对NLP Prompt范式的浅显理解
从预训练-微调(Pre-train Fine-tune)范式说起
预训练-微调范式就是预训练好一个初始模型,后续根据具体的下游任务来对初始模型进行微调。
预训练-微调范式存在的问题是:
①预训练模型有可能会过拟合;
②如果微调数据不足,微调的效果就不好;
③微调后的模型有可能连用来预训练任务都无法执行。
预训练-微调范式预训练出来的模型需要去迎合下游任务,i.e. 要根据具体的下游任务微调模型参数,如②所说,如果微调数据不足,那微调就达不到理想的效果。
Prompt范式就登场了,与预训练-微调范式相反,在Prompt范式中,是要让下游任务去迎合预训练模型。
那么什么是Prompt范式?Prompt范式是如何做到让下游任务迎合预训练模型的?
一、什么是Prompt范式?
prompt英文原意为 提示
prompt直观理解:
在NLP领域中:

给输入的文本加上一些额外的文字,从而更好地让预训练模型发挥作用。
那么这些额外的文字是怎么加的?作用又是什么呢?
通过Prompt的工作流程来理解,走完一遍这个工作流程基本上就能理解Prompt了。
以一个情感分析任务为例
这个任务的输入是一个句子x,输出对这个句子的判断是positive标签还是negative标签
取x = I love this movie.
第一步,Prompt Construction(prompt构建)
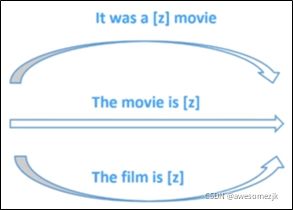
定义一个有两个槽(输入槽[x]和输出槽[z])的模板,模板是一段文字。
提醒一下,Prompt中模板的定义又是另外一个不小的工作了,这里我们假定已经定义好了一个模板

这个模板是:[x]Overall, it was a [z] movie.
将x代入到模板中得到x'
x' = I love this movie. Overall, it was a [z] movie.
第二步,Answer Construction(答案构建)
构建答案和类别标签的对应关系
这里也要提醒一下,Prompt中答案-标签对应关系的构建也是另外一个不小的工作,所以这里我们也假定已经定义好了一组答案-标签对应关系

positive - great
negative – boring
到这里先暂停说一下,为了区分,将第一步和第二步的模板和答案称为prompt,区别于大写的Prompt,大写的Prompt指Prompt范式
第三步,Answer Prediction(答案预测)
根据具体的下游任务人工来选择一个预训练好的语言模型,e.g. BERT
使用这个语言模型来预测答案[z],假设预测得到的答案[z]是great,那么
x' = I love this movie. Overall, it was a great movie.
第四步,Anser-Label Mapping(答案-标签映射)
将答案great映射到标签positive
然后输出positive.
结束
二、Prompt范式是如何做到让下游任务迎合预训练模型的?
我认为就是靠prompt来做到的,也就是模板和答案
所以Prompt范式的关键就是模板和答案的设计,而这两个都不是什么简单的工作,各自都分别是另外一项工作

模板的设计叫做Template Engineering,如何根据特定的下游任务来设计这个模板
答案的设计叫做Answer Engineering,如何根据特定的下游任务来设计答案和标签的对应

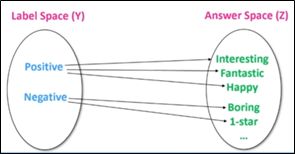
下图展示了一些例子,不同的下游任务可能的模板和可能的答案

求各位大佬轻喷,我只是个还未入门的初学者,这篇文章的定位也只是作为我的个人学习笔记
References
[1] 大模型Prompt Tuning技术分享_哔哩哔哩_bilibili
[2] Making Pre-trained Language Models Better Few-shot Learners.https://arxiv.org/pdf/2012.15723.pdf
[3] Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing.https://arxiv.org/pdf/2107.13586.pdf
[4] Formal Description of Prompting: Systematic Survey of Prompting Methods in NLP (P.1).https://www.youtube.com/watch?v=K3MasIU25Zw