 由三个量的交互组成,即 query、key 和 value (Q、K、V)。不同之处在于,在 AFT 中 key 和 value (上下文) 首先用一组学习到的位置偏差被组合在一起;然后将 query 与具有元素级乘法的简化上下文相结合。定义如下公式和如图2所示:

Figure 2: An illustration of AFT defined in Equation 2, with T = 3, d = 2.
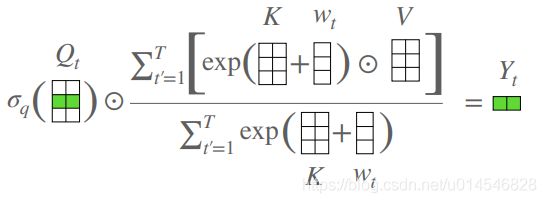
第四、五段,AFT 深度解释:AFT 保持了语境中任意两点之间的直接互动,这是点积注意力的主要优势。事实上,AFT 可以被解释为在注意 head 的数量与模型的特征维度相同的情况下进行注意,而注意图不需要明确计算 (详见3.1节)。这导致了内存复杂度,输入和模型大小都是线性的。
最近的线性化注意力工作 [11,13 15] 中也发现了 Q, K, V 的重新排列的计算顺序。不同之处在于,AFT 将 k 和 v 以一种元素的方式组合在一起,而所有的线性注意力论文都依赖于矩阵点积。后一种方法导致模型特征维的复杂度为二次型,这不利于模型的大尺寸。AFT 相对于其他变体的复杂性分析见表1。

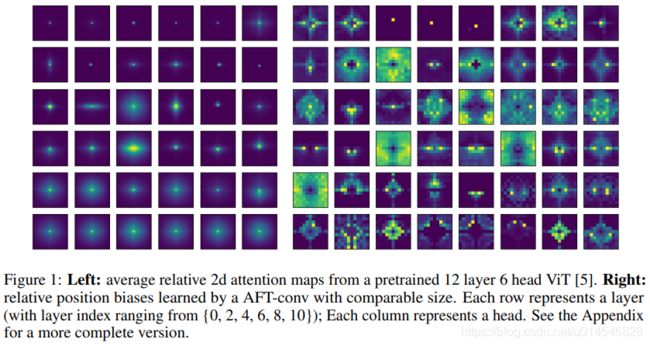
第六段,本文的另一发现和贡献:根据观察,经过训练的 Transformers 倾向于展示广泛的局部模式 (见图1)。这促使本文提出 AFT 的两种变体:AFT-local 和 AFT-conv。在 AFT-local 中,学习到的位置偏差被限制在一个局部区域,同时保持全局连通性。AFT-conv 通过强制空间权重共享进一步扩展了这一设计,有效地使其成为具有全局接受域的 CNN 的变体。结果表明,局部约束不仅提供了更好的参数和计算效率,而且大大提高了模型在所有任务中的性能。
最后一段,实验结果:在图像自回归建模、字符级语言建模和图像分类任务上进行了实验。实验证明 AFT 提供了具有竞争力的性能,经常匹配或击败标准 Transformers 和其他变体,同时提供卓越的效率。本文还对AFT 的几种设计选择进行了广泛的消融研究,并讨论了其独特的特性,如与 Transformers 的兼容性、稀疏性和可变尺寸输入。
Incorporating Convolution Designs into Visual Transformers [20 Apr 2021]
![]()
Abstract
Motivated by the success of Transformers in natural language processing (NLP) tasks, there emerge some attempts (e.g., ViT and DeiT) to apply Transformers to the vision domain. However, pure Transformer architectures often require a large amount of training data or extra supervision to obtain comparable performance with convolutional neural networks (CNNs).
To overcome these limitations, we analyze the potential drawbacks when directly borrowing Transformer architectures from NLP. Then we propose a new Convolution-enhanced image Transformer (CeiT) which combines the advantages of CNNs in extracting lowlevel features, strengthening locality, and the advantages of Transformers in establishing long-range dependencies.
Three modifications are made to the original Transformer: 1) instead of the straightforward tokenization from raw input images, we design an Image-to-Tokens (I2T) module that extracts patches from generated low-level features; 2) the feed-froward network in each encoder block is replaced with a Locally-enhanced Feed-Forward (LeFF) layer that promotes the correlation among neighboring tokens in the spatial dimension; 3) a Layer-wise Class token Attention (LCA) is attached at the top of the Transformer that utilizes the multi-level representations.
Experimental results on ImageNet and seven downstream tasks show the effectiveness and generalization ability of CeiT compared with previous Transformers and stateof-the-art CNNs, without requiring a large amount of training data and extra CNN teachers. Besides, CeiT models also demonstrate better convergence with 3× fewer training iterations, which can reduce the training cost significantly.
第一段,背景问题:然而,纯 Transformer 架构通常需要大量的训练数据或额外的监督才能获得与卷积神经网络 (CNNs) 相当的性能。
第二段,核心贡献:提出了一种新的卷积增强图像变换 (CeiT),结合了卷积神经网络在提取低级特征、增强局域性和 Transformers 网络在建立长期依赖方面的优势。
第三段,具体内容:Image-to-Tokens module - 提取 low-level 特征;Locally-enhanced Feed-Forward (LeFF) layer - 在空间维度上促进相邻 token 之间的相关性;Layer-wise Class token Attention (LCA) - 利用多级表示。
Method
- Image-to-Tokens (I2T) module:
定义:![]()
Figure 2. Comparisons of different tokenization methods. The upper one extracts patches from raw input images. The below one (I2T) uses the low-level features generated by a convolutional stem.
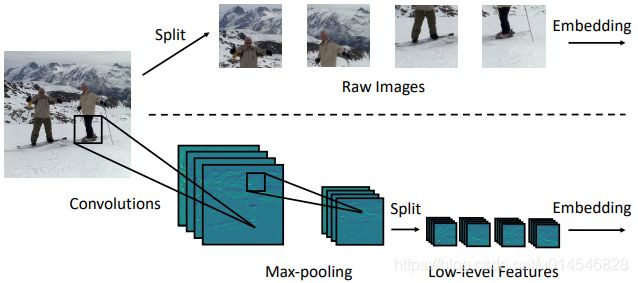
Motivation:传统的 ViT 以 16 × 16 或 32 × 32 的 patch 大小分割每张图像。但是对于大块的输入图像,直接的标记化 tokenization 可能有两个局限性:1) 难以捕获图像中的低级信息 (如边缘和角落); 2) 大的 kernel 被过度参数化,通常难以优化,因此需要更多的训练样本或训练迭代。
I2T 作用:I2T 充分利用了神经网络在提取低级特征方面的优势,通过缩小 patch 的大小降低了嵌入的训练难度。这也不同于 ViT 中提出的混合类型的 Transformer,后者使用常规的 ResNet-50 来提取高级特征从最后两个阶段开始。相比之下, I2T 轻得多。
- Locally-Enhanced Feed-Forward (LeFF) Network
定义:
Figure 3. Illustration of the Locally-enhanced Feed-Forward module. First, patch tokens are projected into a higher dimension. Second, they are restored to “images” in the spatial dimension based on the original positions. Third, a depth-wise convolution is performed on the restored tokens as shown in the yellow region. Then the patch tokens are flattened and projected to the initial dimension. Besides, the class token conducts an identical mapping.
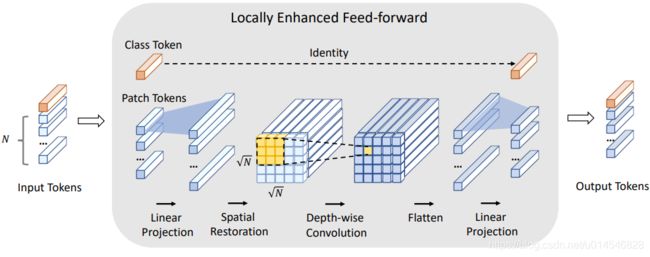
LeEF 作用:结合了 CNN 提取局部信息的优势和 Transformer 建立长期依赖关系的能力。
- Layer-wise Class-Token Attention
Figure 4. The proposed Layer-wise Class-token Attention block. It integrates information across different layers through receiving a sequence of class tokens as inputs.
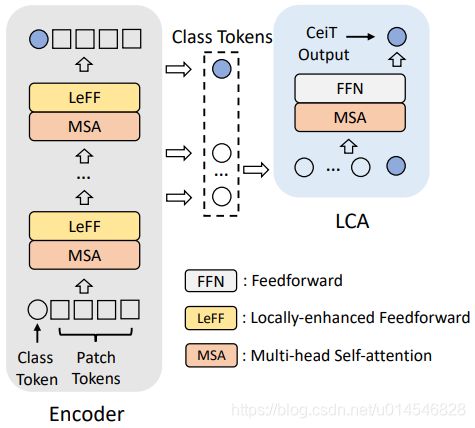
Motivation: 在 CNN 中,随着网络的加深,feature map 的接受域也会增加。在 ViT 中,“注意距离”(attention distance) 随着深度的增加而增加。因此,不同层的特征表示将是不同的。
LCA 作用:集成不同层次的信息。
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification [3 Jun 2021]

https://arxiv.org/pdf/2106.02034.pdf
https://github.com/raoyongming/DynamicViT
Abstract
Attention is sparse in vision transformers. We observe the final prediction in vision transformers is only based on a subset of most informative tokens, which is sufficient for accurate image recognition.
Based on this observation, we propose a dynamic token sparsification framework to prune redundant tokens progressively and dynamically based on the input.
Specifically, we devise a lightweight prediction module to estimate the importance score of each token given the current features. The module is added to different layers to prune redundant tokens hierarchically. To optimize the prediction module in an end-to-end manner, we propose an attention masking strategy to differentiably prune a token by blocking its interactions with other tokens. Benefiting from the nature of self-attention, the unstructured sparse tokens are still hardware friendly, which makes our framework easy to achieve actual speed-up.
By hierarchically pruning 66% of the input tokens, our method greatly reduces 31% ∼ 37% FLOPs and improves the throughput by over 40% while the drop of accuracy is within 0.5% for various vision transformers. Equipped with the dynamic token sparsification framework, DynamicViT models can achieve very competitive complexity/accuracy trade-offs compared to state-of-the-art CNNs and vision transformers on ImageNet.
1. Motivation:在 vision transformers 中,注意力是稀疏的。作者观察到 vision transformers 的最终预测仅基于最具信息量的标记 (tokens)的子集,这对于准确的图像识别是足够的。
2. 本文核心:在此基础上,本文提出了一种动态标记稀疏化框架,该框架可以根据输入信息,逐步动态地裁减冗余 tokens。
3. 具体介绍:本文设计了一个轻量级预测模块来估计给定当前特性的每个 tokens 的重要性分数。该模块被添加到不同的层,以分层地删除冗余的 tokens。为了以端到端方式优化预测模块,提出了一种注意屏蔽策略,通过阻止令牌与其他 tokens 的交互,可区分地剪枝 tokens。得益于自注意力的本质,非结构化稀疏 tokens 仍然是硬件友好的,这使得本文的框架很容易实现实际的加速。
4. 实验效果:通过对66%的输入 tokens 进行分层修剪,本文的方法大大减少了 31% ∼ 37% 的FLOPs,提高了 40% 以上的吞吐量,而对各种视觉变形器的精度下降在 0.5% 以内。与先进的 CNN 和 ImageNet 上的 vision transformers 相比,DynamicViT 模型配备了动态 tokens 稀疏化框架,可以实现非常有竞争力的复杂性/准确性权衡。
Method
DynamicViT 的总体框架如图 2 所示。动态 ViT 由一个普通的 vision transformer 作为 backbone 和几个预测模块组成。backbone 可以实现为广泛的 vision transformer (例如,ViT [7], DeiT [23], LV-ViT[15])。预测模块负责生成丢弃/保存标记的概率。token 稀疏化是在整个网络的特定位置分层执行的。例如,给定一个 12 层的transformer ,可以在第 4、7、9 块之前进行 token 稀疏化。在训练过程中,由于本文新设计的注意掩蔽策略,预测模块和骨干网可以端到端进行优化。在推理过程中,只需要根据预定义的修剪比率和预测模块计算的分数选择信息量最大的 token。
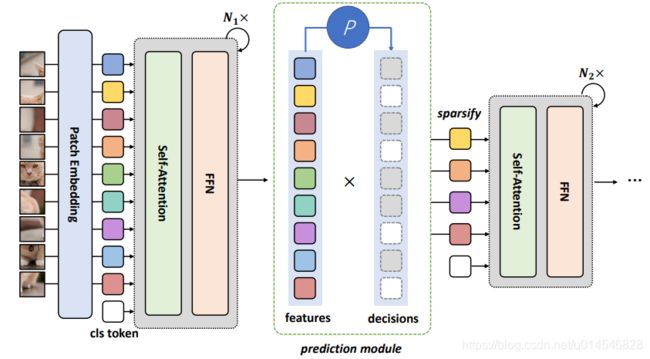
Figure 2: The overall framework of the proposed approach. The proposed prediction module is inserted between the transformer blocks to selectively prune less informative token conditioned on features produced by the previous layer. By doing so, less tokens are processed in the followed layers.
- Hierarchical Token Sparsification with Prediction Modules
DynamicViT 的一个重要特征是,token 稀疏是分层执行的,也就是说,随着计算的进行,DynamicViT 逐渐删除无信息的 token。
为了实现这一点,保持一个二进制决策掩码 ![]() 表示是丢弃还是保留每个 token,其中 N = HW 是 patch embeddings 的数量。将决策掩码中的所有元素初始化为 1,并逐步更新掩码。预测模块将当前决策 D 和 tokens
表示是丢弃还是保留每个 token,其中 N = HW 是 patch embeddings 的数量。将决策掩码中的所有元素初始化为 1,并逐步更新掩码。预测模块将当前决策 D 和 tokens ![]() 作为输入。首先使用 MLP 对 tokens 进行投影
作为输入。首先使用 MLP 对 tokens 进行投影
![]()
其中 C' 是更小的维度,C'= C/2。类似地,可以通过以下方法计算一个全局特征:
![]()
其中 Agg 是聚合所有现有 tokens 信息的函数,可以简单地用一个平均池化实现。
局部特征对特定 tokens 的信息进行编码,而全局特征包含整个图像的上下文,因此两者都是有用的。因此,结合局部和全局特征来获得局部-全局嵌入,并将它们提供给另一个 MLP 来预测丢弃/保留 tokens 的概率:

其中 ![]() 表示去掉第 i 个 tokens 的概率,
表示去掉第 i 个 tokens 的概率,![]() 表示保留第 i 个 tokens 的概率。
表示保留第 i 个 tokens 的概率。
然后,可以通过从 π 采样生成当前决策 D,并通过
![]()
 是 Hadamard 乘法(元素相乘),表明一旦一个 tokens 被丢弃,它将永远不会被使用。
是 Hadamard 乘法(元素相乘),表明一旦一个 tokens 被丢弃,它将永远不会被使用。
- End-to-end Optimization with Attention Masking
虽然目标是执行 tokens 稀疏化,但发现在训练过程中实现它并不简单。首先,从 π 采样得到二值决策掩码 D 是不可微的,这阻碍了端到端的训练。为了克服这个问题,使用 Gumbel-Softmax 技术 [14] 从概率 π 中采样:
![]()
这里使用索引 “1”,因为 D 表示保留的 tokens 的掩码。Gumbel-Softmax 的输出是一个单热张量,其期望正好等于 π。同时,Gumbel-Softmax 具有可微性,使得端到端训练成为可能。
【14】Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. In ICLR, 2017
第二个障碍是当试图在训练期间修剪 tokens 时,决策掩码  通常是非结构化的,不同样本的掩码包含不同的 1’s 数。因此,简单地丢弃
通常是非结构化的,不同样本的掩码包含不同的 1’s 数。因此,简单地丢弃 ![]() 的 tokens 会导致一批样本的 tokens 数量不一致,这使得并行化计算变得困难。因此,必须保持 tokens 的数量不变,同时减少修剪后的 tokens 与其他 tokens 之间的交互。同时还发现,仅仅用二进制掩码 D 去除要丢弃的 tokens 是不可行的,因为在自注意矩阵的计算中
的 tokens 会导致一批样本的 tokens 数量不一致,这使得并行化计算变得困难。因此,必须保持 tokens 的数量不变,同时减少修剪后的 tokens 与其他 tokens 之间的交互。同时还发现,仅仅用二进制掩码 D 去除要丢弃的 tokens 是不可行的,因为在自注意矩阵的计算中
![]()
零 tokens 仍然会通过 Softmax 操作影响其他 tokens。为此,本文设计了一种注意力掩蔽的策略,可以完全消除掉 tokens 的影响。具体来说,通过以下方法来计算注意矩阵:

通过公式(![]() ),构造一个图,其中 Gij = 1 表示第 j 个 tokens 将有助于第 i 个 tokens 的更新。请注意,显式地为每个 token 添加了一个自循环,以提高数值稳定性。也很容易表明自循环不会影响结果:如果D j = 0,第 j 个 tokens 将不会对除它自己以外的任何 tokens 作出贡献。式 (
),构造一个图,其中 Gij = 1 表示第 j 个 tokens 将有助于第 i 个 tokens 的更新。请注意,显式地为每个 token 添加了一个自循环,以提高数值稳定性。也很容易表明自循环不会影响结果:如果D j = 0,第 j 个 tokens 将不会对除它自己以外的任何 tokens 作出贡献。式 (![]() ) 计算掩膜注意矩阵 A,等效于只考虑保留 tokens 而在训练过程中具有恒定状 NxN 的注意矩阵。
) 计算掩膜注意矩阵 A,等效于只考虑保留 tokens 而在训练过程中具有恒定状 NxN 的注意矩阵。

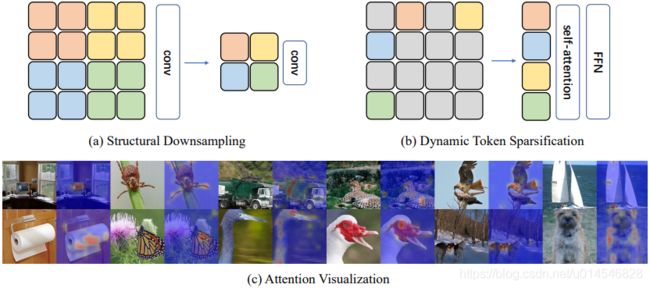
Figure 5: Visualization of the progressively sparsified tokens. We show the original input image and the sparsification results after the three stages, where the masks represent the corresponding tokens are discarded. We see our method can gradually focus on the most representative regions in the image. This phenomenon suggests that the DynamicViT has better interpretability.
When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations [3 Jun 2021]
https://arxiv.org/pdf/2106.01548.pdf

Abstract
Vision Transformers (ViTs) and MLPs signal further efforts on replacing handwired features or inductive biases with general-purpose neural architectures. Existing works empower the models by massive data, such as large-scale pretraining and/or repeated strong data augmentations, and still report optimization-related problems (e.g., sensitivity to initialization and learning rate).
Hence, this paper investigates ViTs and MLP-Mixers from the lens of loss geometry, intending to improve the models’ data efficiency at training and generalization at inference. Visualization and Hessian reveal extremely sharp local minima of converged models.
By promoting smoothness with a recently proposed sharpness-aware optimizer, we substantially improve the accuracy and robustness of ViTs and MLP-Mixers on various tasks spanning supervised, adversarial, contrastive, and transfer learning (e.g., +5.3% and +11.0% top-1 accuracy on ImageNet for ViT-B/16 and MixerB/16, respectively, with the simple Inception-style preprocessing).
We show that the improved smoothness attributes to sparser active neurons in the first few layers. The resultant ViTs outperform ResNets of similar size and throughput when trained from scratch on ImageNet without large-scale pretraining or strong data augmentations. They also possess more perceptive attention maps.
1. 研究背景:
目前的 ViTs、mlp-mixer 和相关的无卷积架构的训练方法很大程度上依赖于大量的预训练或强数据增强。它对数据和计算有很高的要求,并导致许多超参数需要调整。
现有的研究表明,当在 ImageNet 上从头开始训练时,如果不结合那些先进的数据增强,尽管使用了各种正则化技术(例如,权重衰减,Dropout 等) ViTs 的精度依然低于类似大小和吞吐量的卷积网络。同时在鲁棒性测试方面,vit 和 resnet 之间也存在较大的差距。
此外,Chen 等人发现,在训练vit时,梯度会出现峰值,导致精确度突然下降,Touvron 等人也发现初始化和超参数对训练很敏感。这些问题其实都可以归咎于优化问题。
在本文中,作者研究了 ViTs 和 mlp-mixer 的损失情况,从优化的角度理解它们,旨在减少它们对大规模预训练或强数据增强的依赖。
2. 本文工作:因此,本文从损耗几何的角度对 ViTs 和 MLP-Mixers 进行了研究,旨在提高模型的训练效率和推理泛化效率。可视化和 Hessian 显示了极为尖锐的局部最小收敛模型。
3. 本文贡献:通过使用最近提出的锐度感知优化器提高平滑性,本文大幅提高了 ViTs 和 MLP-Mixers 在监督、对抗、对比和迁移学习等各种任务上的准确性和鲁棒性(例如,使用简单的Inception 进行预处理,ImageNet 上的 vitb /16 和 MixerB/16 分别为 +5.3% 和 +11.0% 的 top-1 准确率)。
4. 本文结论:本文证明了改进的平滑属性归因于前几层的稀疏活动神经元。当在 ImageNet 上从头开始训练时,在没有进行大规模的预训练或强大的数据增强的情况下,得到的 vit 的性能优于相同大小和吞吐量的 resnet。同时还拥有更敏锐的注意力图。