PyTorch分布式DPP启动方式(包含完整用例)
PyTorch分布式DPP启动方式
-
- 1 基本使用
-
- 1.1 单卡版本
- 1.2 多卡分布式
- 2 分布式用例
-
- 2.1 单机多卡
- 2.2 多机分布式
-
- 2.2.1 方式一:每个进程占用一张卡
- 2.2.2 方式二:单个进程占用多张卡
- 2.2.3 方式三:利用launch
本篇主要讲解单卡到分布式中DDP(DistributeDataParallel )的使用基础,包括如何使用DDP和相关的一些基础问题。
主要涵盖如下问题:
1、单卡到分布式的过程中,用户代码需要怎么调整?
单卡变成分布式中处理过程差异,以及用户要干什么。
2、DDP的启动方式有几种? 差异在哪?
DDP的启动方式与代码修改如何对应,单进程单卡、单进程多卡、单卡多进程的模式如何启动。
选择分布式前用户首先需要明白自己的场景,是需要数据并行与还是需要考虑模型并行。因为DDP指的是数据并行的分布式,一般适用于单张GPU能够加载一个完全的模型,这一点在PyTorch的-DDP官网文档有说明。明确这点后,再继续往下看:
1 基本使用
直接放一个简单的列子来看一下,单卡到多卡用户的代码如何修改。这里采用一个简单的MNIST分类例子来分析,从单卡代码到分布式变动了哪些地方。
1.1 单卡版本
import torch
import torchvision
import torch.utils.data.distributed
from torchvision import transforms
def main():
# 数据加载部分,直接利用torchvision中的datasets
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.MNIST("./", train=True, transform=trans, target_transform=None, download=True)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=256)
# 网络搭建,调用torchvision中的resnet
net = torchvision.models.resnet101(num_classes=10)
net.conv1 = torch.nn.Conv1d(1, 64, (7, 7), (2, 2), (3, 3), bias=False)
net = net.cuda()
# 定义loss与opt
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=0.001)
# 网络训练
for epoch in range(10):
for i, data in enumerate(data_loader_train):
images, labels = data
images = torch.tensor(images).cuda()
labels = torch.tensor(labels).cuda()
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
if i % 10 == 0:
print("loss: {}".format(loss.item()))
# 保存checkpoint
torch.save(net, "my_net.pth")
if __name__ == "__main__":
main()
1.2 多卡分布式
import torch
import torchvision
import torch.utils.data.distributed
from torchvision import transforms
def main():
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.MNIST("./", train=True, transform=trans, target_transform=None, download=True)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=256)
net = torchvision.models.resnet101(num_classes=10)
net.conv1 = torch.nn.Conv1d(1, 64, (7, 7), (2, 2), (3, 3), bias=False)
net = net.cuda()
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=0.001)
for epoch in range(10):
for i, data in enumerate(data_loader_train):
images, labels = data
images = torch.tensor(images).cuda()
labels = torch.tensor(labels).cuda()
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
if i % 10 == 0:
print("loss: {}".format(loss.item()))
torch.save(net, "my_net.pth")
用Comparer对比,如下图所示:
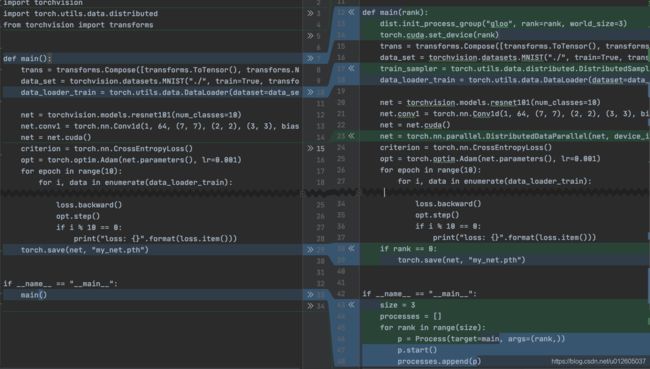
可以看出,主要变动的位置包括:
- 启动的方式引入了一个多进程机制;
- 引入了几个环境变量;
- DataLoader多了一个sampler参数;
- 网络被一个DistributedDataParallel(net)又包裹了一层;
- ckpt的保存方式发生了变化。
这些修改都是为了适配数据流动过程的变化,来对比一下单卡与分布式的过程中的数据流的变化:

从图片的对比可知,分布式使得数据的切分(batch_data)以及前向计算后的数据传递发生了变化(all_reduce),对应到ddp里面:
1、由于分布式采用的是多进程模式,要保证不同进程拿到的是不同的数据,需要在正向传播时对数据的分配进行调整,所以dataloader里面多了一个sampler参数。
2、反向传播计算后需要对参数进行共享通信,所以多了一个allreduce的处理。
还有一些需要处理的地方,比如大部分情况下,分布式的进程之间执行的都是相同的代码,但是有些只需处理一次的工作,比如ckpt的保存,就需要指定单个进程来完成。 于是需要对进程进行编号,指定特定编号的进程去完成特定的工作,这个编号是rank。
单机多卡、多机模式如何启动? 继续看:
2 分布式用例
DDP的启动方式形式上有多种,内容上是统一的:都是启动多进程来完成运算。
先来看一般单机多卡的形式:
2.1 单机多卡
单机多卡,可以直接用Process启动,也可以用torch.multiprocessing.spawn,还可以用launch启动(多机启动中会介绍)。这里主要介绍前两种,在前面提到MNIST用例中用的是Process格式,摘取启动的位置:
# Process格式:
if __name__ == "__main__":
world_size= 3
processes = []
# 创建进程组
for rank in range(world_size):
p = Process(target=main, args=(rank, world_size))
p.start()
processes.append(p)
for p in processes:
p.join()
spawn本质上就是简化了Process的抒写,其spawn格式如下:
# spawn格式:
def main():
world_size= 3
mp.spawn(main,
args=(world_size,),
nprocs=world_size,
join=True)
来一份采用spawn的完整用例
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
def example(rank, world_size):
# 初始化
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# 创建模型
model = nn.Linear(10, 10).to(rank)
# 放入DDP
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# 进行前向后向计算
for i in range(1000):
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
main()
2.2 多机分布式
多机的启动方式可以是直接传递参数并在代码内部解析环境变量,或者通过torch.distributed.launch来启动,两者在格式上面有一定的区别,总之要保证代码与启动方式对应。
2.2.1 方式一:每个进程占用一张卡
首先,看一下如何实现多机的一个进程占用一张卡的使用,需要注意的位置:
- dist.init_process_group里面的rank需要根据node以及GPU的数量计算;
- world_size的大小=节点数 x GPU 数量。
- ddp 里面的device_ids需要指定对应显卡。
示例代码: demo.py
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--world_size", type=int)
parser.add_argument("--node_rank", type=int)
parser.add_argument("--master_addr", default="127.0.0.1", type=str)
parser.add_argument("--master_port", default="12355", type=str)
args = parser.parse_args()
def example(local_rank, node_rank, local_size, world_size):
# 初始化
rank = local_rank + node_rank * local_size
dist.init_process_group("nccl",
init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=rank,
world_size=world_size)
# 创建模型
model = nn.Linear(10, 10).to(rank)
# 放入DDP
ddp_model = DDP(model, device_ids=[local_rank],output_device=local_rank)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# 进行前向后向计算
for i in range(1000):
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
def main():
local_size = torch.cuda.device_count()
print("local_size: %s" % local_size)
mp.spawn(example,
args=(args.node_rank, local_size, args.world_size,),
nprocs=local_size,
join=True)
if __name__=="__main__":
main()
启动方式:
假设一共有两台机器(节点1和节点2),每个节点上有8张卡,节点1的IP地址为127.0.0.1 占用的端口22335(端口可以更换),启动的方式如下:
>>> #节点1
>>>python python demo.py --world_size=16 --node_rank=0 --master_addr="127.0.0.1" --master_port=22335
>>> #节点2
>>>python python demo.py --world_size=16 --node_rank=2 --master_addr="127.0.0.1" --master_port=22335
2.2.2 方式二:单个进程占用多张卡
进一步,看单进程多卡的代码和启动方式,代码中需要注意的位置:
- dist.init_process_group里面的rank等于节点编号;
- world_size等于节点的总数量;
- DDP不需要指定device。
示例代码
import torchvision
from torchvision import transforms
import torch.distributed as dist
import torch.utils.data.distributed
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--rank", default=0, type=int)
parser.add_argument("--world_size", default=1, type=int)
parser.add_argument("--master_addr", default="127.0.0.1", type=str)
parser.add_argument("--master_port", default="12355", type=str)
args = parser.parse_args()
def main(rank, world_size):
# 一个节点就一个rank,节点的数量等于world_size
dist.init_process_group("gloo",
init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=rank,
world_size=world_size)
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.MNIST('~/DATA/', train=True,
transform=trans, target_transform=None, download=True)
train_sampler = torch.utils.data.distributed.DistributedSampler(data_set)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set,
batch_size=256,
sampler=train_sampler,
num_workers=16,
pin_memory=True)
net = torchvision.models.resnet101(num_classes=10)
net.conv1 = torch.nn.Conv1d(1, 64, (7, 7), (2, 2), (3, 3), bias=False)
net = net.cuda()
# net中不需要指定设备!
net = torch.nn.parallel.DistributedDataParallel(net)
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=0.001)
for epoch in range(1):
for i, data in enumerate(data_loader_train):
images, labels = data
images, labels = images.cuda(), labels.cuda()
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
if i % 10 == 0:
print("loss: {}".format(loss.item()))
if __name__ == '__main__':
main(args.rank, args.world_size)
启动方式
>>> #节点1
>>>python python demo.py --world_size=16 --node_rank=0 --master_addr="127.0.0.1" --master_port=22335
>>> #节点2
>>>python python demo.py --world_size=16 --node_rank=2 --master_addr="127.0.0.1" --master_port=22335
2.2.3 方式三:利用launch
从torch.distributed.launch的源码,可以看出launch实际上主要完成的工作:
1、参数定义与传递。解析环境变量,并将变量传递到子进程中。
2、起多进程。调用subprocess.Popen启动多进程。
用launch方式需要注意的位置:
需要添加一个解析 local_rank的参数:
parser.add_argument("–local_rank", type=int)
dist初始化的方式 int_method取env:
dist.init_process_group(“gloo”, init_method=‘env://’)
DDP的设备都需要指定local_rank
net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[args.local_rank], output_device=args.local_rank)
示例代码: MNIST.py
import torch
import torchvision
import torch.utils.data.distributed
import argparse
import torch.distributed as dist
from torchvision import transforms
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int) # 增加local_rank
args = parser.parse_args()
torch.cuda.set_device(args.local_rank)
def main():
dist.init_process_group("nccl", init_method='env://') # init_method方式修改
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.MNIST('~/DATA/', train=True,
transform=trans, target_transform=None, download=True)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set,
batch_size=256,
sampler=train_sampler,
num_workers=16,
pin_memory=True)
net = torchvision.models.resnet101(num_classes=10)
net.conv1 = torch.nn.Conv1d(1, 64, (7, 7), (2, 2), (3, 3), bias=False)
net = net.cuda()
# DDP 输出方式修改:
net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[args.local_rank],
output_device=args.local_rank)
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=0.001)
for epoch in range(1):
for i, data in enumerate(data_loader_train):
images, labels = data
# 要将数据送入指定的对应的gpu中
images.to(args.local_rank, non_blocking=True)
labels.to(args.local_rank, non_blocking=True)
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
if i % 10 == 0:
print("loss: {}".format(loss.item()))
if __name__ == "__main__":
main()
启动方式: 假设一共有两台机器(节点1和节点2),每个节点上有8张卡,节点1的IP地址为192.168.1.1 占用的端口12355(端口可以更换),启动的方式如下:
>>> #节点1
>>>python -m torch.distributed.launch --nproc_per_node=8
--nnodes=2 --node_rank=0 --master_addr="192.168.1.1"
--master_port=12355 MNIST.py
>>> #节点2
>>>python -m torch.distributed.launch --nproc_per_node=8
--nnodes=2 --node_rank=1 --master_addr="192.168.1.1"
--master_port=12355 MNIST.py
上例子中,如果只要启动一台机器,只需要将nnodes数量改为1,就是单机多卡的另一种方式。设置如下:
>>> #节点1
>>>python -m torch.distributed.launch --nproc_per_node=8
--nnodes=1 --node_rank=0 --master_addr="192.168.1.1"
--master_port=12355 MNIST.py
原文首发于:PyTorch分布式训练基础–DDP使用
参考:
https://developer.nvidia.com/nccl
https://pytorch.apachecn.org/docs
https://pytorch.org/docs/stable/distributed.html#launch-utility
https://pytorch.org/docs/master/notes/ddp.html
https://discuss.pytorch.org/t/cuda-error-out-of-memory-when-load-models/38011